一、决策树
一种树状分类结构模型,是一种通过对变量值拆分建立起来的分类规则,又利用树形图分割形成的概念路径的数据分析技术。
二、决策树的两个关键步骤
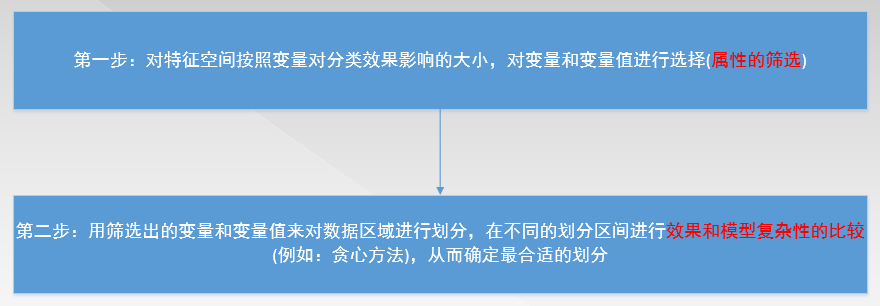
三、决策树的构建步骤
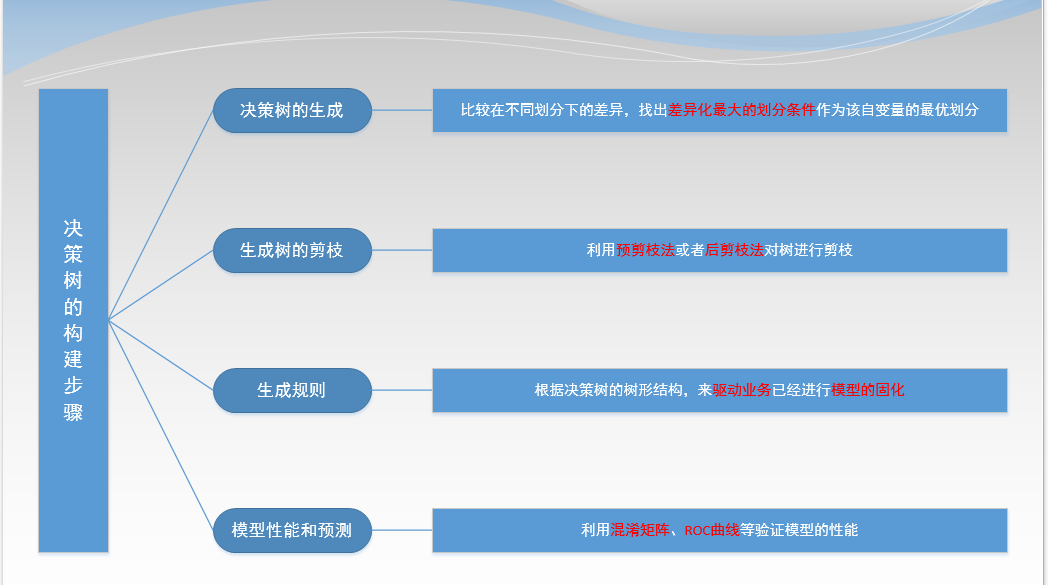
注:
⑴第一步中:先找出各个可以作为分类变量的自变量的所有可能的划分条件,再对每一个自变量比较各个划分下所得到的两个分支的差异大小,差异最大的划分条件作为该自变量的最优划分。
⑵第二步中:①剪枝很有可能剪掉的就是噪声和离群点,但是在金融风控领域中这些离群点才更有可能使我们关注的对象。②数据是在一直持续划分直至在一个分区中特征无区别,因此决策树很容易出现过度拟合的现象。③对于大规模的数据量,可以使用预剪枝的方法,来对决策树进行剪枝。
什么叫过度拟合?来复习一下。
在学习期间,它可能包含了训练数据中的某些特定的异常,这些异常不会在一般数据集中出现。
⑶第四步中:可以利用混淆矩阵、ROC曲线、AUC值等等模型评估指标来对我们的模型进行评估。
四、算法的理论知识介绍
下面我们对ID3算法、C4.5算法以及CART算法进行理论上的分享。我们用用的是韩家炜老师书中的一个小案例。
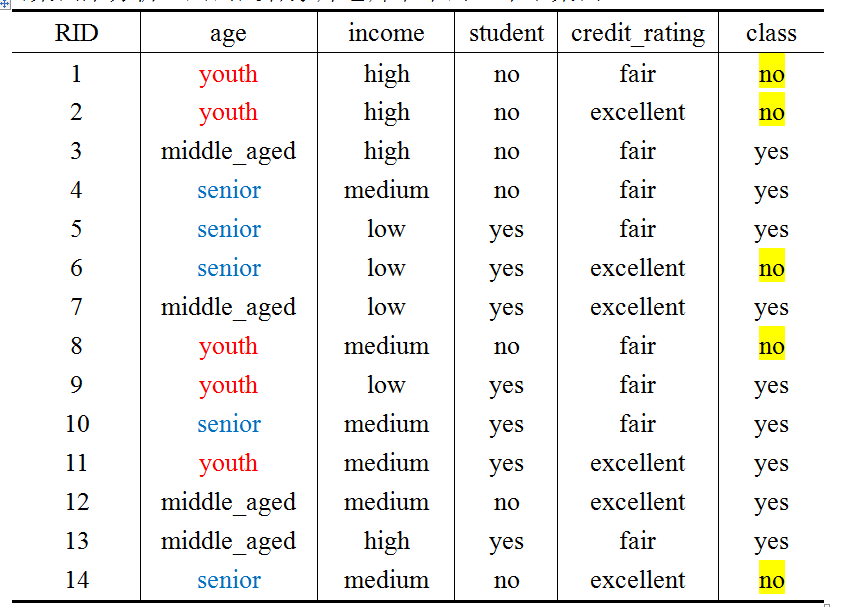
为了在叙述算法的时候方便,我们用A来表示age变量,用D来表示最后的类别class。
1、ID3算法
在算法中,最主要的就是信息增益,选择具有最高信息增益的属性作为节点N的分裂属性,该属性使得结果分区对元组分类所需要的信息量最小。属性A的信息增益表示如下:
大家现在是不是对公式有点晕,我们以上面的例子来看一下属性A的信息增益:
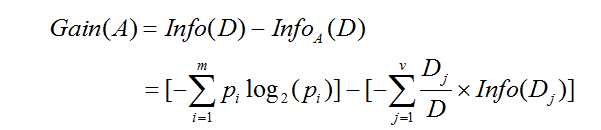
![Image]()
⑴首先给出信息熵的定义:
某一信源发出某一消息所含有的信息量,用平均自信息量表示,一般选用以2为底表示
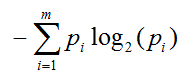
用下图对概率和信息的关系进行表示:
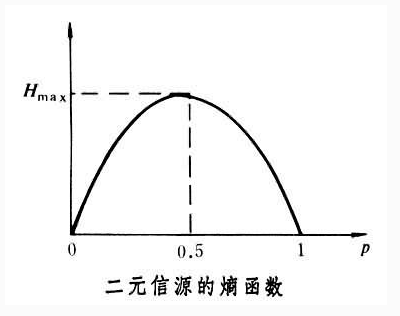
不确定性越大,比如概率都是0.5(类似于抛硬币),所含有的信息量越大。
⑵下面给出对D中元组分类所需要的期望信息:
Info(D)=-[(5/14)*log(5/14)+ (9/14)*log(9/14)
⑶下面给出Infoa(D)(上面公式的第二项的解释),它是基于属性A对D的元组进行分类所需要的期望信息,需要的信息越小,分区的纯度越高。
太书面话了,白话来一下,按照上面说的信息量,假如A自带的信息越少,就表明用A这个变量来对元组进行区分越容易,那么说这也印证了上面的一句话:选择具有最高信息增益的属性作为节点N的分裂属性,晓得了吧!
下面我们来计算Infoa(D):首先我们观察上面的表格,可以用下面的表格表示相关信息

