在这篇文章中 《 蓝色巨人IBM的变革与复兴,大数据时代的人工智能 IBM Watson 》我介绍到了 IBM Watson 在人工智能领域的布局和变革。那么本篇文章就带大家走进 IBM Watson 旗下认知计算、预测分析的云端数据分析产品 IBM Watson Analytics,也算是对上一篇文章的延续。
在本文中我将完整的介绍 IBM Watson Analytics 的试用过程,以及从产品设计的角度、从业务分析的场景中总结出来的关于 Watson Analytics 的一些亮点。这些亮点我个人认为也符合未来数据分析产品发展的整体趋势,相关背景文章请参考:
2017年商业智能 BI 发展趋势分析
深入分析 BI 数据可视化市场 SaaS 模式
IBM Watson Analytics
在 IBM 官方网站 上对 Watson Analytics 的介绍是这样的:专业的数据可视化分析工具。基于云平台的智慧的、自动化的数据发现服务和自动预测性分析功能,帮助用户轻松理解数据中的奥秘,并自动创建仪表板和信息图。
IBM Watson Analytics 能解决什么问题
Watson Analytics 数据可视化分析软件官方介绍 —— 可为您提供高级分析的诸多优势,但同时不增加复杂性。这种云端智慧数据发现服务可以引导数据探索,自动化实现预测分析,并支持轻松的仪表盘和信息图表创建。您可以迅速获得答案和新的洞察,在几分钟内迅速作出自信的决策 - 所有这一切全部由您自己完成,无需专业统计分析背景。
从这些描述中总结出来三个简单的特点:人人可用的数据可视化分析、云平台、自动化预测分析和数据洞察。
IBM Watson Analytics 的注册
试用 IBM Watson Analytics 需要注册一个 IBM ID 账号,根据一些提示填写一些基本的信息。
注册成功后,会收到邮件相应的邮件验证和 IBMid。
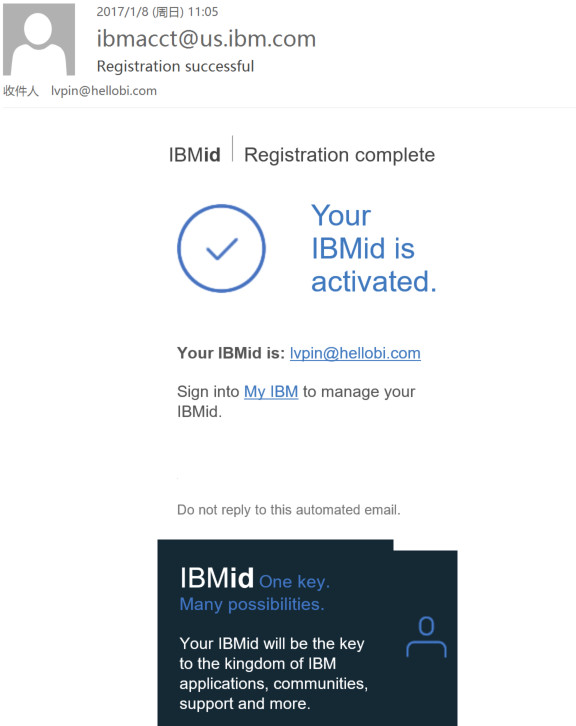
在主页面中有三个版块:
IBM Watson Analytics 数据准备
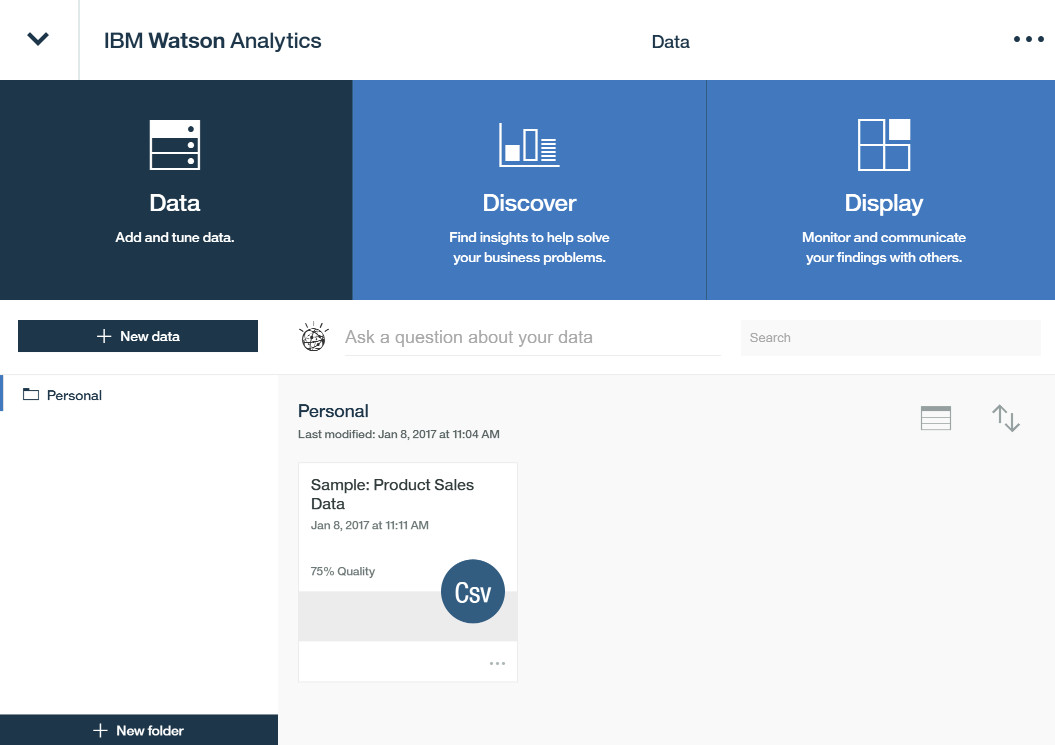
