继上周的淘宝女装连衣裙信息爬虫进一步完善,进行了次级页面信息的抓取、支持多进程。
数据说明:
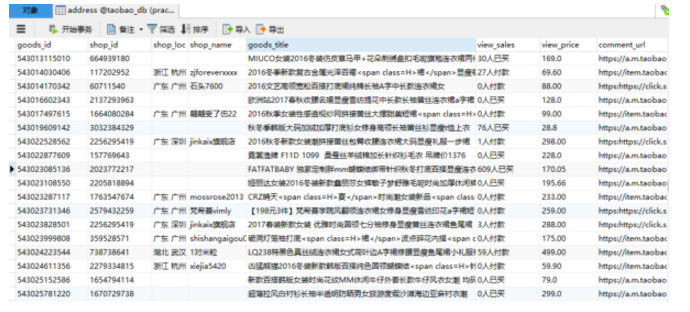
本次爬取淘宝女装连衣裙共8个字段信息,包括:商品ID、店铺ID、店铺地址、店铺名称、商品名称、销量、价格、商品详情链接。其中商品ID设为数据库存储的主键,防止了存储重复信息。共抓取 20258条数据。
淘宝连衣裙数据链接:百度网盘 密码:52r5
有兴趣的可以做分析,上周我们就抓取的部分数据做了简要分析
程序:Github—Taobao_dress
爬取逻辑:
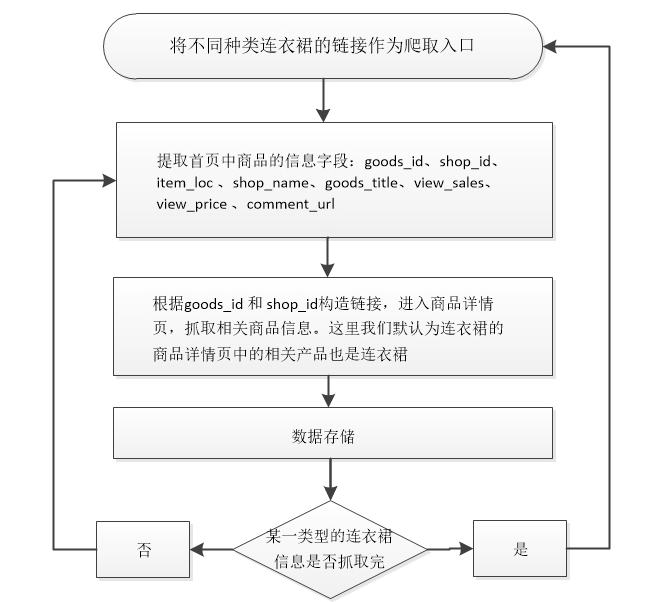
一、首页信息
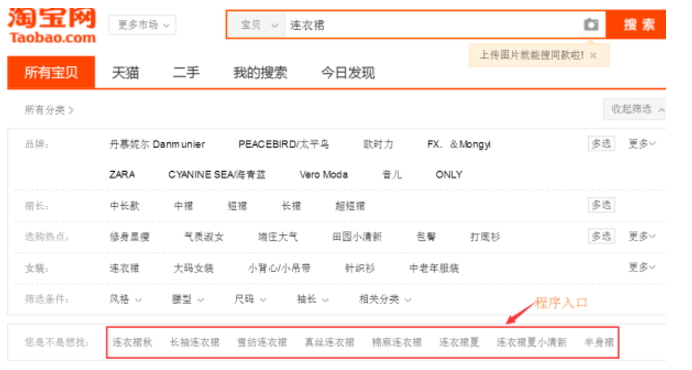
以连衣裙的种类为划分,每个种类如“棉麻连衣裙、长袖连衣裙、雪纺连衣裙、针织连衣裙等”分别对应一个起始链接,共设置15个链接作为一级页面的爬取入口。
在一级页面的抓取过程中,可在该页面的<head></head>标签内提取出本页商品信息,这里页面中信息是以字典的形式存储,我们用json.loads解析出每个商品的信息,即存储到MySQL的8个字段。将其中的商品ID、店铺ID 作为关键信息,可帮助我们生成链接进入下一级爬取页面。
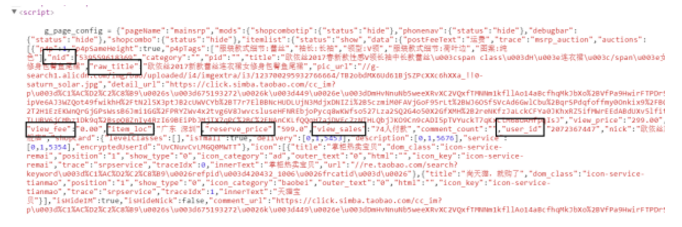
二、二级页面信息
我们根据在一级页面抓取过程中提取出的商品ID、店铺ID进入该商品的详情页,该页面下方一般会对与本产品相关的产品设置推广介绍,如下图。我们默认连衣裙页面的推广产品也是与连衣裙相关的同类产品,对其进行抓取,后续再进行数据的有效性分析。

在程序运行的过程中,我们查看存储在MySQL中的数据,可以发现在存储的商品信息中不完全都是与连衣裙有关的,在二级页面信息的抓取过程中我们虽然扩大了抓取范围,但是同时也降低了信息的有效性,可以看到有的数据与连衣裙无关,如果要精确分析还需要对数据进一步清洗。

三、信息抓取、保存
将抓取到的重复商品数据丢弃

保存抓取的商品数据