K-Means聚类算法的目标是找到一个由k个聚类中心构成的集合,使得所有样本点到距其最近的聚类中心之间的距离之和最小。为避免引起歧义,这里解释一下,目标函数中距离的个数等于样本点的个数,并且每个距离都是该样本点到距其最近的聚类中心的距离。k-means聚类是一种经典的聚类算法,其诞生时间距今已有数十年,在很多机器学习库中都有相应的实现。过去几年中,k-means也用于机器学习的多个领域中,比如表示学习 (Coates, Lee,and Ng; Coates and Ng, 2011; 2012) 和贝叶斯非参学习 (Kulis and Jordan, 2012).
K-Means聚类算法对初始聚类中心非常敏感,比较经典的解决方案是通过k-means++来获得初始的聚类中心集合。k-means++初始化聚类中心采用了一种自适应采样策略,首先,从样本集合中以均匀分布的方式随机选取一个聚类中心,然后,每次迭代过程中,基于概率选择一个新的聚类中心,这里的概率跟该聚类中心到已选聚类中心的距离成正比。然而, k-means++需要k个完整通道,复杂度是O(nkd),其中 n 是样本点的个数, k 是聚类中心的个数, d是样本点的维数,这就对将其用于大规模数据集造成了限制。瑞士苏黎世联邦理工大学的学者(Bachem, O. et al. 2016)为了解决这个问题,提出了一种简单高效的初始化k-means聚类的算法。其主要思想是将k-means++中的采样方法替换为一种基于马尔科夫链蒙特卡洛采样方法的更快速的近似方法。作者给出了证明,对数据集的自然假设成立的前提下,提出的算法不仅延续了k-means++的理论依据,而且计算复杂度是样本点的亚线性函数。
算法伪代码如下:

实验数据集如下:
USGS (United States Geological Survey, 2010),
CSN (Faulkner et al., 2011),
KDD (KDD Cup, 2004),
BIGX (Ackermann et al., 2012),
WEB (Yahoo! Labs, 2008) and
SONG (Bertin-Mahieux et al.,2011).
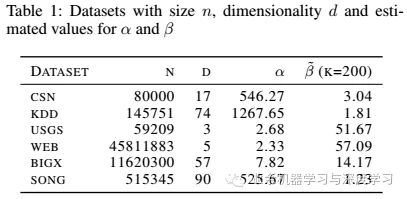
其中的α和β以及相关符号的具体表示如下:

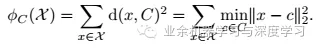
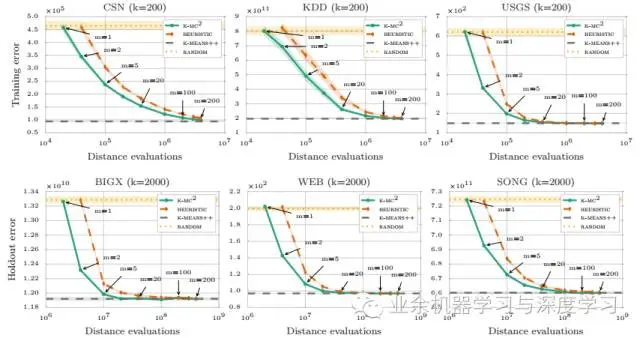
图一中m是马尔科夫链的长度。k-means||是k-means++的一种并行实现。

参考文献
Coates, A., and Ng, A. Y. 2012. Learning feature representations with k-means. In Neural Networks: Tricks of the Trade. Springer. 561–580.
Coates, A.; Lee, H.; and Ng, A. Y. 2011. An analysis of single-layer networks in unsupervised feature learning. In International Conference on Artificial Intelligence and
Statistics (AISTATS), volume 1001.
Kulis, B., and Jordan, M. I. 2012. Revisiting k-means: New algorithms via Bayesian nonparametrics. In International Conference on Machine Learning (ICML), 513–520.
Bachem, O., Lucic, M., Hassani, S. H., & Krause, A. (2016, February). Approximate k-means++ in sublinear time. In Conference on Artificial Intelligence (AAAI).
United States Geological Survey. 2010. Global Earthquakes (1.1.1972-19.3.2010). Retrieved from the mldata.org repository https://mldata.org/repository/
data/viewslug/global-earthquakes/.
Faulkner, M.; Olson, M.; Chandy, R.; Krause, J.; Chandy, K. M.; and Krause, A. 2011. The next big one: Detecting earthquakes and other rare events from community-based sensors. In ACM/IEEE International Conference on Information Processing in Sensor Networks.
KDD Cup. 2004. Protein Homology Dataset. Available at http://osmot.cs.cornell.edu/kddcup/datasets.html.
Ackermann, M. R.; Martens, M.; Raupach, C.; Swierkot, K.; Lammersen, C.; and Sohler, C. 2012. StreamKM++: A clustering algorithm for data streams. Journal of Experimental Algorithmics 17:2–4
Yahoo! Labs. 2008. R6A - Yahoo! Front Page Today Module User Click Log Dataset. Available at http://research.yahoo.com.
Bertin-Mahieux, T.; Ellis, D. P.; Whitman, B.; and Lamere,
P. 2011. The Million Song Dataset. In International Conference on Music Information Retrieval.
Bahmani, B.; Moseley, B.; Vattani, A.; Kumar, R.; and Vassilvitskii, S. 2012. Scalable k-means++. Very Large Data Bases (VLDB) 5(7):622–633.