点击 New Data 可以发现 IBM Watson Analytics 预置了很多第三方应用和服务、IBM Cognos 、社交相关的数据接口(国外的为主),例如共享云存储 Dropbox、在线活动服务平台 Eventbrite、数字营销产品 Hubspot、很多外企都在用的笔试与问卷调查类 SurveyMonkey、Twitter 社交数据。
先简单使用 Local File 上传数据,实验数据来自 IBM Sample Data 一个有关人力资源培训相关的数据,可在本文的附件中下载。上传成功后在这个页面可以看到文件,可以重命名。
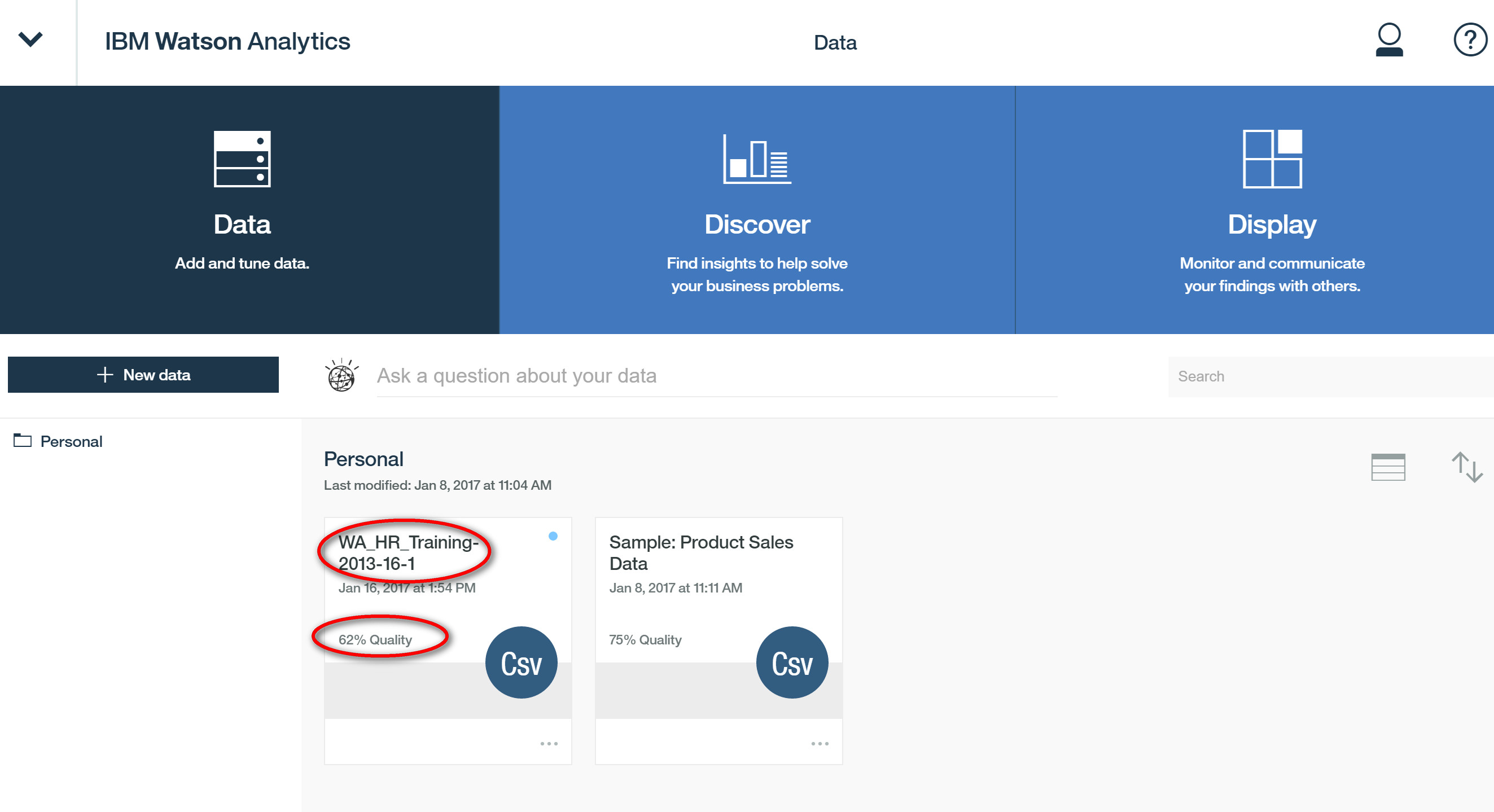
60% Quality 说明数据的质量在 60% 左右,这是因为 Watson Analytics 在上传这个数据的时候对数据做了一些内部的转换和分析。通过分析之后对数据给出评分,数据质量越好高评分就越高。如果分数很低,远远低于 60%,那么就意味着这个数据质量可能存在很大的问题,这种数据也不适合做进一步的分析。
在微软 BI 的 ETL 工具 SSIS 中也有一款类似的组件叫 SQL Profiling Task 也能够用来检查数据的质量。但目前有关数据准备的做法,这种趋势会更加明显 —— 数据在上传和加载的过程中就把数据质量的评估给反馈出来。
导致数据质量低的原因有的可能是空格、有的可能是空值、出现了与整列其它数据不匹配的数据类型的值等等,这个时候可以点击 Refine 对数据重新做出调整和优化。
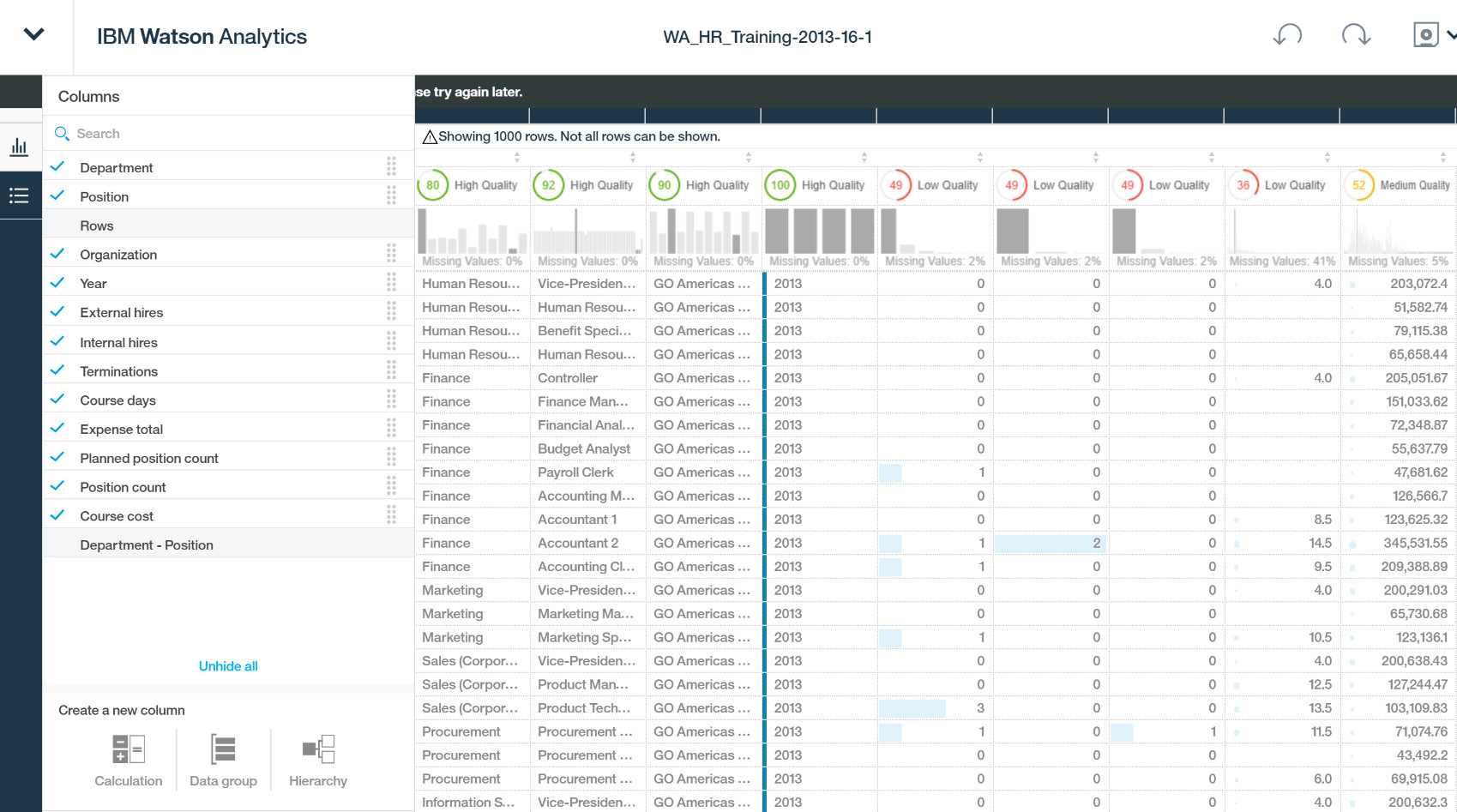
Refine 页面下可以看到不同列的数据质量情况,包括缺失值、甚至可以看到数据之间的层次关系等等。也可以在 Refine 页面创建计算列、数据组(比如 Age 1-12 岁定义为少年等 )、增加层级关系等。
Refine 的作用就类似于一个数据质量检查工具和一个轻量的 ETL 数据准备和清洗工具。
数据准备阶段的几点总结和思考
1. 这款产品的面向的用户群体可以是无需专业统计分析背景的业务人员,因此在数据准备环节对源数据的要求还是存在的。数据尽量通过 IT 部门做过专业的清洗和规范,这样会更大程度的节省业务人员在数据准备上的时间和精力。
