

R中的dplyr包是我最喜欢的包之一(译者注:也是我的最爱),可以用来处理存储在内存和数据库中的数据。本文我会分享自己使用dplyr包来处理数据的经验,基本还敢数据处理的方方面面。关于dplyr包的基本函数Teja在DataScience+上传了另一篇文章进行了介绍。
如果需要处理的数据量很大,读入R中费时费力,这时使用dplyr包直接在数据库中处理数据会非常便利。我们可以把数据存储在数据库里,只把需要处理的子集读入R中进行处理。并且如果我们要处理很多数据文件,将数据存储在数据库中比起用CSV等格式存储会更安全,更易于处理。
plyr包是操作数据的利器。可以在不了解SQL的情况下,进行数据清洗,探索和特征工程等工作,它也提供了只在R中处理数据的方式。与其不同,dplyr包中的函数非常易读易写,它将数据表作为数据框处理,并使用惰性求值(延迟操作,只在真正需要的时候才从数据库中读入数据)原则。如果你对Spark很熟悉,你会发现二者在处理方式和很多函数上有不少相似之处。
dplyr包支持sqlite,mysql和pstgresql等数据库,本文中我将演示如何在sqlite库中进行操作。你可以从dplyr包的小品文中获取更多相关信息。
本文将继续使用FDA的不良事件数据(见“在R中使用SQL命令“译文),我们提取相关的病人、药物和服药指令等数据,把所有数据放在一个数据库里并使用dplyr包来处理这些数据。
你可以直接把下面的代码运行一遍,它会下载不良事件数据并合并不同类目下的数据,创建一个很大的数据集。为方便说明,我们使用2013-2015年的数据做演示。不良事件数据集是一个季度数据,每个类目的季度数据都被保存为一个数据文件。
加载R包
library(dplyr)
library(ggplot2)
library(data.table)
下载不良事件数据集
year_start=2013
year_last=2015
for (i in year_start:year_last){
j=c(1:4)
for (m in j){
url1<-paste0("http://www.nber.org/fda/faers/",i,"/demo",i,"q",m,".csv.zip")
download.file(url1,dest="data.zip") # 人口统计数据
unzip ("data.zip")
url2<-paste0("http://www.nber.org/fda/faers/",i,"/drug",i,"q",m,".csv.zip")
download.file(url2,dest="data.zip") # 药物数据
unzip ("data.zip")
url3<-paste0("http://www.nber.org/fda/faers/",i,"/reac",i,"q",m,".csv.zip")
download.file(url3,dest="data.zip") # 反应数据
unzip ("data.zip")
url4<-paste0("http://www.nber.org/fda/faers/",i,"/outc",i,"q",m,".csv.zip")
download.file(url4,dest="data.zip") # 结果数据
unzip ("data.zip")
url5<-paste0("http://www.nber.org/fda/faers/",i,"/indi",i,"q",m,".csv.zip")
download.file(url5,dest="data.zip") # 应对措施数据
unzip ("data.zip")
}
}
连接季度数据文件并对每个类目创建单个数据集
人口统计数据
filenames <- list.files(pattern="^demo.*.csv", full.names=TRUE)
demography = rbindlist(lapply(filenames, fread,
select=c("primaryid","caseid","age","age_cod","event_dt",
"sex","wt","wt_cod","occr_country"),data.table=FALSE))
str(demography)
'data.frame': 3037542 obs. of 9 variables:
$ primaryid : int 30375293 30936912 32481334 35865322 37005182 37108102 37820163 38283002 38346784 40096383 ...
$ caseid : int 3037529 3093691 3248133 3586532 3700518 3710810 3782016 3828300 3834678 4009638 ...
$ age : chr "44" "38" "28" "45" ...
$ age_cod : chr "YR" "YR" "YR" "YR" ...
$ event_dt : int 199706 199610 1996 20000627 200101 20010810 20120409 NA 20020615 20030619 ...
$ sex : chr "F" "F" "F" "M" ...
$ wt : num 56 56 54 NA NA 80 102 NA NA 87.3 ...
$ wt_cod : chr "KG" "KG" "KG" "" ...
$ occr_country: chr "US" "US" "US" "AR" ...
可以看到人口统计数据有超过300万行观测,变量则包括年龄,年龄代码,事件发生日期,性别,体重,体重代码和事件发生国家。
药物数据
filenames <- list.files(pattern="^drug.*.csv", full.names=TRUE)
drug = rbindlist(lapply(filenames, fread,
select=c("primaryid","drug_seq","drugname","route"
),data.table=FALSE))
str(drug)
'data.frame': 9989450 obs. of 4 variables:
$ primaryid: chr "" "" "" "" ...
$ drug_seq : chr "" "" "20140601" "U" ...
$ drugname : chr "" "" "" "" ...
$ route : chr "" "21060" "" "76273" ...
