
上一期为大家介绍了 Kaggle 的经典入门案例——泰坦尼克号(Titanic)幸存者预测,今天就为大家带来一个参考的解决方案,是 Kaggle 参赛者 Omar El Gabry 分享的 Kernel(得到 426 票支持,是该项目票数第二高的 Kernel),展现了一个大致的机器学习处理流程:如何处理缺失值、观察数据分布、挑选特征等等。
代码如下:
# 导入 package
# pandas 库
import pandas as pdfrom pandas
import Series,DataFrame
# numpy, matplotlib, seaborn 库
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style('whitegrid')
%matplotlib inline
# 机器学习库
from sklearn.linear_model
import LogisticRegression
from sklearn.svm import SVC, LinearSVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB# 把训练集和测试集读取为 DataFrame
titanic_df = pd.read_csv("../input/train.csv")
test_df = pd.read_csv("../input/test.csv")
# 预览数据
titanic_df.head()titanic_df.info()
print("----------------------------")
test_df.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KB
----------------------------
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 418 entries, 0 to 417
Data columns (total 11 columns):
PassengerId 418 non-null int64
Pclass 418 non-null int64
Name 418 non-null object
Sex 418 non-null object
Age 332 non-null float64
SibSp 418 non-null int64
Parch 418 non-null int64
Ticket 418 non-null object
Fare 417 non-null float64
Cabin 91 non-null object
Embarked 418 non-null object
dtypes: float64(2), int64(4), object(5)
memory usage: 36.0+ KB# 扔掉无用的列,它们对于分析与预测没用
titanic_df = titanic_df.drop(['PassengerId','Name','Ticket'], axis=1)
test_df = test_df.drop(['Name','Ticket'], axis=1)# Embarked 属性
# 在 titanic_df 中,用出现频率最高的值“S”来填补缺失值
titanic_df["Embarked"] = titanic_df["Embarked"].fillna("S")
# 绘图
sns.factorplot('Embarked','Survived', data=titanic_df,size=4,aspect=3)
fig, (axis1,axis2,axis3) = plt.subplots(1,3,figsize=(15,5))
sns.countplot(x='Embarked', data=titanic_df, ax=axis1)
sns.countplot(x='Survived', hue="Embarked", data=titanic_df, order=[1,0], ax=axis2)
# 按照 embarked 分组,获取幸存者的每一项指标的均值
embark_perc = titanic_df[["Embarked", "Survived"]].groupby(['Embarked'],as_index=False).mean()
sns.barplot(x='Embarked', y='Survived', data=embark_perc,order=['S','C','Q'],ax=axis3)
# 把 “Embarked” 列考虑进预测模型,并且去除“S”变量,留下“C”和“Q”,因为它们似乎存活几率更高
# 或者,不要为“Embarked” 列创建虚拟变量,直接扔掉它
# 因为从逻辑上说,“Embarked” 似乎对于预测没有帮助
embark_dummies_titanic = pd.get_dummies(titanic_df['Embarked'])
embark_dummies_titanic.drop(['S'], axis=1, inplace=True)
embark_dummies_test = pd.get_dummies(test_df['Embarked'])
embark_dummies_test.drop(['S'], axis=1, inplace=True)
