在第一部分 中,我们从goodreads网站爬取了评论数据. 并在第二部分完成了探索性数据分析,同时还生成了一些新变量. 现在可以上主菜了:机器学习!(此处应有BGM)
准备工作
先来加载包并读入数据
library(data.table)
library(dplyr)
library(caret)
library(RTextTools)
library(xgboost)
library(ROCR)
setwd("C:/Users/Florent/Desktop/Data_analysis_applications/GoodReads_TextMining")
data <- read.csv("GoodReadsCleanData.csv", stringsAsFactors = FALSE)
目前,数据集包含如下变量:
review.id
book
rating
review
review.length
mean.sentiment
median.sentiment
count.afinn.positive
count.afinn.negative
count.bing.negative
count.bing.positive
方便起见,本例把1-5星的评级简化为二分变量,4或5星为1,星以下为0。这样我们就可以在这个数据集上训练分类器了,并且两个类比例也比较均衡。
set.seed(1234)
# Creating the outcome value
data$good.read <- 0
data$good.read[data$rating == 4 | data$rating == 5] <- 1
数据集中的好评占了约85%,差评约15%,是个非常典型的非平衡数据集。我们在划分训练集和测试集的时候就不能采用简单抽样了,我们要用caret包中的‘createDatePartITion()’函数进行分层抽样来保证划分的两部分依旧保留有之前的比例结构。
trainIdx <- createDataPartition(data$good.read,
p = .75,
list = FALSE,
times = 1)
train <- data[trainIdx, ]
test <- data[-trainIdx, ]
构造文献-检索词矩阵(DTM)
我们的目标是将评论中每个词的词频作为机器学习算法的输入特征,为此,我们要从统计每条评论中每个单词的出现次数开始。幸运的是,现在已经有现成的工具可以为我们返回文献-检索词矩阵了。这个矩阵的行代表评论,列代表一个词,而矩阵的每个元素则表示该次在这条评论中的出现次数。
一个典型的DTM长这样:
我们并不希望把每个单词都统计频率,因为很多生僻词对预测而言没什么用,只是徒增DTM的大小。所以DTM中只包含出现频率高于某一水平(比如1%)的词,通过设定函数中的'sparsity'参数就能达成这一目的,此处sparsity = 1-0.01 = 0.99.
然而问题来了,我们的前提假定是在差评中出现的词在好评中往往不会出现(至少频率差别很大),反之亦然。可如果我们只保留出现频率大于1%的词,由于差评整体只占15%,那么一个贬义词要被纳入DTM,它出现的频率至少是‘1%/15% = 6.67%’。这个门限值实在太高了,并不可行。
相对的解决方案就是对于训练集创建两个不同的DTM,分别统计褒义词和贬义词,再将两者整合到一起。这样一来,两边的门限值就都是1%了。
# 创建贬义词的DTM
sparsity <- .99
bad.dtm <- create_matrix(train$review[train$good.read == 0],
language = "english",
removeStopwords = FALSE,
removeNumbers = TRUE,
stemWords = FALSE,
removeSparseTerms = sparsity)
# 把DTM转换为数据框
bad.dtm.df <- as.data.frame(as.matrix(bad.dtm),
row.names = train$review.id[train$good.read == 0])
# 创建褒义词的DTM
good.dtm <- create_matrix(train$review[train$good.read == 1],
language = "english",
removeStopwords = FALSE,
removeNumbers = TRUE,
stemWords = FALSE,
removeSparseTerms = sparsity)
good.dtm.df <- data.table(as.matrix(good.dtm),
row.names = train$review.id[train$good.read == 1])
# 合并两个数据框
train.dtm.df <- bind_rows(bad.dtm.df, good.dtm.df)
train.dtm.df$review.id <- c(train$review.id[train$good.read == 0],
train$review.id[train$good.read == 1])
train.dtm.df <- arrange(train.dtm.df, review.id)
train.dtm.df$good.read <- train$good.read
我们也希望在分析中用上之前整合的变量,比如评论长度、情感均值和中位数等等,为此我们将DTM和训练集以评论id为主键再次合并。我们还需要把所有NA值转变为0,因为它们表示这些词在评论中没有出现。
train.dtm.df <- train %>%
select(-c(book, rating, review, good.read)) %>%
inner_join(train.dtm.df, by = "review.id") %>%
select(-review.id)
train.dtm.df[is.na(train.dtm.df)] <- 0
# 创建测试集的DTM
test.dtm <- create_matrix(test$review,
language = "english",
removeStopwords = FALSE,
removeNumbers = TRUE,
stemWords = FALSE,
removeSparseTerms = sparsity)
test.dtm.df <- data.table(as.matrix(test.dtm))
test.dtm.df$review.id <- test$review.id
test.dtm.df$good.read <- test$good.read
test.dtm.df <- test %>%
select(-c(book, rating, review, good.read)) %>%
inner_join(test.dtm.df, by = "review.id") %>%
select(-review.id)
问题由来了,我们要确保测试集和训练集有一样的列,但显而易见,测试集的一些词在训练集里肯定没出现,不过我们对此无能为力。好在data.table对象在按行合并时会默认保留所有的列,那些缺失的值就会被认为是NA,那么我们只要对训练集添加一个辅助行,让它的列增多,再把该辅助行删除,就能使其和测试集保持列一致了。之后,再通过筛选,使得测试集只保留和训练集一样的列,也即删去那些只在测试集中出现的列。
test.dtm.df <- head(bind_rows(test.dtm.df, train.dtm.df[1, ]), -1)
test.dtm.df <- test.dtm.df %>%
select(one_of(colnames(train.dtm.df)))
test.dtm.df[is.na(test.dtm.df)] <- 0
至此,准备工作就差不多了,抡模型吧!
