
前言
程序员最痛苦的事情,不是每天加班写程序,而是每天加班读懂别人写的程序。
大多数程序员写的代码都没有考虑,如何让别人看着更方便!最后,实在忍受不了看其他人的丑陋代码时,有人开始制定代码编程规范;又有人实现代码的自动化排版工具。formatR就是这样的一个R语言自动化排版的工具。
目录
- formatR介绍
- formatR安装
- formatR的API介绍
- formatR的使用
- formatR的源代码解析
1. formatR介绍
formatR包是一个实用的包,提供了R代码格式化功能,自动设置空格、缩进、换行等代码格式,让代码看起来更友好。
formatR的发布页:http://yihui.name/formatR/
2. formatR安装
系统环境
- Win7 64bit
- R: 3.0.1 x86_64-w64-mingw32/x64 b4bit
formatR安装
~ R
> install.packages("formatR")
trying URL 'http://mirror.bjtu.edu.cn/cran/bin/windows/contrib/3.0/formatR_0.10.zip'
Content type 'application/zip' length 49263 bytes (48 Kb)
opened URL
downloaded 48 Kb
package ‘formatR’ successfully unpacked and MD5 sums checked
formatR加载
library(formatR)
3. formatR的API介绍
- 1). tidy.source: 对代码进行格式化
- 2). tidy.eval: 输出格式化的R代码和运行结果
- 3). usage: 格式化函数定义,并按指定宽度输出
- 4). tidy.gui: 一个GUI工具,支持编辑并格式化R代码
- 5). tidy.dir: 对某个目录下,所有R脚本进行格式化
3. formatR的使用
- 1). tidy.source:以字符串形式,对代码格式化
- 2). tidy.source:以文件形式,对代码格式化
- 3). 格式化并输出R脚本文件
- 4). tidy.eval: 输出格式化的R代码和运行结果
- 5). usage: 格式化函数定义,并按指定宽度输出
- 6). tidy.gui: GUI工具,编辑并格式化R代码
- 7). tidy.dir: 对目录下,所有R脚本进行格式化
1). 以字符串形式,对代码格式化
> tidy.source(text = c("{if(TRUE)1 else 2; if(FALSE){1+1", "## comments", "} else 2}"))
{
if (TRUE)
1 else 2
if (FALSE) {
1 + 1
## comments
} else 2
}
2). 以文件形式,对代码格式化
> messy = system.file("format", "messy.R", package = "formatR")
> messy
[1] "C:/Program Files/R/R-3.0.1/library/formatR/format/messy.R"
原始代码输出
> src = readLines(messy)
> cat(src,sep="\n")
# a single line of comments is preserved
1+1
if(TRUE){
x=1 # inline comments
}else{
x=2;print('Oh no... ask the right bracket to go away!')}
1*3 # one space before this comment will become two!
2+2+2 # 'short comments'
lm(y~x1+x2, data=data.frame(y=rnorm(100),x1=rnorm(100),x2=rnorm(100))) ### only 'single quotes' are allowed in comments
1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1 ## comments after a long line
'a character string with \t in it'
## here is a long long long long long long long long long long long long long long long long long long long long comment
格式化后的代码输出
> tidy.source(messy)
# a single line of comments is preserved
1 + 1
if (TRUE) {
x = 1 # inline comments
} else {
x = 2
print("Oh no... ask the right bracket to go away!")
}
1 * 3 # one space before this comment will become two!
2 + 2 + 2 # 'short comments'
lm(y ~ x1 + x2, data = data.frame(y = rnorm(100), x1 = rnorm(100), x2 = rnorm(100))) ### only 'single quotes' are allowed in comments
1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 ## comments after a long line
"a character string with \t in it"
## here is a long long long long long long long long long long long long long long long long
## long long long long comment
3). 格式化并输出R脚本文件
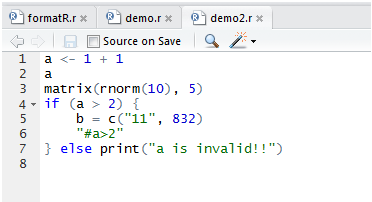
新建R脚本文件:demo.r
~ vi demo.r
a<-1+1;a;matrix(rnorm(10),5);
if(a>2) { b=c('11',832);"#a>2";} else print('a is invalid!!')
格式化demo.r
> x = "demo.r"
> tidy.source(x)
a <- 1 + 1
a
matrix(rnorm(10), 5)
if (a > 2) {
b = c("11", 832)
"#a>2"
} else print("a is invalid!!")