titanic_df = titanic_df.join(embark_dummies_titanic)
test_df = test_df.join(embark_dummies_test)
titanic_df.drop(['Embarked'], axis=1,inplace=True)
test_df.drop(['Embarked'], axis=1,inplace=True)# Fare 属性
# 只针对 test_df,因为那里有一个缺失的“Fare”值
test_df["Fare"].fillna(test_df["Fare"].median(), inplace=True)
# 把 float 转换为 int
titanic_df['Fare'] = titanic_df['Fare'].astype(int)
test_df['Fare'] = test_df['Fare'].astype(int)
# 分别获取幸存的与没有幸存的乘客的票价
fare_not_survived = titanic_df["Fare"][titanic_df["Survived"] == 0]
fare_survived = titanic_df["Fare"][titanic_df["Survived"] == 1]
# 获取幸存者/罹难者的票价的平均值和标准差
avgerage_fare = DataFrame([fare_not_survived.mean(), fare_survived.mean()])
std_fare = DataFrame([fare_not_survived.std(), fare_survived.std()])
# 绘图
titanic_df['Fare'].plot(kind='hist', figsize=(15,3),bins=100, xlim=(0,50))
avgerage_fare.index.names = std_fare.index.names = ["Survived"]
avgerage_fare.plot(yerr=std_fare,kind='bar',legend=False)# Age 属性
fig, (axis1,axis2) = plt.subplots(1,2,figsize=(15,4))
axis1.set_title('Original Age values - Titanic')
axis2.set_title('New Age values - Titanic')
# 获取 titanic_df 的均值、标准差和 NaN 值的数量
average_age_titanic = titanic_df["Age"].mean()
std_age_titanic = titanic_df["Age"].std()
count_nan_age_titanic = titanic_df["Age"].isnull().sum()
# 获取 test_df 的均值、标准差和 NaN 值的数量
average_age_test = test_df["Age"].mean()
std_age_test = test_df["Age"].std()
count_nan_age_test = test_df["Age"].isnull().sum()
# 生成随机数,介于(均值 - 标准差) 和 (均值 + 标准差) 之间
rand_1 = np.random.randint(average_age_titanic - std_age_titanic, average_age_titanic + std_age_titanic, size = count_nan_age_titanic)
rand_2 = np.random.randint(average_age_test - std_age_test, average_age_test + std_age_test, size = count_nan_age_test)
# 绘制原始 Age 值的图像
# 注:舍弃所有 null 值,并且转化为 int 类型
titanic_df['Age'].dropna().astype(int).hist(bins=70, ax=axis1)
# 用随机数填补 Age 列中的空值
titanic_df["Age"][np.isnan(titanic_df["Age"])] = rand_1
test_df["Age"][np.isnan(test_df["Age"])] = rand_2
# 把 float 转换为 int
titanic_df['Age'] = titanic_df['Age'].astype(int)
test_df['Age'] = test_df['Age'].astype(int)
# 绘制新的 Age 值图像
titanic_df['Age'].hist(bins=70, ax=axis2)# 幸存者/罹难者年龄分布峰值
facet = sns.FacetGrid(titanic_df, hue="Survived",aspect=4)
facet.map(sns.kdeplot,'Age',shade= True)
facet.set(xlim=(0, titanic_df['Age'].max()))
facet.add_legend()
# 幸存者年龄分布均值
fig, axis1 = plt.subplots(1,1,figsize=(18,4))