2. 在保证大部分数据规范和质量的前提下,业务人员可以根据自己的理解对数据做一些初步加工。这一点在以后的数据分析工具发展上是一个趋势,让业务人员自己可以处理一些基本的数据清洗,而不用事事都需要 IT 的支持。
3. IBM Watson Analytics 数据上传即反馈数据质量评估,数据质量评估得分低则表明该数据不适合在接下来的分析场景中使用。因此,这就尽最大可能的避免了因低质量的数据而造成了分析结果不准确的情况。
4. 在数据准备的沟通和环节上,IT 部门和业务部门可以有效的进行职责划分。IT 部门对数据质量结果负责,业务部分对分析结果负责。IT 部门数据提供的质量低,则返回重做、重新准备,直到达到双方共识的一个标准比如 80% 或者 90%,达到这个标准后业务部门再进行后续的数据分析和探索工作。
IBM Watson Analytics 的数据质量评估为我们提供了一个很好的关于数据质量的参考,我们可以利用好这个特点对团队的协作过程进行有效的考核和流程把控。
在快速完成了数据上传和加载动作后,我们开始在 IBM Watson Analytics 中进行数据探索和分析的工作。
IBM Watson Analytics 数据分析与探索
在正式的数据探索和分析之前,先来简单的了解一下要分析的数据(只展示了部分数据)。
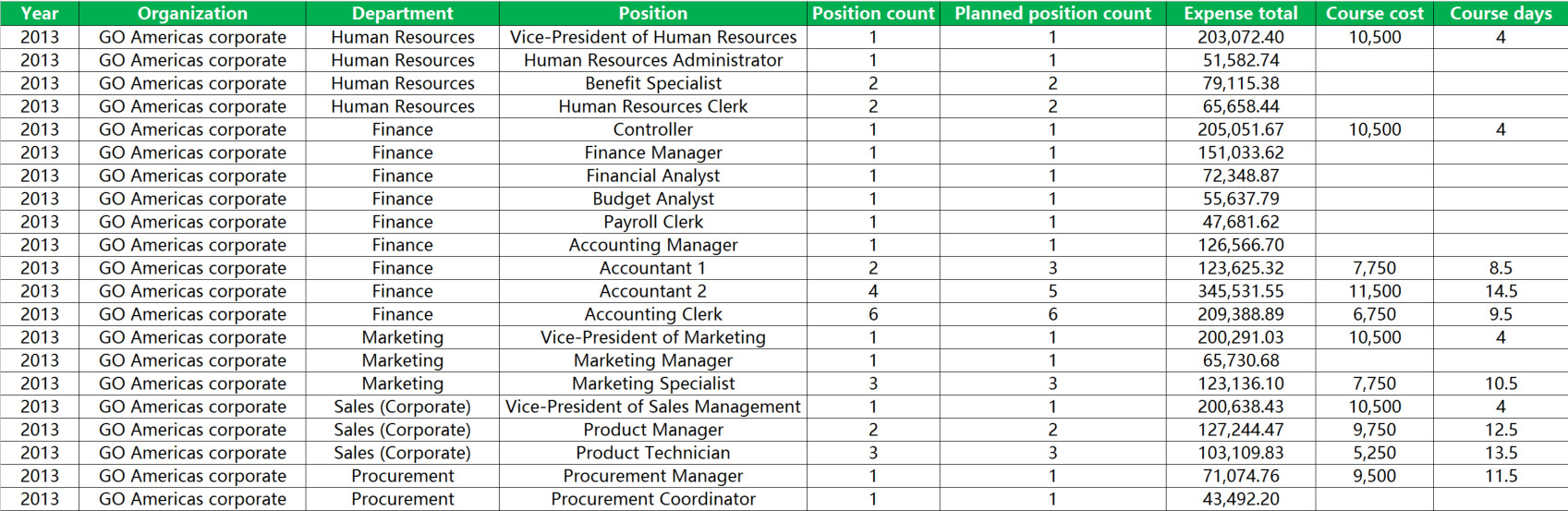
很显然,在这份数据中可以分析的是有关培训课程的消费或支出成本等问题。先简单的理解和观察一下这些数据,这对后面理解 IBM Watson Analytics 是如何设计这种自动化化数据分析和自然语言探索很有帮助。
点击文件的标题 - WA_HR_Training-2013-16-1,我们对数据的分析就已经开始了,并且这是一种全新的体验。在以前我们是要向自己提问,通过工具来帮助实现。而现在 Watson Anlytics 向你提问或是你也可以向它提问,而提问之后的分析都会自动实现。
在 Discovery 分析和探索页面,Watson “猜”出了你可能想要分析的问题。例如:
1. What is the trend of Course cost over Year by Department? 不同部门每年培训课程成本的趋势如何?
2. What drives Position Count ? 什么因素驱动了/影响了职位数量?
3. How are the values of Course days and Expense total associated ? 课程天数和费用总额之间有什么样的关系 ?
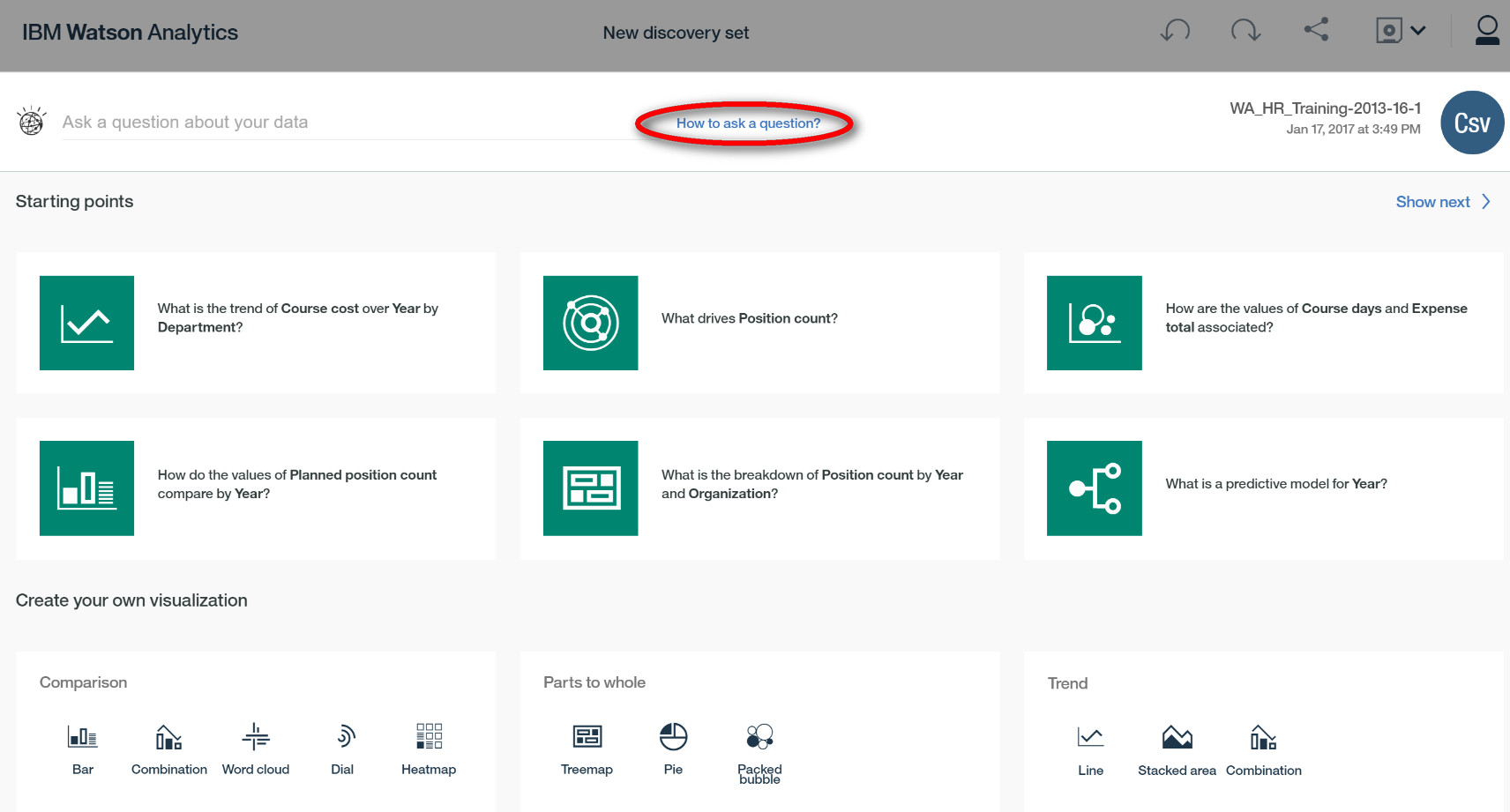
而每一项“猜”出来的问题,点击进去就会自动呈现一个分析结果,例如这个问题可能正是业务人员所需要的 What is the trend of Course cost over Year by Department?
