

第6章 基本图形
本章内容:
- 条形图、箱线图、点图
- 饼图和扇形图
- 直方图和核密度图
6。1 条形图
条形图通过垂直的或水平的条形展示了类别型变量的分布(频数)。函数barplot()的用法:
barplot(height)
其中,height是一个向量或者矩阵。
我们安装vcd包,是为了使用Arthritis数据集。
6。1。1简单的条形图
下面的示例,数据包含在vcd包分发的Arthritis数据框中。
在关节炎的研究中,变量Improved记录了对每位接受了安慰剂或药物治疗的病人的治疗结果:
> library(vcd)
> counts<-table(Arthritis$Improved)
> counts
None Some Marked
42 14 28
分析:我们看到,28个病人marked,14人部分改善,42人未改善。
我们使用条形图来绘制变量counts
代码6-1 简单的条形图
#简单条形图
barplot(counts,main="Simple Bar Plot",xlab = "Improvement",ylab="Frequency") 
#水平条形图
barplot(counts,main="Horizontal Bar Plot",xlab = "Frequency",ylab="Improvement",horiz=TRUE) 
生成因素变量的条形图
在无需使用table()函数将数据框Arthritis 表格化的时候,怎么才能实现呢?
如果要绘制的类别变量是一个因子或有序因子,我们可以使用函数plot()来创建垂直条形图,而无需使用table()函数将数据框Arthritis 表格化。因为Arthritis$Improved是因子。
代码:
plot(Arthritis$Improved,main="Simple Bar Plot",xlab="Improved",ylab="Frequency")
plot(Arthritis$Improved,horiz=TRUE,main="Simple Bar Plot",xlab="Improved",ylab="Frequency")
6.1.2 堆砌条形图和分组条形图
若height是一个矩阵而非向量。绘图结果就是一幅堆砌条形图或分组条形图。
若beside=FALSE(默认值)。
矩阵中每一列都将生成图中的一个条形,各列中的值将给出堆砌的”子条“的高度。
若beside=TRUE。
矩阵中每一列都表示一个分组,各列中的值将并列。
考虑治疗类型和改善情况的列联表:
代码6-2 堆砌条形图和分组条形图
> library(vcd)
> counts<-table(Arthritis$Improved,Arthritis$Treatment)
> counts
Placebo Treated
None 29 13
Some 7 7
Marked 7 21
#堆砌条形图
> barplot(counts,main="Stacked Bar Plot",xlab="Treatment",ylab="Frequency",col = c("red","yellow", 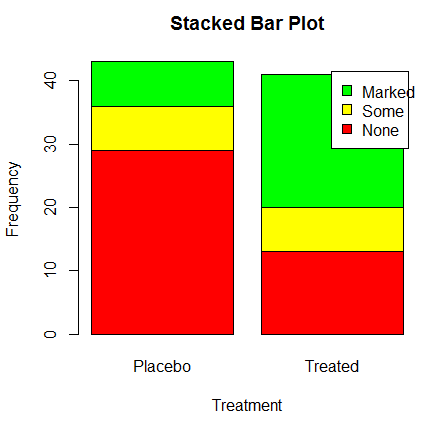
#分组条形图
> barplot(counts,main="Grouped Bar Plot",xlab="Treatment",ylab="Frequency",col = c("red","yellow","green"),legend=rownames(counts),beside = TRUE) 
分析:col选项添加了三种颜色。
参数legend.text为图例提供了各条形的标签(只在height为矩阵时候有用)
6。1。3均值条形图
可以使用数据整合函数将数据结果传递给barplot()函数,来创建均值、中位数、标准差等条形图。
代码6-3 排序后的条形图
>options(digits = 3)
> states<-data.frame(state.region,state.x77)
> means<-aggregate(states$Illiteracy,by=list(state.region),FUN=mean)
> means
Group.1 x
1 Northeast 1.00
2 South 1.74
3 North Central 0.70
4 West 1.02
#将均值从小到大排列
> means<-means[order(means$x),]
> means
Group.1 x
3 North Central 0.70
1 Northeast 1.00
4 West 1.02
2 South 1.74
