兔子:打架猴-.-,我是一只在Data Science的菜鸟,理想是游戏数据分析师,本文是一些国外网课(吴恩达NG大神)+自己的(逗比)理解+学校教授的讲解,希望在这个学期可以一直坚持更新,新年祝自己在3个月后能有offer回国:)
What is Machine Learning?
其实简单的理解就是Google那个下棋
如果计算机被安排了一个任务要赢这局围棋,那么有多大的几率win呢?这个几率可以通过海量的数据集来提升。
E:围棋的experience
T:赢得这局围棋
P:下一局会赢的几率?
在机器学习中,基本分成Supervised learning and Unsupervised learning 两类。
监督学习和非监督学习
一. 监督学习
举个例子预测房价
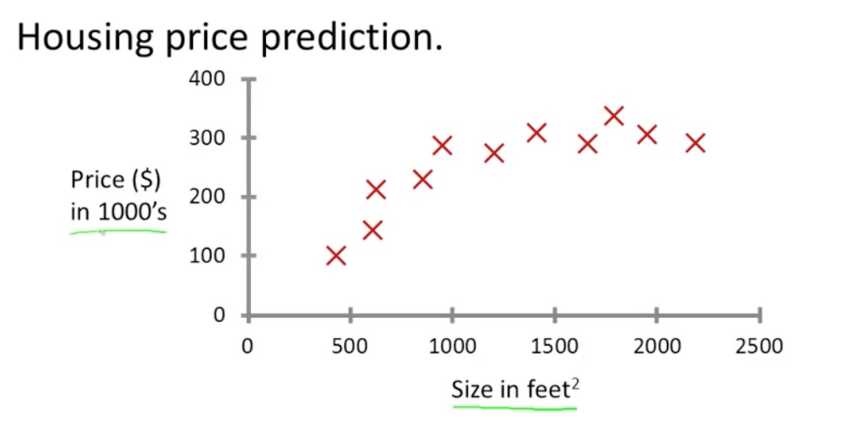
给一部分已有房子的数据集(已经有正确答案的数据集,比如房价),然后通过算法,可以有XXX的概率得出新的房子的价格。
而监督学习又分成:
1. 连续变量,房价1-10万这种数据
2. 离散变量,某人能得到offer Y/N 或者更多可能性,0,1,2,3,4
要是只有单一属性的话,用房子的大小----预测房价则算法很简单。但是生活中往往会有3-5个属性,甚至无数个属性!(啧啧房价堪忧-.-)那么怎么办?
这里就要介绍到支持向量机的算法:一种简洁的数学方法,能够让电脑处理无数种特征(What!...自动加班可好?)这个后面再说。
结尾来个Case Study:
假设现在你在一家互联网公司上班,在做分析师(啧啧羡慕脸.jpg), 老板给你2个问题:
1.库存里2万个商品,老板让你预测以后3个月每一个商品的销售情况,以便提前备货
2.游戏部门有20万个用户,运营部门命令你(给跪了),分析每一个游戏用户是不是用过外挂刷钻石!(刷Q币见者有份啊啊啊啊啊啊)
嗯...真正的问题来了,请问1,2哪些是regression,哪些是分类?
额= =,好明显的问题,1回归,2.分类,因为一个连续一个离散。
More Example
1.自拍照----预测你的年龄( what! 黑科技啊啊啊)属于回归
2.游戏新用户-------预测是大R还是非洲人(那一定在说我-.-) 属于分类
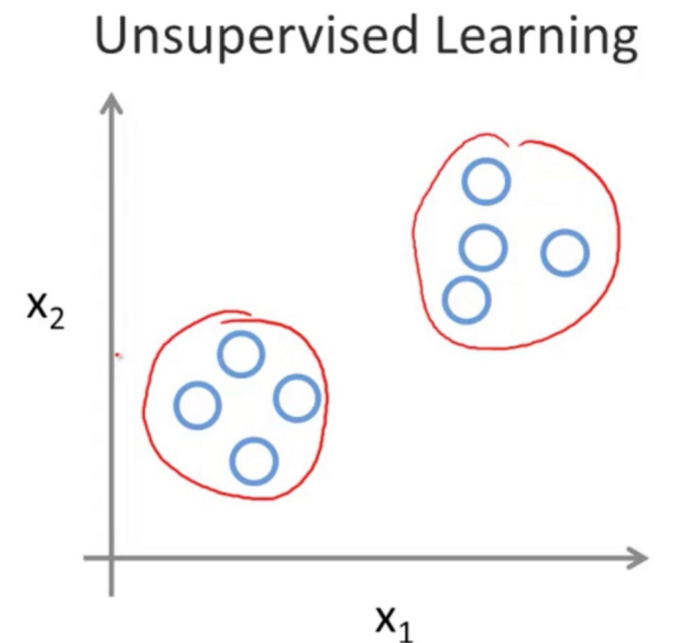
二. 非监督学习
先说说他和监督学习的差异,监督学习其实已经有了一个目标,房价or玩家有没开外挂的Y/N。
而在非监督学习中,根本就没有属性或标签的存在,也就是说全部数据的标签是一样的,木有任何区别。想象一下,老板说给你这个月的用户资料,你看看有什么可以做的,我们可能不像之前那么的有目标性和任务性,这时候就可能需要做聚类了。