average_age = titanic_df[["Age", "Survived"]].groupby(['Age'],as_index=False).mean()
sns.barplot(x='Age', y='Survived', data=average_age)# Cabin 属性
# 这里有大量的缺失值,所以对于预测结果不会产生很大影响
titanic_df.drop("Cabin",axis=1,inplace=True)
test_df.drop("Cabin",axis=1,inplace=True)# Family 属性
# 与其保留 Parch(有父母或孩子) 和 SibSp(有兄妹或者配偶) 这两列内容,
# 不如就用一列来表示乘客是否有家庭,
# 如果有任何家庭成员(无论是父母,兄弟...)都有可能对存活几率产生影响
titanic_df['Family'] = titanic_df["Parch"] + titanic_df["SibSp"]
titanic_df['Family'].loc[titanic_df['Family'] > 0] = 1
titanic_df['Family'].loc[titanic_df['Family'] == 0] = 0
test_df['Family'] = test_df["Parch"] + test_df["SibSp"]
test_df['Family'].loc[test_df['Family'] > 0] = 1
test_df['Family'].loc[test_df['Family'] == 0] = 0
# 舍弃 Parch 和 SibSp 属性
titanic_df = titanic_df.drop(['SibSp','Parch'], axis=1)
test_df = test_df.drop(['SibSp','Parch'], axis=1)
# 绘图
fig, (axis1,axis2) = plt.subplots(1,2,sharex=True,figsize=(10,5))
sns.countplot(x='Family', data=titanic_df, order=[1,0], ax=axis1)
# 有/没有家庭成员的乘客的幸存情况
family_perc = titanic_df[["Family", "Survived"]].groupby(['Family'],as_index=False).mean()
sns.barplot(x='Family', y='Survived', data=family_perc, order=[1,0], ax=axis2)
axis1.set_xticklabels(["With Family","Alone"], rotation=0)# Sex 属性
# 可以看到,船上16岁以下的孩子存活的几率更高
# 所以,我们可以吧乘客分类为男性、女性和小孩
def get_person(passenger):
age,sex = passenger
return 'child' if age < 16 else sex
titanic_df['Person'] = titanic_df[['Age','Sex']].apply(get_person,axis=1)
test_df['Person'] = test_df[['Age','Sex']].apply(get_person,axis=1)
# 既然我们创建了 Person 属性,那么 Sex 属性就没有用了
titanic_df.drop(['Sex'],axis=1,inplace=True)
test_df.drop(['Sex'],axis=1,inplace=True)
# 为 Person 属性创建虚拟变量,并且舍弃 Male 因为它平均存活乘客数最低
person_dummies_titanic = pd.get_dummies(titanic_df['Person'])
person_dummies_titanic.columns = ['Child','Female','Male']
person_dummies_titanic.drop(['Male'], axis=1, inplace=True)
person_dummies_test = pd.get_dummies(test_df['Person'])
person_dummies_test.columns = ['Child','Female','Male']
person_dummies_test.drop(['Male'], axis=1, inplace=True)
titanic_df = titanic_df.join(person_dummies_titanic)
test_df = test_df.join(person_dummies_test)
fig, (axis1,axis2) = plt.subplots(1,2,figsize=(10,5))
sns.countplot(x='Person', data=titanic_df, ax=axis1)
# Person 中每一个类型(男性、女性、和小孩)的幸存者均值
person_perc = titanic_df[["Person", "Survived"]].groupby(['Person'],as_index=False).mean()