输出格式化结果到文件:demo2.r
> f="demo2.r"
> tidy.source(x, keep.blank.line = TRUE, file = f)
> file.show(f)
4). tidy.eval: 输出格式化的R代码和运行结果
以字符串形式,执行R脚本
> tidy.eval(text = c("a<-1+1;a", "matrix(rnorm(10),5)"))
a <- 1 + 1
a
## [1] 2
matrix(rnorm(10), 5)
## [,1] [,2]
## [1,] 0.65050729 0.1725221
## [2,] 0.05174598 0.3434398
## [3,] -0.91056310 0.1138733
## [4,] 0.18131010 -0.7286614
## [5,] 0.40811952 1.8288346
5). usage: 格式化函数定义,并按指定宽度输出
> var
function (x, y = NULL, na.rm = FALSE, use)
{
if (missing(use))
use <- if (na.rm)
"na.or.complete"
else "everything"
na.method <- pmatch(use, c("all.obs", "complete.obs", "pairwise.complete.obs",
"everything", "na.or.complete"))
if (is.na(na.method))
stop("invalid 'use' argument")
if (is.data.frame(x))
x <- as.matrix(x)
else stopifnot(is.atomic(x))
if (is.data.frame(y))
y <- as.matrix(y)
else stopifnot(is.atomic(y))
.Call(C_cov, x, y, na.method, FALSE)
}
<bytecode: 0x0000000008fad030>
<environment: namespace:stats>
> usage(var)
var(x, y = NULL, na.rm = FALSE, use)
usage函数,只输出函数的定义。
> usage(lm,width=30)
lm(formula, data, subset, weights,
na.action, method = "qr", model = TRUE,
x = FALSE, y = FALSE, qr = TRUE,
singular.ok = TRUE, contrasts = NULL,
offset, ...)
usage的width参数,控制函数的显示宽度。
6). tidy.gui: GUI工具,编辑并格式化R代码
安装gWidgetsRGtk2库
> install.packages("gWidgetsRGtk2")
also installing the dependencies ‘RGtk2’, ‘gWidgets’
trying URL 'http://mirror.bjtu.edu.cn/cran/bin/windows/contrib/3.0/RGtk2_2.20.25.zip'
Content type 'application/zip' length 13646817 bytes (13.0 Mb)
opened URL
downloaded 13.0 Mb
trying URL 'http://mirror.bjtu.edu.cn/cran/bin/windows/contrib/3.0/gWidgets_0.0-52.zip'
Content type 'application/zip' length 1212449 bytes (1.2 Mb)
opened URL
downloaded 1.2 Mb
trying URL 'http://mirror.bjtu.edu.cn/cran/bin/windows/contrib/3.0/gWidgetsRGtk2_0.0-82.zip'
Content type 'application/zip' length 787592 bytes (769 Kb)
opened URL
downloaded 769 Kb
package ‘RGtk2’ successfully unpacked and MD5 sums checked
package ‘gWidgets’ successfully unpacked and MD5 sums checked
package ‘gWidgetsRGtk2’ successfully unpacked and MD5 sums checked
打开GUI控制台
> library("gWidgetsRGtk2")
> g = tidy.gui()
我们输入一段不太好看的代码:
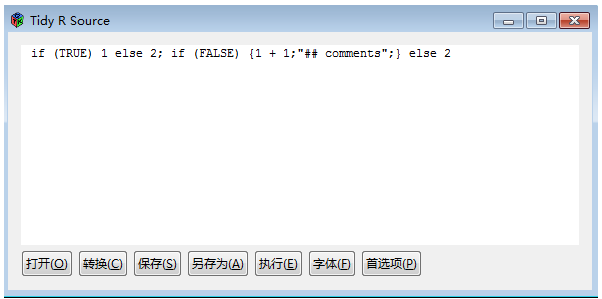
点击“转换”
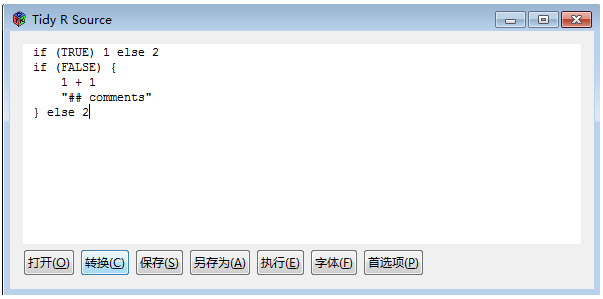
在GUI的编辑器中,R语言的代码被格式化了!
7). tidy.dir: 对dir目录下,所有R脚本进行格式化
新建目录:dir
新建两个R脚本文件:dir.r, dir2.r
~ mkdir dir
~ vi dir.r
a<-1+1;a;matrix(rnorm(10),5);
~ vi dir2.r
if(a>2) { b=c('11',832);"#a>2";} else print('a is invalid!!')