举个例子,百度每天会自动去搜索大量的原始URL网址,然后将它们分类,变成头条啊,新闻啊,图片啊,视频啊等等,其实他们的原始数据就是一个网址。当你搜索“2017年春晚真的是好看到没朋友了”的时候(怀疑能不能搜到=.=),那么电脑就会自动的将与春晚有关的全部网址归类,这就是我理解的聚类算法和非监督学习了。
例子2: 科学家用DNA数据进行分析,但是科学家完全不知道这些DNA是什么,有什么用。他们先用自动算法把这些DNA成几百种类型,然后有这些未知的DNA的人群是有什么特点,再深入研究。
例子3: 借用talkingdata于洋老师《游戏数据分析的艺术》的玩家分类图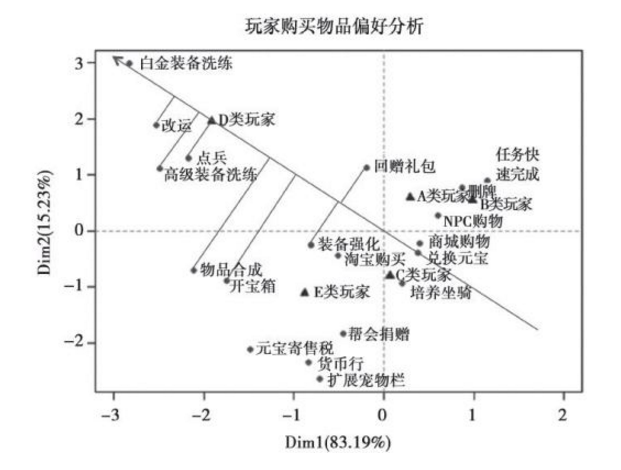
手游的客户分类,将未知的玩家原始数据,用聚类显示出来,当我们有新用户的时候,我们可不可以自动将他们分类,自动处理新的数据集。从而可以做到游戏运营的差异化和精准营销。
例子4:Facebook,领英或者微信朋友的关系
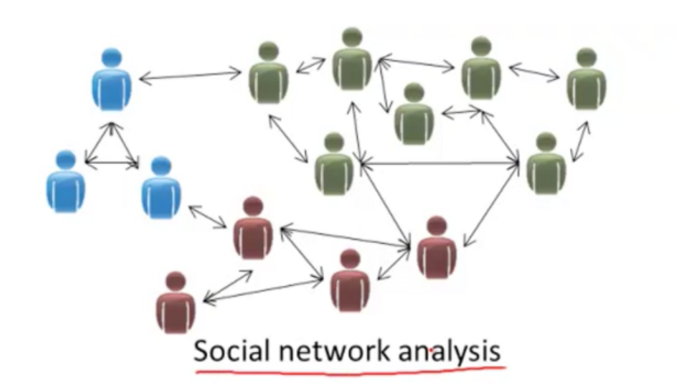
当然聚类只是其中之一。(which现在我就只懂这个- -)
让我们看看另一个example, 鸡尾酒聚会问题:
假如现在晚会有100人在说话,然后有2个同学在聊天,他们面前有2个麦克风(还带麦克风聊天的咩0.0)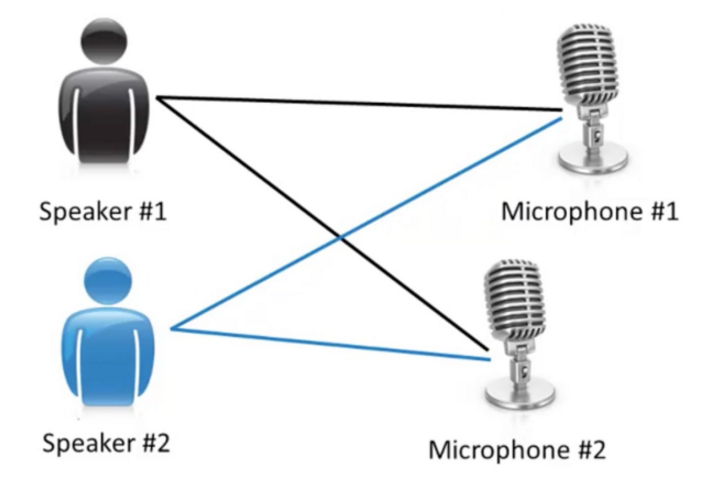
那么麦克风1和麦克风2接受到的声音其实是重叠了speaker A和B+背景音乐的。非监督学习可以将他们分类。
听起来好像要写好多好多代码!!!
而实际上这个算法只有一行代码(天啦噜!),是用了Octave来写的。因为Octave是目前硅谷用来做算法最快的办法,很多大咖都是先用Octave确定了算法可行再转移到Java和C++等等。
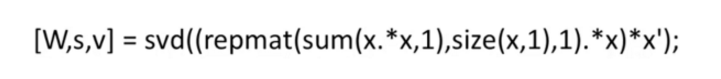
所以实际上非监督学习也为2类
1.Clustering--DNA,市场那种聚类
2.Non-Clustering-非聚类,像鸡尾酒语音这种有混乱因素的干扰,然后分离不同的变量。
第一次笔记快结束啦啦啦啦啦!-^-!最后,问题又来了:
以下哪些是非监督学习(可多选)
1.判断一个邮件是不是垃圾邮件,自动过滤
2.网上找到新闻,自动将他们归类
3.得到客户资料后,自动做market segmentation
4.得到海量病人有无癌症的数据集,判断新的病人有/无癌症
答案:1,2,3非监督,4监督。