> barplot(means$x,names.arg = means$Group.1)
> title("Mean Illiteracy Rate") #添加标题
美国各地区平均文盲率的排序条形图

分析:
使用title()函数与调用plot()时添加main选项等价。
mean$x 是包含各条形高度的向量,而添加项names.arg=means$Group.1是为了展示标签。
6。1。4 条形图的微调
参数cex.names 来减少字号
参数names.arg允许指定一个字符向量作为条形的标签名。
代码6-4 位条形图搭配标签
#增加y边界大小
par(mar=c(5,8,4,2))
#旋转条形标签
par(las=2)
counts<-table(Arthritis$Improved)
barplot(counts,main = "Threatment Outcome",horiz=TRUE,
cex.names = 0.8, #缩小字体,让标签更合适
names.arg = c("No Improvement","Some Improvement","Marked Improvement")) #修改标签文本 
6。1。5棘状图(spinogram)
棘状图对堆砌条形图进行了重缩放,使每个条形高度为1,每一段的高度即表示比例。
棘状图由vcd()包中的函数spine()函数绘制。
library(vcd)
attach(Arthritis)
counts<-table(Treatment,Improved)
spine(counts,main = "Spinogram Example")
detach(Arthritis)
关节炎的治疗效果棘状图

6.2饼图
饼图由由以下函数创建:
pie(x,labels)
其中,x是一个非负向量,表示每个扇形的面积
labels是表示各扇形标签的字符型向量
代码6-5 饼图
#将四幅图组合成一幅图
par(mfrow=c(2,2))
slices<-c(10,12,4,16,8)
lbls<-c("US","UK","Australia","Germany","France")
pie(slices,labels = lbls,main="Simple Pie Chart")
#为饼图添加数值
pct<-round(slices/sum(slices)*100)
lbls2<-paste(lbls," ",pct,"%",sep=" ")
pie(slices,labels = lbls2,col = rainbow(length(lbls2)),main = "Pie Chart with Percentages")
library(plotrix)
pie3D(slices,labels=lbls,explode=0.1,main="3D Pie Chart")
#从表格创建饼图
mytable<-table(state.region)
lbls3<-paste(names(mytable),"\n",mytable,sep=" ")
pie(mytable,labels = lbls3,main="Pie Chart from a Table\n (with sample sizes)")
分析:
- rainbow()函数定义了各扇形的颜色。这里的rainbow(length(lbls2))将被解析为rainbow(5),也就是为图形提供5中颜色
- plotrix()包中的pie3D()函数用来创建的三维饼图。
- 第四个图演示了如何从表格创建饼图。
饼图其实让各个扇形的图的比较变得更困难,我们创造了扇形图(fan plot)
在R中,扇形图是通过plotrix 包中的fan.plot()函数实现的。
代码:
library(plotrix)
slices<-c(10,24,4,16,8)
lbls<-c("US","UK","Australia","Germany","France")
fan.plot(slices,labels = lbls,main = "Fan Plot") 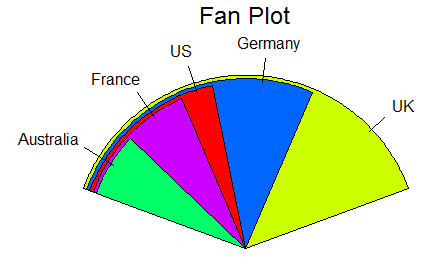
6.3 直方图
如下函数创建直方图:
hist(x)
x是一个由数据值组成的数值向量。参数freq=FALSE表示根据概率密度而不是频数绘制的图形。
参数breaks用于控制组的数量。
代码6-6 直方图
#将四幅图组合为一幅图
par(mfrow=c(2,2))
#简单直方图
hist(mtcars$mpg)
#指定将组数指定为12,红色填充,添加标签