一个分析就这么结束了,没有任何的拖拉拽操作,图形化的分析结果就已经呈现了。
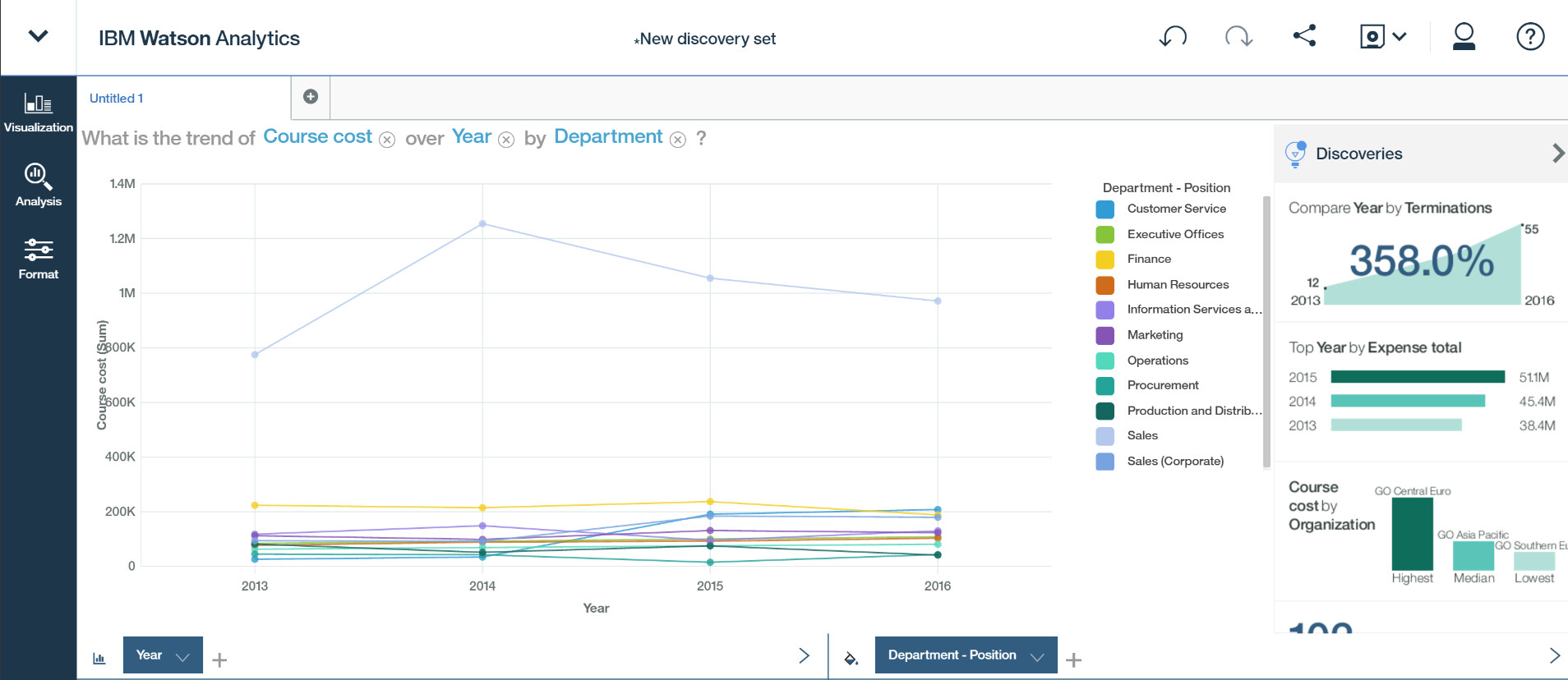
这种产品理念的过人之处就是 —— 它为你提供想法,但是把选择权留给你:
1. 对于很多没有从事过专业分析的业务人员 IBM Watson Analytics 给出了很多提示和线索,或者说分析问题的思路。有了这些提示和思路,普通业务人员可以通过这些问题很快速的得到分析结果。
2. 对于一些初级的从业务岗位转向业务分析的人员,也面临过这些问题:BI 开发人员在需求沟通的时候通常也会发现部分业务人员不知道要分析什么,可能知道要分析什么但又不知道分析的结果要如何呈现。通过 Watson Analytics,可以不需要 BI 开发人员的任何参与,业务人员可以自行挑选出所需要的分析结果。
3. 对于大部分数据分析人员,往往凭自己的经验可以很快的想出一些分析的场景,但是人无完人总有遗漏的分析角度。对于 IBM Watson Analytics 来说,分析的角度我提供给你,非常的全面,可以随时放在身边提醒你,是对你想法的一个补充,它并不会干涉你。
就如同员工跟老板汇报工作方案的时候,老板并没有考虑好要怎么来做,但员工准备了很多套方案。最终方案员工来提,老板来拍板,既不伤害老板的面子,又让老板获得权威感,Watson 的这种细腻的设计思维很人性化。同时,上面反应出来的几个问题对应是日常 BI 开发和数据分析、呈现阶段的几个痛点场景,IBM Watson Analytics 产品在这些方面的考虑还是比较周到的。
这是我们看到的 IBM Watson Analytics 通过我们上传的数据就 “猜” 出来的问题,同样,我们也可以向 Watson 提问我们自己的问题。
How to ask a question
返回到这个页面,我们再来关注一下 How to ask a question ?
如果你不知道要问什么问题,IBM Watson Analytics 提供了一些问题分类导向,每一个分类对应着不同角度的问题。