机器学习
我们将使用XGboost(本文在此跪拜下天奇大神,感谢你拯救了我的数模),因为它输出的结果最好(我也适用了随机森林和支持向量机,但它们的精度太不稳定了)。
我们先计算下基准精度,也就是预测所有测试样本为训练集中频率高的那一类,然后再上模型。
baseline.acc <- sum(test$good.read == "1") / nrow(test)
XGB.train <- as.matrix(select(train.dtm.df, -good.read),
dimnames = dimnames(train.dtm.df))
XGB.test <- as.matrix(select(test.dtm.df, -good.read),
dimnames=dimnames(test.dtm.df))
XGB.model <- xgboost(data = XGB.train,
label = train.dtm.df$good.read,
nrounds = 400,
objective = "binary:logistic")
XGB.predict <- predict(XGB.model, XGB.test)
XGB.results <- data.frame(good.read = test$good.read,
pred = XGB.predict)
XGboost算法会给出一个预测概率,所以我们需要制定一个门限值作为两个类别的划分界点。为此,我们将绘制出ROC(Receiver Operating Characteristic)曲线,该曲线纵轴是真阴性比率,横轴是假阴性比率。
ROCR.pred <- prediction(XGB.results$pred, XGB.results$good.read)
ROCR.perf <- performance(ROCR.pred, 'tnr','fnr')
plot(ROCR.perf, colorize = TRUE)
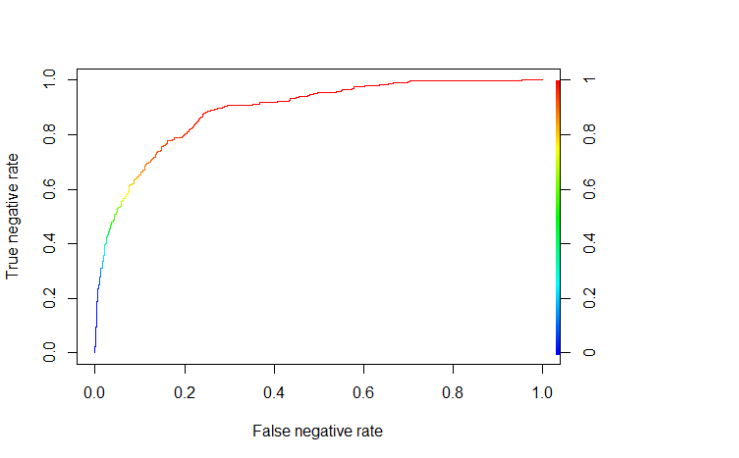
看起来不错!图中显示如果以0.8作为门限值(红线以上部分),我们能分对50%以上的负样本(真阴性比率)同时只把少于10%的正样本误分类(假阴性比率)。
XGB.table <- table(true = XGB.results$good.read,
pred = as.integer(XGB.results$pred >= 0.80))
XGB.table
XGB.acc <- sum(diag(XGB.table)) / nrow(test)
我们整体的精度是87%,因此我们击败了基准精度(一直预测测试样本为正类,分类正确率是83.4%),能够捕捉61.5%的差评。对于一个黑箱算法而言不算坏,毕竟我们没做任何的参数优化或者特征工程!
未来的分析方向
如果要做更深入的分析,以XGboost的特征相对重要性为切入点是个不错的方向。
### XGboost中的特征分析
names <- colnames(test.dtm.df)
importance.matrix <- xgb.importance(names, model = XGB.model)
xgb.plot.importance(importance.matrix[1:20, ])
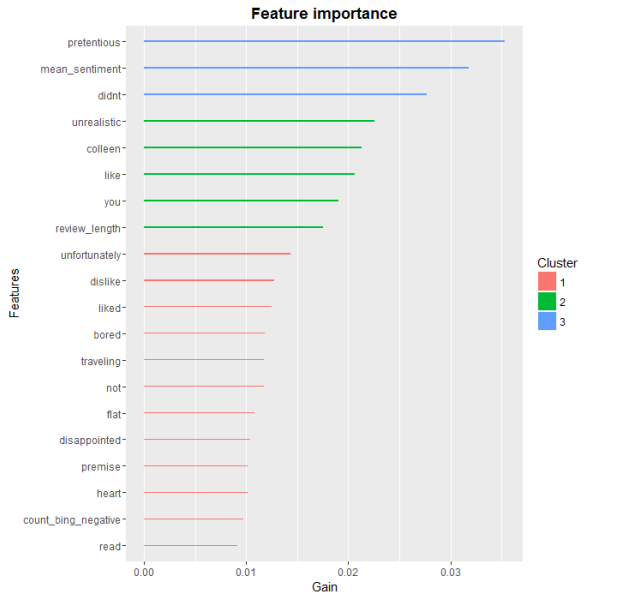
如图,诸如‘colleen’或者‘you'之类的词看起来用处不大,全局来看,最优解释效力是那些贬义词。而评论长度和通过bing词典统计的贬义词频书也进入了重要特征的前10名。
基于此,有如下方式可以提升模型:
结论
本系列我们介绍了很多内容:从网页数据抓取到情感分析再到利用机器学习模型做预测。通过这个练习我得到的主要结论是通过一些简单易用的工具,我们能快速地完成一些很有意义的分析流程。
注:原文刊载于Datescience+网站
原文地址:GoodReads: Machine Learning (Part 3)