药物数据集有大概1000万的观测,变量包括药物名称和路径等。
诊断结果/反应特征
filenames <- list.files(pattern="^indi.*.csv", full.names=TRUE)
indication = rbindlist(lapply(filenames, fread,
select=c("primaryid","indi_drug_seq","indi_pt"
),data.table=FALSE))
str(indication)
'data.frame': 6383312 obs. of 3 variables:
$ primaryid : int 8480348 8480354 8480355 8480357 8480358 8480358 8480358 8480359 8480360 8480361 ...
$ indi_drug_seq: int 1020135312 1020135329 1020135331 1020135333 1020135334 1020135337 1020135338 1020135339 1020135340 1020135341 ...
$ indi_pt : chr "CONTRACEPTION" "SCHIZOPHRENIA" "ANXIETY" "SCHIZOPHRENIA" ...
该数据集有600多万个观测,变量有身份证ID,药物序列和反应特征。
事件结果
filenames <- list.files(pattern="^outc.*.csv", full.names=TRUE)
outcome = rbindlist(lapply(filenames, fread,
select=c("primaryid","outc_cod"),data.table=FALSE))
str(outcome)
'data.frame': 2453953 obs. of 2 variables:
$ primaryid: int 8480347 8480348 8480350 8480351 8480352 8480353 8480353 8480354 8480355 8480356 ...
$ outc_cod : chr "OT" "HO" "HO" "HO" ...
该数据集有2000多万观测,变量有省份证ID和最终结果。
针对事件的措施
filenames <- list.files(pattern="^reac.*.csv", full.names=TRUE)
reaction = rbindlist(lapply(filenames, fread,
select=c("primaryid","pt"),data.table=FALSE))
str(reaction)
'data.frame': 9288270 obs. of 2 variables:
$ primaryid: int 8480347 8480348 8480349 8480350 8480350 8480350 8480350 8480350 8480350 8480351 ...
$ pt : chr "ANAEMIA HAEMOLYTIC AUTOIMMUNE" "OPTIC NEUROPATHY" "DYSPNOEA" "DEPRESSED MOOD" ...
这是一个有约1000万观测,变量为身份证ID和事件应对措施的数据集。
创建数据库
要在R中创建一个SQLite数据库,我们只需要设定路径,使用src_sqlite()函数来连接R和现有的sqlite数据库,再用tbl()函数把数据表和该库连接在一起就大功告成了。我们也可以用src_sqlite()函数在特定路径下创建新的SQLite数据库,如果不额外指定路径,数据库将被创建于当前工作目录下。
my_database<- src_sqlite("adverse_events", create = TRUE)
# create =TRUE 该参数设定为创建新的数据库
将数据写入数据库
我们使用dplyr包中的copy_to()函数把数据上传到数据库。根据文档,新写入的对象可能只是一个临时文件,我们需要把temporary参数设定为false来使得新对象是永久文件。
#上传各个类目的数据至SQLite数据库
copy_to(my_database,demography,temporary = FALSE)
copy_to(my_database,drug,temporary = FALSE)
copy_to(my_database,indication,temporary = FALSE)
copy_to(my_database,reaction,temporary = FALSE)
copy_to(my_database,outcome,temporary = FALSE)
我已经把所有数据上传到了“不良事件”数据库中了,我现在可以访问这个库并做一些数据分析了。
连接到数据库
我们可以直接使用dplyr中的函数来操作数据,dplyr包会将我们的R代码转化为SQL代码。利用tbl()函数可以连接到数据库中的表格。
demography = tbl(my_db,"demography" )
class(demography)
tbl_sqlite" "tbl_sql" "tbl"
head(demography,3) 
US = filter(demography, occr_country=='US') # 过滤出发生在美国的不良事件数据
上述filter函数对应的SQL查询指令如下:
US = filter(demography, occr_country=='US') # 过滤出发生在美国的不良事件数据
US$query
SELECT "primaryid", "caseid", "age", "age_cod", "event_dt", "sex", "wt", "wt_cod", "occr_country"
FROM "demography"
WHERE "occr_country" = 'US'
我们也能看到数据库如何执行这个查询指令
explain(US)
SELECT "primaryid", "caseid", "age", "age_cod", "event_dt", "sex", "wt", "wt_cod", "occr_country"