执行tidy.dir
> tidy.dir(path="dir")
tidying dir/dir.r
tidying dir/dir2.r
分别查看dir.r和dir2.r
~ vi dir.r
a <- 1 + 1
a
matrix(rnorm(10), 5)
~ vi dir2.r
if (a > 2) {
b = c("11", 832)
"#a>2"
} else print("a is invalid!!")
我们发现不规则的代码,已经被格式化了!!
5. formatR的源代码解析
通过上面的使用,我们不难发现formatR包的核心函数,就是tidy.source函数,从github上面找到源代码:https://github.com/yihui/formatR/blob/master/R/tidy.R
我将在代码中增加注释:
tidy.source = function(
source = 'clipboard', keep.comment = getOption('keep.comment', TRUE),
keep.blank.line = getOption('keep.blank.line', TRUE),
replace.assign = getOption('replace.assign', FALSE),
left.brace.newline = getOption('left.brace.newline', FALSE),
reindent.spaces = getOption('reindent.spaces', 4),
output = TRUE, text = NULL,
width.cutoff = getOption('width'), ...
) {
## 判断输入来源为剪贴板
if (is.null(text)) {
if (source == 'clipboard' && Sys.info()['sysname'] == 'Darwin') {
source = pipe('pbpaste')
}
} else { ## 判断输入来源为字符串
source = textConnection(text); on.exit(close(source))
}
## 按行读取来源数据
text = readLines(source, warn = FALSE)
## 大小处理
if (length(text) == 0L || all(grepl('^\\s*$', text))) {
if (output) cat('\n', ...)
return(list(text.tidy = text, text.mask = text))
}
## 空行处理
if (keep.blank.line && R3) {
one = paste(text, collapse = '\n') # record how many line breaks before/after
n1 = attr(regexpr('^\n*', one), 'match.length')
n2 = attr(regexpr('\n*$', one), 'match.length')
}
## 注释处理
if (keep.comment) text = mask_comments(text, width.cutoff, keep.blank.line)
## 把输入的R代码,先转成表达式,再转回字符串。用来实现对每个语句的截取。
text.mask = tidy_block(text, width.cutoff, replace.assign && length(grep('=', text)))
## 对注释排版
text.tidy = if (keep.comment) unmask.source(text.mask) else text.mask
## 重新定位缩进
text.tidy = reindent_lines(text.tidy, reindent.spaces)
## 扩号换行
if (left.brace.newline) text.tidy = move_leftbrace(text.tidy)
## 增加首尾空行
if (keep.blank.line && R3) text.tidy = c(rep('', n1), text.tidy, rep('', n2))
## 在console打印格式化后的结果
if (output) cat(paste(text.tidy, collapse = '\n'), '\n', ...)
## 返回,但不打印结果
invisible(list(text.tidy = text.tidy, text.mask = text.mask))
}
Bug: 没有对”->”进行处理
在读源代码的过程中,发现有一个小问题,没有对”->”进行处理,已经给作者提bug了。
https://github.com/yihui/formatR/issues/31
bug测试代码:
> c('11',832)->x2
> x2
[1] "11" "832"
> tidy.source(text="c('11',832)->x2")
c("11", 832) <- x2
> tidy.eval(text="c('11',832)->x2")
c("11", 832) <- x2
Error in eval(expr, envir, enclos) : object 'x2' not found
BUG已修复:
作者回复:这个问题已经在R 3.0.2中修正了。
> formatR::tidy.source(text="c('11',832)->x2")
x2 <- c("11", 832)
> sessionInfo()
R version 3.0.2 (2013-09-25)
Platform: x86_64-pc-linux-gnu (64-bit)
locale:
[1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
[5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
[7] LC_PAPER=en_US.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
attached base packages:
[1] stats graphics grDevices utils datasets methods base
loaded via a namespace (and not attached):
[1] formatR_0.10.3
formatR包提供的功能非常实用,特别是读别人写的不规范的代码的时候。建议各IDE厂商能把formatR,作为标准的格式化工具直接嵌入编辑器的工具里面。让我们把读别人的代码,也变成一件快乐的事情吧。
作者介绍:
张丹,R语言中文社区专栏特邀作者,《R的极客理想》系列图书作者,民生银行大数据中心数据分析师,前况客创始人兼CTO。
10年IT编程背景,精通R ,Java, Nodejs 编程,获得10项SUN及IBM技术认证。丰富的互联网应用开发架构经验,金融大数据专家。个人博客 http://fens.me, Alexa全球排名70k。
著有《R的极客理想-工具篇》、《R的极客理想-高级开发篇》,合著《数据实践之美》,新书《R的极客理想-量化投资篇》(即将出版)。