Variety pack - 一些基本的问题
Compare data - 数据比较相关的问题
Understand relationships and identify patterns - 理解数据之间的关系
Aggregate data - 有关数据聚合的问题
Sort and filter data - 排序和筛选
Predict data - 数据预测相关的问题
All available examples - 所有问题
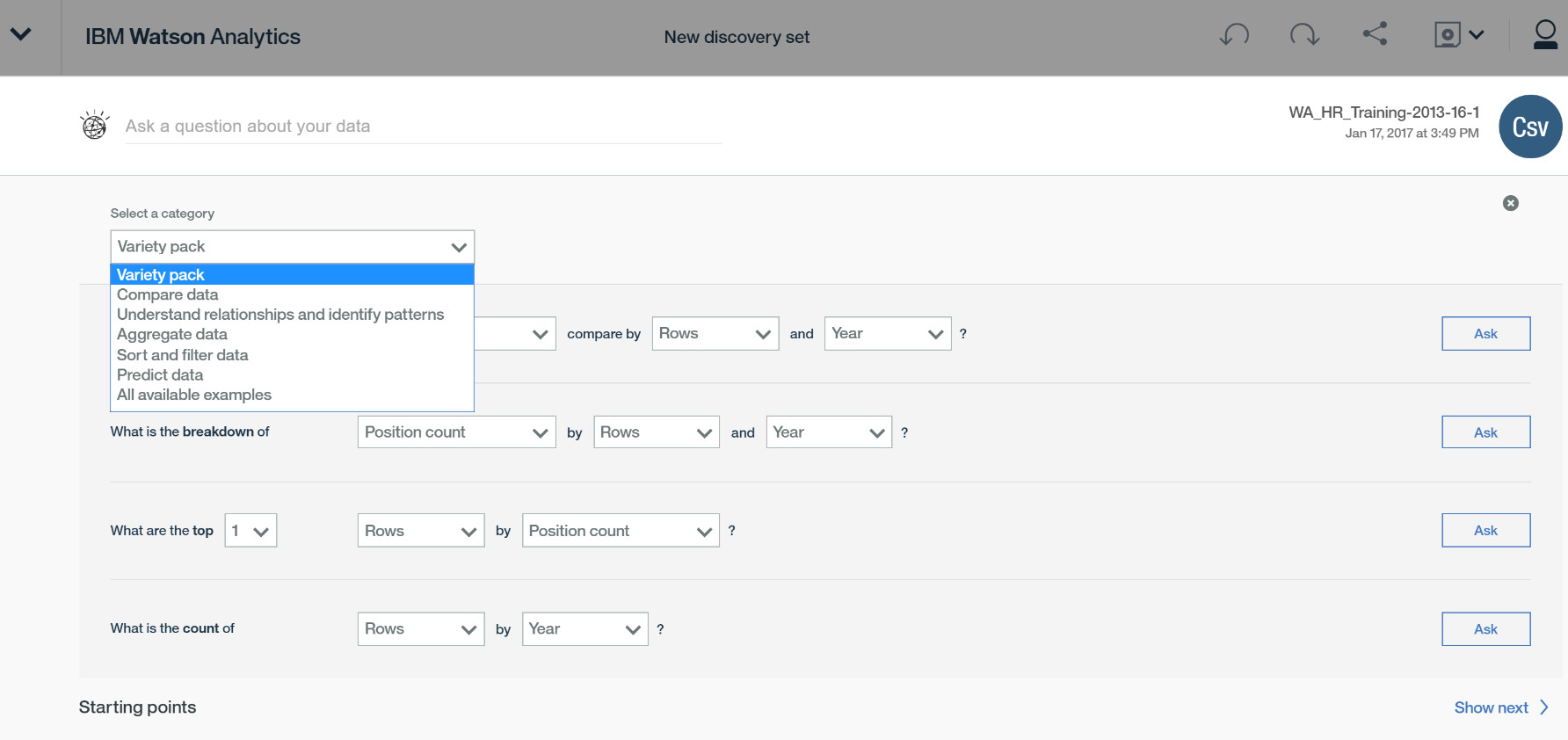
比如说 Aggregate data
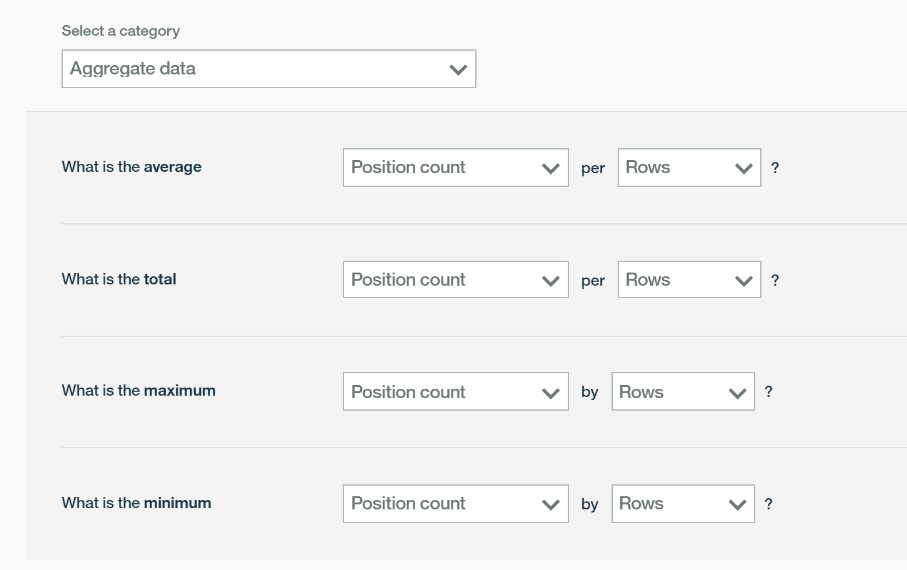
每一个问题都可以调整分析的维度和事实,每一个问题只要点击一下 ASK,整个的分析也就自动完成了。
IBM Watson Analytics 分析问题的逻辑
通过上面的简单介绍,大家基本上能够发现我们在对这份测试数据分析的时候,大部分的我们所想要的分析已经由 IBM Watson Analytics 已经帮我们完成了,每一个问题就对应这一个分析结果,如何做到的?
回到我之前列出来的数据,很显然 IBM Watson Analytics 在数据上载的阶段就已经完成了对数据的分析。IBM Watson 通过数据列的值对分析数据的角度(即维度)和分析的目标数据(即度量值或事实)进行了解析和自动建模处理。
自动对维度和事实进行分组 - 数值型的自动变为分析的事实。
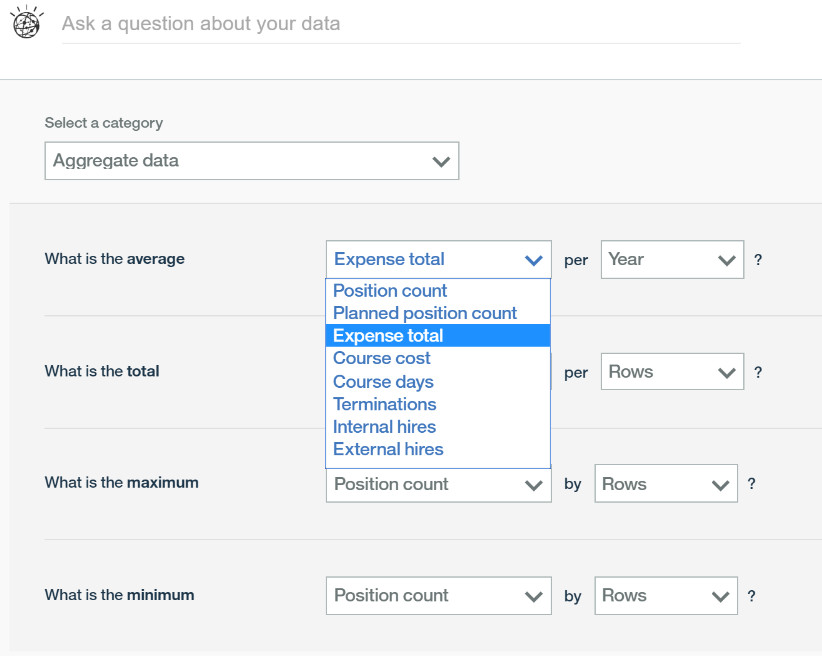
自动对维度和事实进行分组 - 字符或字符串类型的数据自动解析为维度。
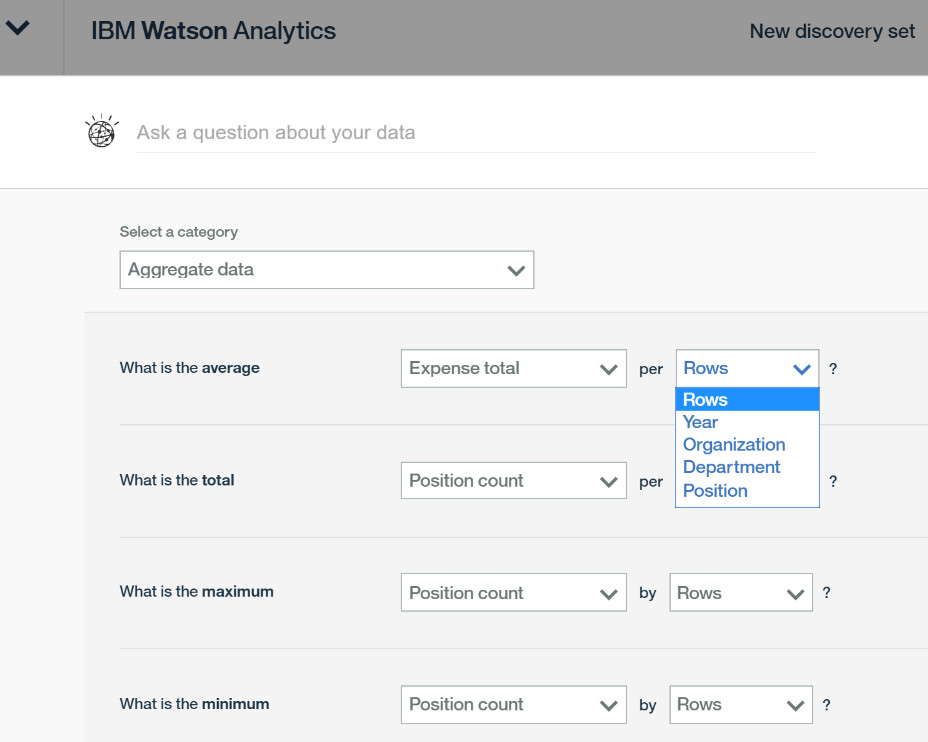
很多数据分析工具能够自动的区分维度和事实,但是 Watson Analytics 在这个层面上更进了一步。Watson Analytics 不仅自动的对维度和事实进行划分,同时“猜想”了人们可能要用到的所有分析角度和事实组合,而这些组合可以直接的通过 Question 呈现给用户选择。