FROM "demography"
WHERE "occr_country" = 'US'
selectid order from detail
1 0 0 0 SCAN TABLE demography
利用相似方法,连接到其他数据集
drug = tbl(my_db,"drug" )
indication = tbl(my_db,"indication" )
outcome = tbl(my_db,"outcome" )
reaction = tbl(my_db,"reaction" )
有意思的是dplyr包会延迟这些查询操作,只在我们需要数据的时候才把相应的对象加载到R中。即当我们使用诸如collect(), head(), count()等函数时,先前的查询指令才被执行。(译者注:也就是遵循惰性求值原则)
当我们对数据库中提取的数据进行tail()操作,程序会报错。因为只有当整个查询指令被执行完毕,我们才能找到数据表中的最后几行观测。
head(indication,3) 
tail(indication,3)
Error: tail is not supported by sql sources
对数据库中的表使用dplyr中的指令 (select, arrange, filter, mutate, summarize, rename)
我们可以利用magrittr包中的管道操作符%>%将不同指令连接起来。%>%符号会把左边的输出传递到右边的函数,作为右侧函数的第一个参数。
寻找不良事件发生最多的10个国家
demography%>%group_by(Country= occr_country)%>%
summarize(Total=n())%>%
arrange(desc(Total))%>%
filter(Country!='')%>% head(10) 
我们也可以在操作链中加入ggplot函数来对数据进行可视化
demography%>%group_by(Country= occr_country)%>% #按国家分组
summarize(Total=n())%>% # 找到每个国家的事件数
arrange(desc(Total))%>% # 按照降序对事件数排序
filter(Country!='')%>% # 把国家变量为空的观测删除
head(10)%>% # 找出前十名
mutate(Country = factor(Country,levels = Country[order(Total,decreasing =F)]))%>%
ggplot(aes(x=Country,y=Total))+geom_bar(stat='identity',color='skyblue',fill='#b35900')+
xlab("")+ggtitle('Top ten countries with highest number of adverse event reports')+
coord_flip()+ylab('Total number of reports') 
寻找最常见药物
drug%>%group_by(drug_name= drugname)%>% # 按照药物名分组
summarize(Total=n())%>% # 找到每组的事件发生数
arrange(desc(Total))%>% # 按照降序排序
head(1) # 找到频率最高的药物
最常见的5大事件结果
head(outcome,3) # 查看变量名
outcome%>%group_by(Outcome_code= outc_cod)%>% # 按结果代码分组
summarize(Total=n())%>% # 找到每组的事件发生数
arrange(desc(Total))%>% # 按照降序排序
head(5) # 提出最前面的5个结果代码
前10大事件应对措施
head(reaction,3) # to see the variable names
reaction%>%group_by(reactions= pt)%>% # 按应对措施分组
summarize(Total=n())%>% # 找到每组的事件发生数
arrange(desc(Total))%>% # 按照降序排序
head(10) # 提出最前面的5个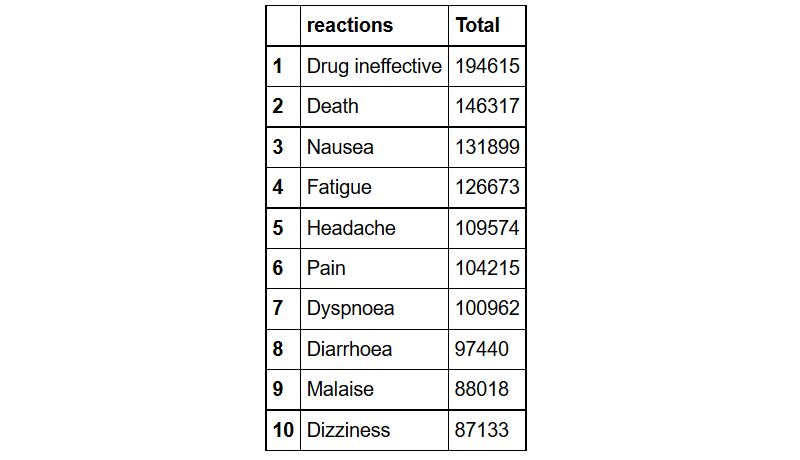
Joins(连接)
让我们把人口统计数据,结果数据和应对数据利用身份证ID做主键连接起来:
inner_joined = demography%>%inner_join(outcome, by='primaryid',copy = TRUE)%>%
inner_join(reaction, by='primaryid',copy = TRUE)
head(inner_joined) 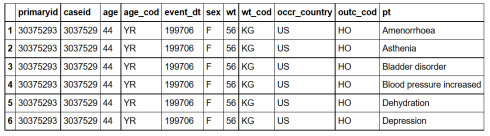
我们也可以设定在连接时设定主键和第二主键。让我们把药物和反应特征数据利用两个键连接起来。
drug_indication= indication%>%rename(drug_seq=indi_drug_seq)%>%
inner_join(drug, by=c("primaryid","drug_seq"))
head(drug_indication) 
通过本文,我们演示了如何利用dplyr包来创建数据库并上传数据。我们还演示了如何查询数据库中的数据,并进行一系列分析操作。
在R中使用数据库有不少优势,尤其在数据量很大,直接读入R中进行分析效率很低时。如果把数据存储在数据库中,而不是直接加载到R中,我们可以只对我们感兴趣的部分数据进行操作。更进一步,假若我们有多个数据文件,把数据存在数据库中,而不是使用csv或其他格式保存,数据的存贮的安全性和可操作性会更高。
注:原文刊载于datascience+网站
链接:Working with databases in R
本站文章版权归原作者及原出处所有 。内容为作者个人观点, 并不代表本站赞同其观点和对其真实性负责。本站是一个个人学习交流的平台,并不用于任何商业目的,如果有任何问题,请及时联系我们,我们将根据著作权人的要求,立即更正或者删除有关内容。本站拥有对此声明的最终解释权。