hist(mtcars$mpg,breaks = 12,col="red",xlab = "Miles Per Gallon",main = "Colored histogram with 12 bins")
#保留第二幅图的颜色、组数、标签、标题设置。又叠加了一条密度曲线和轴须图
hist(mtcars$mpg,freq = FALSE,breaks = 12,col="red",xlab="Miles Per Gallon",main = "Histogram,rug plot,density curve")
rug(jitter(mtcars$mpg)) #轴须图的数据有许多结,使用代码将轴须图的数据打散。
lines(density(mtcars$mpg),col="blue",lwd=2)
#下面整个代码添加正态密度曲线和外框
x<-mtcars$mpg
h<-hist(x,breaks = 12,col="red",xlab = "Miles Per Gallon",main="Histogram with normal curve and box")
xfit<-seq(min(x),max(x),length=40)
yfit<-dnorm(xfit,mean = mean(x),sd=sd(x))
yfit<-yfit*diff(h$mids[1:2])*length(x)
lines(xfit,yfit,col="blue",lwd=2)
box() 
分析:
- 第一幅直方图是未指定任何选项时的默认图形。
- 第二个直方图指定将组数指定为12。
- 第三幅图又叠加一条密度曲线和轴须图。
- 第四幅图有一条叠加在上面的正态曲线和一个将图形围绕起来的盒型。
6。4 核密度图
和密度估计是用于估计随机变量概率密度函数的一种非参数的方法。
语法:
plot(density(x))
x是一个数值型向量。
plot()函数会创建一幅新的图形,向一幅已经存在的图形上叠加一条密度曲线。可以使用lines()函数
代码6-7 核密度图
par(mfrow=c(2,1))
d<-density(mtcars$mpg)
#完全使用默认设置创建最简图形
plot(d)
d<-density(mtcars$mpg)
#添加一个标题
plot(d,main = "Kernel Density of Miles Per Gallon")
#将曲线修改为蓝色,并使用实心红色填充曲线下方的区域
polygon(d,col = "red",border = "blue")
#添加棕色的轴须图
rug(mtcars$mpg,col = "brown") 
polygon()函数根据顶点的x和y坐标绘制了多边形。
核密度图用于比较组间的差距,sm包可以满足这个要求。
sm包中的sm.density.compare(x,factor)
其中,x是一个数值型向量,factor是一个分组变量。
代码6-8 可比较的核密度图
library(sm)
attach(mtcars) #绑定数据框mtcars
#创建分组因子
cyl.f<-factor(cyl,levels = c(4,6,8),labels=c("4 cylinder","6 cylinder","8 cylinder"))
#绘制密度图
sm.density.compare(mpg,cyl,xlab="Miles Per Gallon")
title(main="MPG Distribution by Car Cylinders")
#通过鼠标单击图形在任意位置添加图例
colfill<-c(2:(1+length(levels(cyl.f))))
legend(locator(1),levels(cyl.f),fill = colfill)
detach(mtcars) 
分析:
- 变量cyl是一个以4、6、8编码的数值型变量。为了向图形提供值的标签,cyl转换为cyl.f的因子。函数sm.density.compare()创建了图形,一条title()语句添加了主标题。
- title()添加主标题
- 创建颜色向量,colfill值为c(2,3,4),通过legend()函数向图形添加一个人图例。
- 参数值locator(1)表示用鼠标点击想让图例出现的位置任意。
- levels(cyl.f)由标签组成的字符向量。
- 参数fill = colfill使用colfill为cyl.f的每一个水平指定了一种颜色。
6。5 箱线图
箱线图是一项用来可视化和组间差异的绝佳图形手段。
箱线图通过绘制连续型变量的五数总括:最小值、下四分位数(第25百分位数)、中位数(第50百分位数)、上四分位数(第75百分位数),描述了连续型变量的分布。
代码:
boxplot(mtcars$mpg,main="Box plot",ylab="Miles per Gallon") 
