这几期和大家聊聊使用Python进行机器学习
题外话:之前一期 “ scrapy抓取当当网82万册图书数据 ” 的 Github 链接
Python拥有强大的第三方库,使用Python进行科学计算和机器学习同样需要先配置运行环境。这里我们需要安装Anaconda,官方给出的下载链接太慢,而且经常下载到一半卡死,这里我提供我下载好的网盘链接,密码:p2dt。需要的可以直接快速下载(Python3.5版)。Anaconda自带以下库Numpy、Scipy、Matplotlib、Pandas、和Scikit-Learn。
Numpy:提供数组支持,以及相应的高效处理函数;
Scipy:提供矩阵支持,以及矩阵相关的数值计算模块;
Matplotlib:数据可视化工具,作图库;
Pandas:强大、灵活的数据分析和探索工具;
Scikit - Learn:支持回归、分类、聚类等强大的机器学习库;
决策树是一个类似流程图的树状结构,其中每个内部节点都表示在一个属性上的测试,每个分支代表一个属性输出,而每个树叶节点代表类或类分布,最顶层是根节点。
决策树方法在分类、预测等领域有广泛应用。我在百度上找了张图,决策树是长这样:

下面我用一个案例来简单介绍下用Python实现决策树的机器学习过程
1、案例背景:某连锁餐饮企业手头拥有一批数据,想了解周末和非周末对销量是否有很大区别,以及天气的好坏、是否有促销活动对销量的影响。以单个门店为例,数据结构如下:
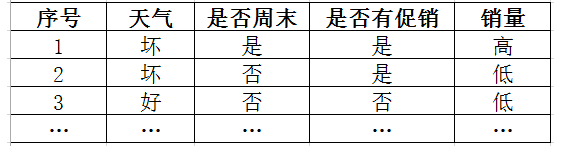
2、过程分析:这里我们采用的算法为ID3算法,ID3算法是啥,那么多博客说的比我清楚,大家可以搜搜决策树ID3就明白了。总结一句话:ID3就是基于信息熵来选择最佳测试属性,采用信息增益作为选择测试属性的标准。ID3生成的决策树模型:
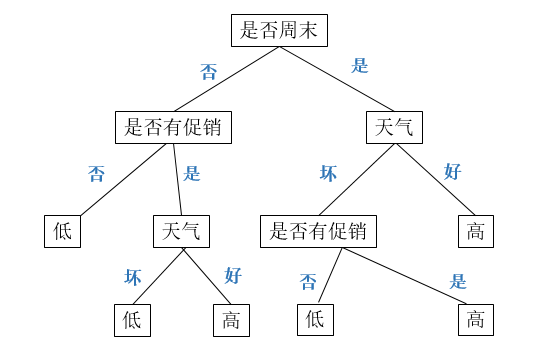
3、使用Scikit - Learn建立决策树模型
数据链接,密码:n7u5
#-*- coding: utf-8 -*-
import pandas as pd
#参数初始化
inputfile = '../FEB/data.xls' #这里输入你个人的文件路径
data = pd.read_excel(inputfile, index_col = u'序号') #导入数据
#数据是类别标签,要将它转换为数据
#用1来表示“好”、“是”、“高”这三个属性,用-1来表示“坏”、“否”、“低”
data[data == u'好'] = 1
data[data == u'是'] = 1
data[data == u'高'] = 1
data[data != 1] = -1
x = data.iloc[:,:3].as_matrix().astype(int)
y = data.iloc[:,3].as_matrix().astype(int)
from sklearn.tree import DecisionTreeClassifier as DTC
dtc = DTC(criterion='entropy') #建立决策树模型,基于信息熵
dtc.fit(x, y) #训练模型
#导入相关函数,可视化决策树。
from sklearn.tree import export_graphviz
x = pd.DataFrame(x)
with open("tree.dot", 'w') as f:
f = export_graphviz(dtc, feature_names = x.columns, out_file = f)
这里我们在该python文件的同级目录下导出的结果是一个dot文件(长得和word类似),需要安装Graphviz才能将其转换为pdf格式
导出的dot文件:
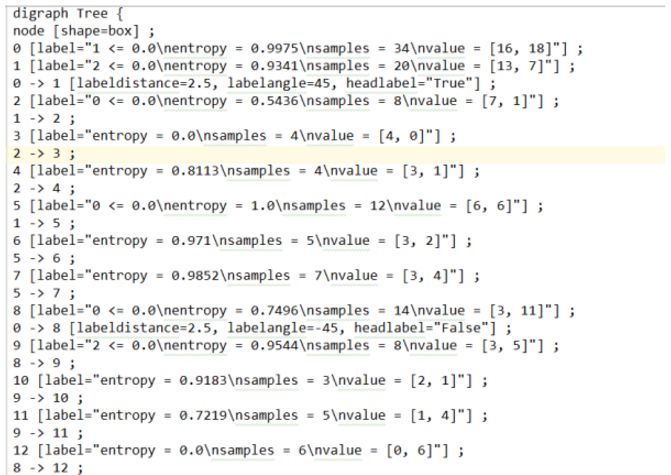
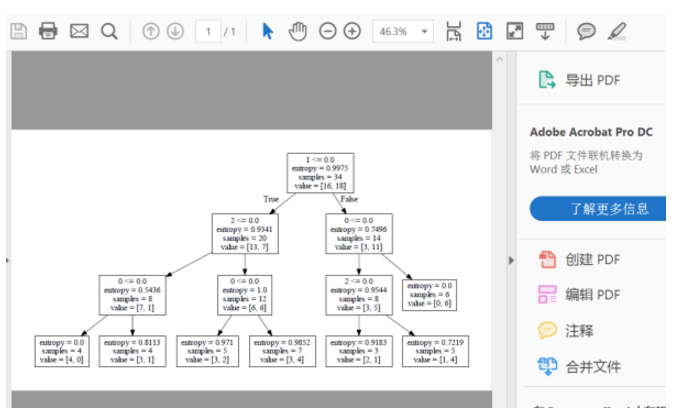
运行命令:dot -Tpdf tree.dot -o tree.pdf将该dot文件转化成结构化图
总结:决策树的优点:直观、便于理解、小规模数据集有效;决策树的缺点:类别较多时,错误增加较快,可规模性不强。