首先我们先看公式中的每一个Dj,young有5个元组,middle_aged有4个元组,senior有5个元组,下面我们再来看young下面有3个no,2个yes;middle_aged下面全部是yes,senior下面有3个yes,2个no。
所以Infoa(D)的计算为:
Infoa(D)=(5/14)*[-2/5log(2/5)- 3/5log(3/5)]+ (4/14)*[-0/4log(0/4)- 4/4log(4/4)]+(5/14)*[-2/5log(2/5)- 3/5log(3/5)]
注:我们是不是发现按照age分类,我们已经把middle_aged全部分为了yes。
⑷上面的变量,比如age,是通过泛化,将连续的数值变量变成了离散的分类变量,在处理连续值的时候,我们可以让值递增排序,每对相邻值得中点作为分类点,这样如果有x个值,就有可能有x-1个可能的划分,再从中寻找最优的划分。
⑸ ID3算法的总结

2、C4.5算法
选择具有最高信息增益率的属性作为节点N的分裂属性,这样避免了偏袒的可能性。
即:在ID3算法的基础上除以否个变量的熵。
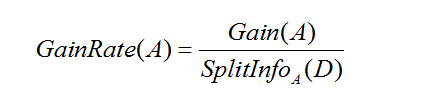
注: C4.5算法倾向于产生不平衡的划分,其中的一个分区比其他分区小得多。
五、ID3算法的演示
1、首先,我们计算上面4个变量的信息增益,其中:age变量的为0.246,income变量的为0.029,student变量的为0.151,credit_rating变量的为0.048,因此第一次选择我们选择age变量来进行树的分叉。

2、机智的你肯定已经发现对于左边的表格,下一次用student来进行分叉,对于右边的表格,用credit_rating来进行分叉,中间的表格已经搞定了吧!