6。5。1 使用并列箱线图进行跨组比较
箱线图可以展示单个变量或分组变量。格式:
boxplot(formula,data=dataframe)
formula 是一个公式,比如,y~A*B将为类别型变量A和B的所有水平的两两组合生成的数值型变量y的箱线图。
参数varwidth=TRUE将使箱线图的宽度与其样本的大小的平方根成正比。
参数horizontal=TRUE可以反转坐标轴的方向。
boxplot(mpg~cyl,data=mtcars,main="Car Mileage Data",xlab="Number of Cylinders","ylab=Miles Per 
上图看出不同的组间的油耗的区别非常明显。
参数notch=TRUE,可以得到含有凹槽的箱线图。
boxplot(mpg~cyl,data=mtcars,notch=TRUE,varwidth=TRUE,col="red",main="Car Mileage Data",xlab="Numbe 
不同的汽缸数量车型油耗的含凹槽箱线图。
代码6-9 两个交叉因子的箱线图
#创建汽缸数量的因子
mtcars$cyl.f<-factor(mtcars$cyl,levels = c(4,6,8),labels = c("4","6","8"))
#创建变速箱类型的因子
mtcars$am.f<-factor(mtcars$am,levels = c(0,1),labels = c("auto","standard"))
#生成箱线图
boxplot(mpg~am.f*cyl.f,data=mtcars,varwidth=TRUE,col=c("gold","darkgreen"),main="MPG Distribution b 
6。5。2 小提琴图
小提琴图是箱线图与核密度图的结合。可以使用vioplot()包中的vioplot()函数绘制它。
使用格式:vioplot(x1,x2...,names=,col=)
其中,x1,x2...表示要绘制的一个或多个数值向量。参数names是小提琴图中标签的字符向量,col是指定颜色的向量。
代码6-10 小提琴图
library(vioplot)
x1<-mtcars$mpg[mtcars$cyl==4]
x2<-mtcars$mpg[mtcars$cyl==6]
x3<-mtcars$mpg[mtcars$cyl==8]
vioplot(x1,x2,x3,names=c("4 cyl","6 cyl","8 cyl"),col="gold")
title("Violin Plots of Miles Per Gallon",ylab="Miles Per Gallon",xlab="Number of Cylinders") 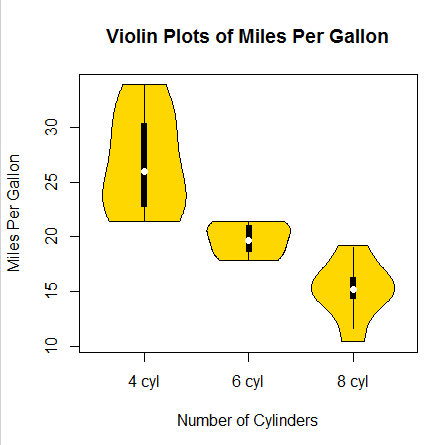
分析:
图中,白点是中位数;黑色盒型的范围是下四分位点到上四分位点。细黑线表示须。外部形状为核密度估计。
6。6点图
点图提供了一种在简单水平刻度上绘制大量有标签值的方法。
可以使用dotchart()函数来创建点图。格式:
dotchart(x,labels=)
其中,x为一个数值向量,labels是由每个点的标签组成的向量。可以通过添加参数groups来选定一个因子。cex可以控制标签的大小。
如:
dotchart(mtcars$mpg,labels = row.names(mtcars),cex=.7,main="Gas Mileage for Car Models",xlab="Mil 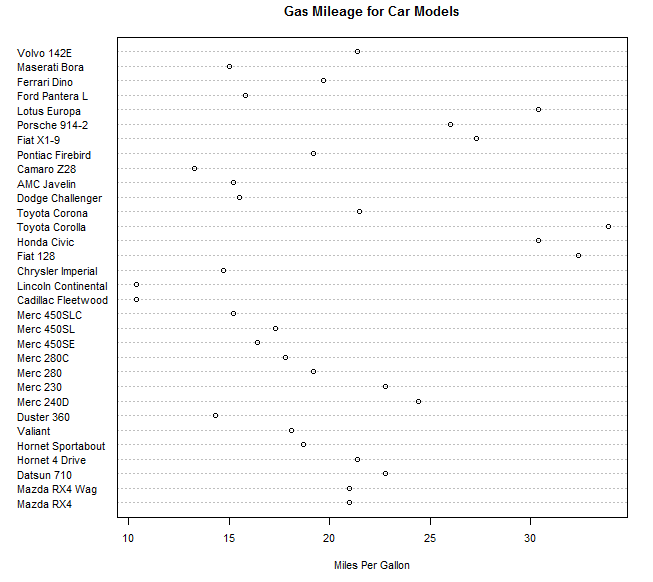
上图可以在同一个水平轴上观察每种车型的每加仑汽油行驶的英里数。
代码6-11 分组、排序、着色后的点图
#根据每加仑汽油行驶英里数对数据库进行排序,结果保存为数据框x
x<-mtcars[order(mtcars$mpg),]
#将数值向量cyl转换为一个因子
x$cyl<-factor(x$cyl)
#下面三行代码是添加一个字符型向量(color)到数据框x中,根据cyl的值,所含有的值为“red”、“blue”、"darkgreen"
x$color[x$cyl==4]<-"red"
x$color[x$cyl==6]<-"blue"
x$color[x$cyl==8]<-"darkgreen"
#各数据点的标签取自数据框的行名
dotchart(x$mpg,labels=row.names(x),cex=.7,groups=x$cyl,gcolor="black",color=x$color,pch=19,ma 