维度和事实建模分析三个发展阶段
1. 先设计好分析模型再分析和呈现。2013年以前使用传统的 BI 分析或报表工具(IBM Cognos、SAP BO、Oracle BIEE、Microsoft SSRS 等)大都需要预先建好数据仓库,在数据仓库建模的过程中我们需要自己设计维度表、事实表,还要考虑到性能和开发流程的问题,才有了 inmon kimball 之争。
2. 在分析和呈现过程中来建模。例如 Tableau、Qlik(QlikSense)、Power BI、Ptmind DataDeck、永洪、Smartbi、帆软、ETHINKBI 等产品不再严格考虑数据仓库建模的问题,具体表现就是可以基于基础数据直接将字段拖放到维度和事实面板,分析结果自动呈现。
3. 数据上载完成即建模完成,分析结果可及时呈现。IBM Watson Analytics 处于这个阶段。有一部分细分领域的产品也符合这一点,比如固定了数据模型的接口,按照接口上载数据,已经固化的分析报表和结果即可呈现。但区别就在于 IBM Watson Analytics 并不会预先固定好数据分析模型和分析报表,也不会预先固定了数据模型的接口,而是根据上载的数据对建模和分析进行随时调整。
上面是对 How to ask a question 的过程进行了一些解析,接下来我们再来看看 IBM Watson Analytics 所展现出来的对自然语言的分析和认知能力。
IBM Watson Analytics 自然语言的分析和认知能力
关于自然语言的分析,业务人员可以直接通过自然语言的输入来获得 Watson 的回答,比如我输入了一句:I want to know course cost of departments ,我想知道每个部门的课程成本。其实要分析就是想看看每个部门在培训课程中的花费,哪些部门花费的比较高,大概是因为哪些原因,但这些问题可能还不是非常具体。英文的问题可能也比较随意和含糊,也不用特别去考虑英文的语法。