sns.barplot(x='Person', y='Survived', data=person_perc, ax=axis2, order=['male','female','child'])
titanic_df.drop(['Person'],axis=1,inplace=True)
test_df.drop(['Person'],axis=1,inplace=True)# Pclass 属性
sns.factorplot('Pclass','Survived',order=[1,2,3], data=titanic_df,size=5)
# 为 Pclass 属性创建虚拟变量,并且舍弃 Class_3 因为它平均存活乘客数最低
pclass_dummies_titanic = pd.get_dummies(titanic_df['Pclass'])
pclass_dummies_titanic.columns = ['Class_1','Class_2','Class_3']
pclass_dummies_titanic.drop(['Class_3'], axis=1, inplace=True)
pclass_dummies_test = pd.get_dummies(test_df['Pclass'])
pclass_dummies_test.columns = ['Class_1','Class_2','Class_3']
pclass_dummies_test.drop(['Class_3'], axis=1, inplace=True)
titanic_df.drop(['Pclass'],axis=1,inplace=True)
test_df.drop(['Pclass'],axis=1,inplace=True)
titanic_df = titanic_df.join(pclass_dummies_titanic)
test_df = test_df.join(pclass_dummies_test)# 定义训练集和测试集
X_train = titanic_df.drop("Survived",axis=1)
Y_train = titanic_df["Survived"]
X_test = test_df.drop("PassengerId",axis=1).copy()# Logistic 回归
logreg = LogisticRegression()
logreg.fit(X_train, Y_train)
Y_pred = logreg.predict(X_test)
logreg.score(X_train, Y_train)0.81032547699214363# 支持向量机(SVM)
svc = SVC()
svc.fit(X_train, Y_train)
Y_pred = svc.predict(X_test)
svc.score(X_train, Y_train)0.86083052749719413# 随机森林
random_forest = RandomForestClassifier(n_estimators=100)
random_forest.fit(X_train, Y_train)
Y_pred = random_forest.predict(X_test)
random_forest.score(X_train, Y_train)0.96520763187429859# K临近算法
knn = KNeighborsClassifier(n_neighbors = 3)
knn.fit(X_train, Y_train)
Y_pred = knn.predict(X_test)
knn.score(X_train, Y_train)0.82267115600448937# Gaussian 朴素贝叶斯
gaussian = GaussianNB()
gaussian.fit(X_train, Y_train)
Y_pred = gaussian.predict(X_test)
gaussian.score(X_train, Y_train)0.75982042648709314# 用 Logistic 回归方法获取每一个特征的关联系数
coeff_df = DataFrame(titanic_df.columns.delete(0))
coeff_df.columns = ['Features']
coeff_df["Coefficient Estimate"] = pd.Series(logreg.coef_[0])
# 预览
coeff_df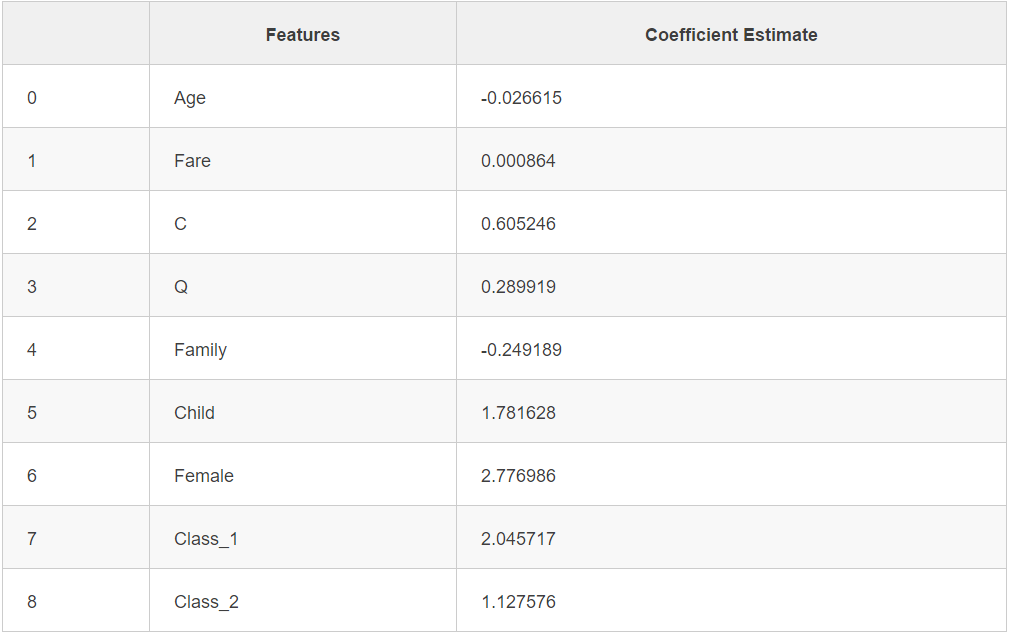
# 提交
submission = pd.DataFrame({
"PassengerId": test_df["PassengerId"],
"Survived": Y_pred
})
submission.to_csv('titanic.csv', index=False)好了,自己动手试试吧。 点击这里可以回顾关于本项目的介绍。
本站文章版权归原作者及原出处所有 。内容为作者个人观点, 并不代表本站赞同其观点和对其真实性负责。本站是一个个人学习交流的平台,并不用于任何商业目的,如果有任何问题,请及时联系我们,我们将根据著作权人的要求,立即更正或者删除有关内容。本站拥有对此声明的最终解释权。