版本:IBM InfoSphere DataStage V11.5.1
操作系统:linux redhat 6.4
平台:Apache Hadoop 2.6.0-cdh5.9.0
问题描述:
1.APT_CombinedOperatorController,0: Fatal Error: Tsort mergeraborting: Scratch space full
2.APT_CombinedOperatorController,1: write failed: Output filefull, and no more output files
场景描述:
在执行主数据对比的时候,会用到Change_Capture ,该控件会把抽取数据存放到磁盘中,如果数据量大的话,会占用以下两个磁盘空间。
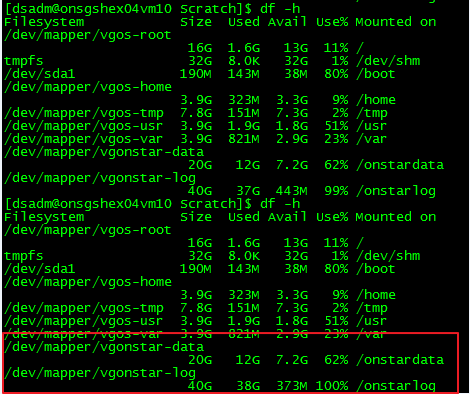
在Configurations 文件 default.apt 其中 resource disk 为磁盘 resourcescratchdisk 为暂存磁盘池 ,当如果执行作业完成,或者失败,该磁盘会自动释放空间。
APT configuration file:/onstarlog/IBM/InformationServer/Server/Configurations/default.apt
{
node "node1"
{
fastname"onsgshex04vm10"
pools ""
resource disk"/onstarlog/IBM/InformationServer/Server/Datasets" {pools""}
resource scratchdisk"/onstarlog/IBM/InformationServer/Server/Scratch" {pools""}
}
node "node2"
{
fastname"onsgshex04vm10"
pools ""
resource disk "/onstarlog/IBM/InformationServer/Server/Datasets"{pools ""}
resource scratchdisk"/onstarlog/IBM/InformationServer/Server/Scratch" {pools""}
}
}
解决办法:
1:增加该目录的磁盘大小
命令:
lvextend -L +5000m/dev/mapper/vgonstar-log
resize2fs/dev/mapper/vgonstar-log
2:直接加载数据入库,不需要做对比动作。(建议一千万的数据量就别做对比了。或者之对比特定范围的数据)
3:数据量大的话,最好不要用Lookup 因为Lookup 是会把数据放到内存中的。同时如果没必须的话,就不要对数据做排序动作了。
可参考:
https://www.ibm.com/support/knowledgecenter/zh/SSZJPZ_11.5.0/com.ibm.swg.im.iis.ds.trouble.ref.doc/topics/1444852.html

