本文介绍独立成分分析(ICA),同 PCA 类似,我们是要找到一个新的基来表示数据,但目的就不一样了。
鸡尾酒会问题:n 个人在一个 party 上同时说话,n 个麦克风放置在房间的不同位置,因为每个麦克风跟每个人的距离都不一样,所以它们记录的说话者重叠的声音也不一样。根据麦克风记录的声音,如何分离出 n 个说话者的声音呢?
为形式化这个问题,我们想象有一些数据 s∈R 是从 n 个独立的源生成的,我们观察到的是
x=As,
矩阵 A 是未知的,被称作混合矩阵,通过不断观察得到的是 {x(i);=1,...,m},我们的目标是找到生成数据(x(i)=As(i))的源 s(i)。
在鸡尾酒问题中,s(i) 是个 n 维向量,sj(i) 是讲话者 j 在时间 i 发出的声音, x(i) 也是个 n 维向量,xj(i) 是麦克风 j 在时间点 i 记录的声音。
设 W=A-1 为一个分离矩阵,我们的目标就是找到 W,这样就能根据麦克风记录的声音 x(i),来恢复声源 s(i)=Wx(i)。为表示方便起见,使 wiT 表示 W 的第 i 行。
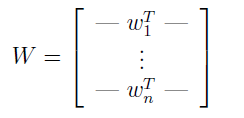
所以,wi∈Rn, 第 j 个源能够通过计算 sj(i)=wj(i) x(i) 来恢复。
1、ICA 的模糊性
W=A-1 能恢复到什么程度?如果没有源和混合矩阵的先验知识,不难看出,只给定 x,A 有一些固有的模糊性是不可能被恢复的。
设 P 为一个 n×n 的排列矩阵,这意味着 P 的每一行和每一列都只有一个 1,下面是一些排列矩阵的例子:
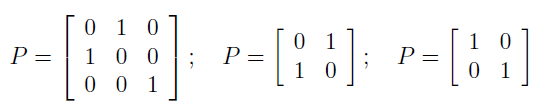
如果 z 是一个向量,那么 Pz 就是 z 的坐标重排版本的另一个向量。只给定 x(i),就没办法分辨 W 和 PW。原始信号的排列也是模糊不清的,幸运的是,这对大部分应用都不重要。
还有,无法恢复 wi 的准确比例,例如,如果 A 换成 2A,每个 s(i) 都换成 (0.5)s(i),那么我们观察到的依旧是 x(i)=2A·(0.5)s(i)。同样,如果 A 的一个列向量乘以因子 α,相应的源乘以因子 1/α,依然没有办法在只给定 x(i) 的情况下决定发生了什么。所以,我们无法恢复源的准确比例。不过,对于很多应用来说,这种模糊性都无关紧要,包括鸡尾酒会问题。
这就是 ICA 中模糊性唯一的源了吗?当 si 是非高斯,就是这样的。
那么高斯数据的困难是什么呢,看一个例子,n=2,s~N(0,I),其中 I 是 2×2 的单位矩阵。标准正态分布 N(0,I) 的密度的轮廓是以原点为中心的圆,密度时旋转对称的。
现在,假定我们观察到 x=As,其中 A 是混合矩阵,x 的分布也是高斯,均值为 0,协方差 E[xxT]=E[AssTAT]=AAT。设 R 为一个任意的正交矩阵,所以 RRT=RTR=I,使 A'=AR,如果数据是通过 A' 而不是 A 来混合的,那么可观察到 x'=A's。x 的分布也是高斯的,均值为 0,协方差为 E[x'(x')T]=E[A'ssT(A')T]=E[ARssT(AR)T]=ARRTAT=AAT。所以,不管混合矩阵是 A 还是 A',都能观察到数据符合 N(0,AAT) 分布。所以,就无法分辨源是通过 A 还是 A' 混合的,所以混合矩阵的旋转组件无法从数据中找出来,我们不能恢复原始源。
上面的讨论是基于多元标准正态分布是旋转对称的,ICA 在高斯数据上表现不行,但只要数据不是高斯的,给定足够的数据,我们就能恢复出 n 个独立的源。
2、密度和线性转换
在推导 ICA 算法之前,我们先来讨论下密度的线性转换的影响。
假定随机变量 s 符合密度函数 ps(s) ,简单起见,假设 s∈R 是一个实值,现在,随机变量 x 为 x=As,其中 s∈R,A∈R。那么 x 的密度 px 是什么?
