每天12点是小编最激动的时候,因为自己写的帖子又可以与大家见面啦,昨天把帖子传到某个大神组织的数据挖掘交流群时,某挖掘机朋友问了小编一个深刻的问题,题目看似很简单,但是以小编大脑里的知识系统来说,根本没有思路。此时,各路大神纷纷支招,问题顺利解决,小编也算涨了涨见识!所以小编今天想暂停一期数据城堡的代码实战,来带大家一探昨晚的究竟!
1 问题1
问题首先是这样的:

大神开始支招:
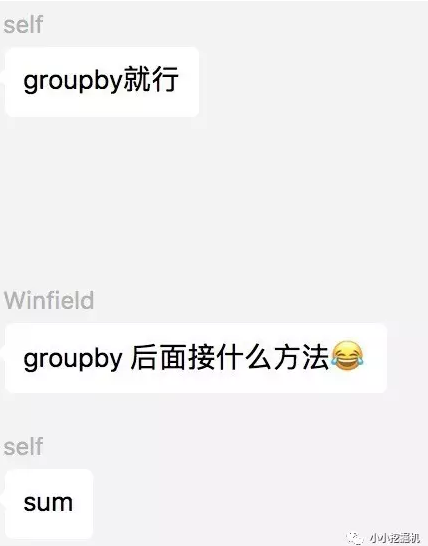
纳尼!字符串可以通过sum()进行拼接,简直颠覆了我的三观,吓得小编赶紧写代码一试:
df =pd.DataFrame([(0,'abc'),(0,'bcd'),(1,'efg')],columns=['id','str'])
print (df.groupby(['id'])['str'].sum())
输出结果如下:
id
0 abcbcd
1 efg
居然真的可以,小编的知识真是太狭隘了,给好好上了一课,惭愧惭愧!
2 问题2
问题又来了,这次是这样的:

这时小编开始瞎搞,把后面的sum() 替换为join(' '),报错了!大神又开始支招了:
小编又亲自尝试了一番,代码如下:
df['str']=df['str'].apply(lambda x:' '+x)
df1=df.groupby('id').sum()
df1['str']=df1['str'].apply(lambda x:x[1:])
print (df1)
输出结果如下:
str
id
0 abc bcd
1 efg
小编对这段代码的理解是这样的:第一行,我们首先对str列中的每一个值,通过一个匿名函数lambda进行处理,在每一个值前面加一个空格;随后我们根据id值进行分组并通过sum()运算进行连接,同时赋值给一个新的DataFrame;最后我们再通过一个匿名函数去掉开头的一个空格即可。
此时,另一位大神又来支招啦,使得我们的代码更加简洁:

代码实现是这样的:
df2=df.groupby(['id']).apply(lambda x:' '.join(x['str']))
print (df2)
输出如下:
id
0 abc bcd
1 efg
仅仅用了一行,就实现了上面三行的功能,小编带你一同分析一下这句代码。首先仍然是根据id进行分组,我们来看一下分组之后的数据类型:
print (type(df.groupby(['id'])))
输出如下:
<class 'pandas.core.groupby.DataFrameGroupBy'>
可以看到,输出是一个DataFrameGroupBy对象,我们要怎么对这个对象进行预览呢?我们首先尝试如下代码:
for group in group_df:
print (type(group))
print (group)
我们来看看输出:
<class 'tuple'>
(0, id str
0 0 abc
1 0 bcd)
<class 'tuple'>
(1, id str
2 1 efg)
天呐,我们得到是一个个元组,这也太不好看了。其实,真正的预览方式应该是这样的:
for id, group in group_df:
print(type(group))
print(id)
print(group)
输出结果如下:
<class 'pandas.core.frame.DataFrame'>
0
id str
0 0 abc
1 0 bcd
<class 'pandas.core.frame.DataFrame'>
1
id str
2 1 efg
这样就清晰很多了嘛,我们得到了每一个group都是DataFrame对象。
为什么会这样呢,这是因为前文所提到的DataFrameGroupBy对象是一个二元元组,由分组名(此处即id值)和数据块组成,因此在迭代的时候我们要指定两个参数,分别获取分组名和数据块,从而顺利完成遍历。
我们再来回顾一下上面的代码:
df2=df.groupby(['id']).apply(lambda x:' '.join(x['str']))
分组之后为什么直接作用于一个lambda函数上就能得到我们想要的效果呢,这是因为代码中的x是每一组的数据块,而不是一个二元元组,这是最关键的!然后我们对每一组的数据块通过一个空格进行连接即可,这里值得提醒大家的是当我们通过列名获得DataFrame中一列时,返回的是一个Series对象,它可直接使用join方法进行连接。
print (type(df['str']))
<class 'pandas.core.series.Series'>
3 总结
本篇,小编带你回顾了一下昨天发生在群里的一些小故事,并详细带大家分析了遇到的问题,希望大家有所收获!在此,特别感谢问题的提问者以及回答者(排名不分先后)@Winfield @self @穆文
小编也是一枚数据挖掘领域的小菜鸟,遇到问题不会是正常的,但是最主要的是一种虚心学习的态度,希望大家能与小编一起共同成长和进步!
想了解更多?
那就赶紧来关注我们
后台回复“资料”,有惊喜哦!

长按二维码 关注我们