设 W=A-1,为计算特定值 x 的概率,容易想到 s=Wx,然后估计该点的 ps,得出 px(x)=ps(Wx),当然这是不对的!例如,设 s~Uniform[0,1],所以 s 的密度为 ps(s)=1{0≤s≤1},现在让 A=2,那么 x=2s,很明显,x 是均匀分布在区间 [0,2],所以,它的密度为 px(x)=(0.5){0≤x≤2},而不是 ps(Wx),其中 W=0.5=A-1,正确的公式是 px(x)=ps(Wx)|W|。
一般地说,如果 s 是一个向量值,分布密度为 ps,x=As,其中 A 为可逆矩阵,那么 x 的密度为:
px(x)=ps(Wx)·|W|
其中 W=A-1。
3、ICA 算法
现在来推导 ICA 算法,ICA 算法归功于 Bell 和 Sejnowski,这里使用最大似然估计来解释算法,原始论文中的解释是用一种称为 infomax principal 的复杂思想,已经不适用于当前对 ICA 的理解。
假设每个源 si 的概率密度为 ps,源 s 的联合分布为:
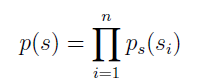
把联合分布建模为边缘分布的乘积,这里假设源是相互独立的。使用之前的公式,x=As=W-1s 的概率密度为:
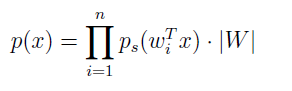
剩下的就是给独立的源 ps 指定一个密度。
给定一个实值随机变量 z,它的累积分布函数(cdf)F 定义为,F(z0)=P(z≤z0)=∫pz(z)dz,z 的密度就是对 F 求导:pz(z)=F'(z)。
所以,要指定 si 的密度,先指定一个累积分布函数 cdf。一个 cdf 是从 0 到 1 的单调递增函数,根据之前的讨论,不能选择高斯累积分布函数,因为 ICA 在高斯数据上无效。要选择一个合理的能从 0 到 1 缓慢递增的函数,就选择 sigmoid 函数:g(s)=1/(1+e-s),所以 ps(s)=g'(s)。
矩阵 W 是模型的参数,给定训练集 {x(i);i=1,...,m},log 似然为:
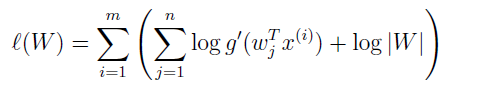
要以 W 为参数最大化该式。求导并使用事实 ▽w|W|=|W|(W-1)T,很容易就导出随机梯度下降学习规则。对于一个训练例子 x(i),更新规则为:
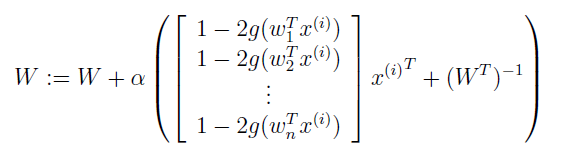
其中 α 是学习率。算法收敛后,就能够通过计算 s(i)=Wx(i) 来恢复原始信号。
写数据的似然时,x(i) 之间是相互独立的,所以训练集的似然为 ∏i p(x(i);W),这个假设对于讲话数据和其它 x(i) 依赖的时间序列是明显不对的,但可以看到,如果有足够的数据,即使训练集是相关的,也不会影响算法的性能。但是,对于连续训练例子是相关的问题,执行随机梯度下降时,有时碰到一些随机排列的训练集也会加速收敛。