接着之前的页面在输入这句话后回车,IBM Watson Analytics 就会返回一些与这个问题可能相关的很多提示,这就是 Watson 的自然语言处理和认知能力。每个问题对应的又是一个分析的结果,即提出问题,分析呈现就已经完成。
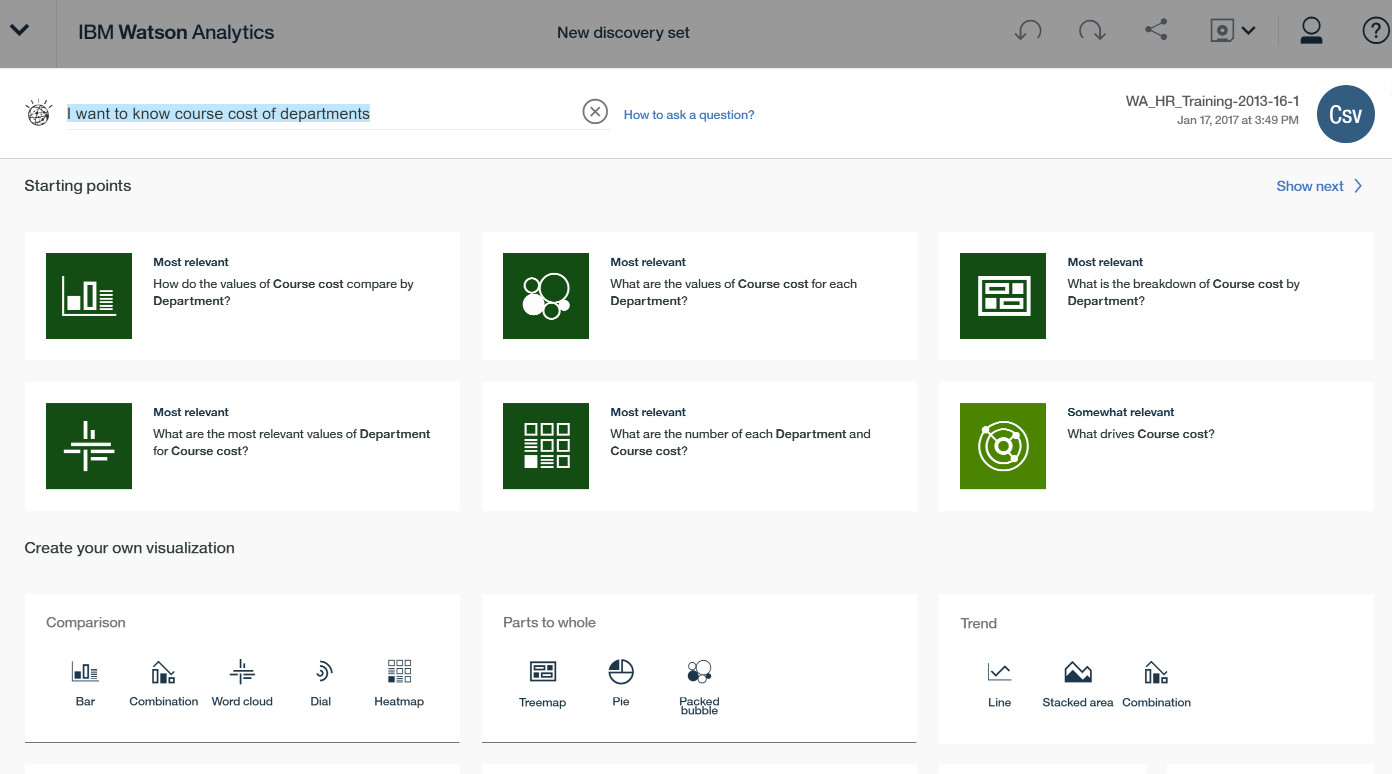
这种场景我们经常遇到:很多的业务人员可能只是根据工作经验和自身的业务能力有一个想法,提出的要分析的问题也不是非常明确。数据分析师或者 BI 开发人员在跟业务人员沟通的时候,往往都希望得到一个非常明确的分析需求,这就是一种矛盾。
但现在业务人员通过 ASK A QUESTION 的时候就可以获得 Watson 给出的更加具体的提示,也有可能这些提示当中就会把业务人员想问但是不知道怎么问的问题给呈现出来,也可能是之前没有想到的问题也给呈现出来了,这就是 Watson Analytics 打造的一种分析场景。
这种场景就是普通的业务人员不需要专业的分析背景知识,借助于 IBM Watson 的认知能力,也可以一步一步完成基础的数据分析工作。一旦业务人员逐步养成了这种数据探索习惯,随着数据思维意识的逐步提高,业务人员和专业分析人员的沟通成本会越来越低。对于同一个问题大家达成的共识会越来越清晰,这种数据意识的提高和沟通的正向循环将带给企业不可想象的价值。
按我的想法,IBM Watson Analytics 给出的这个提示 “What are the values of Course cost for each Department? ” 很符合我想问的问题,即每个部门的培训成本。

点击这个问题,Watson Analytics 将自动为我们呈现分析的结果 - Sales 部门的培训课程成本最高。
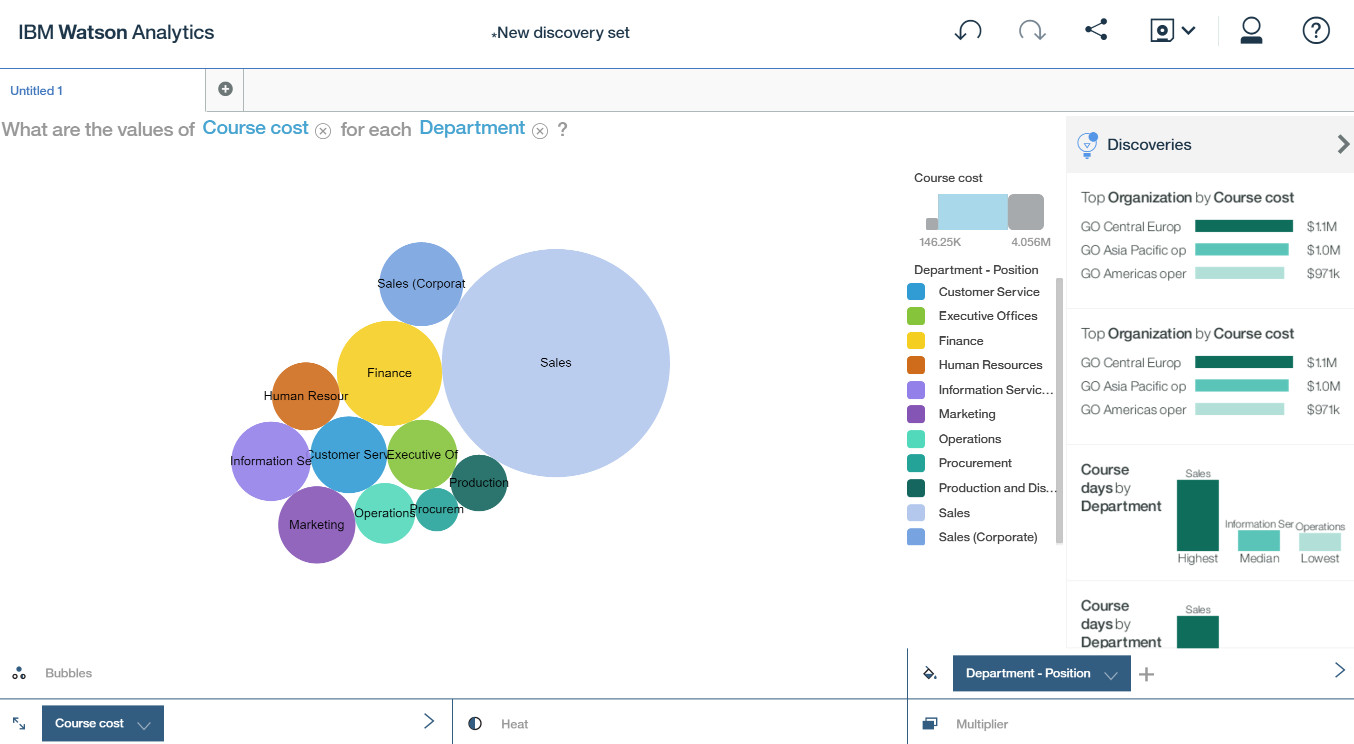
但最后想起来想问的是 Expense Total,那么可以点击 Course Cost 很灵活的将它换成 Expense Total。
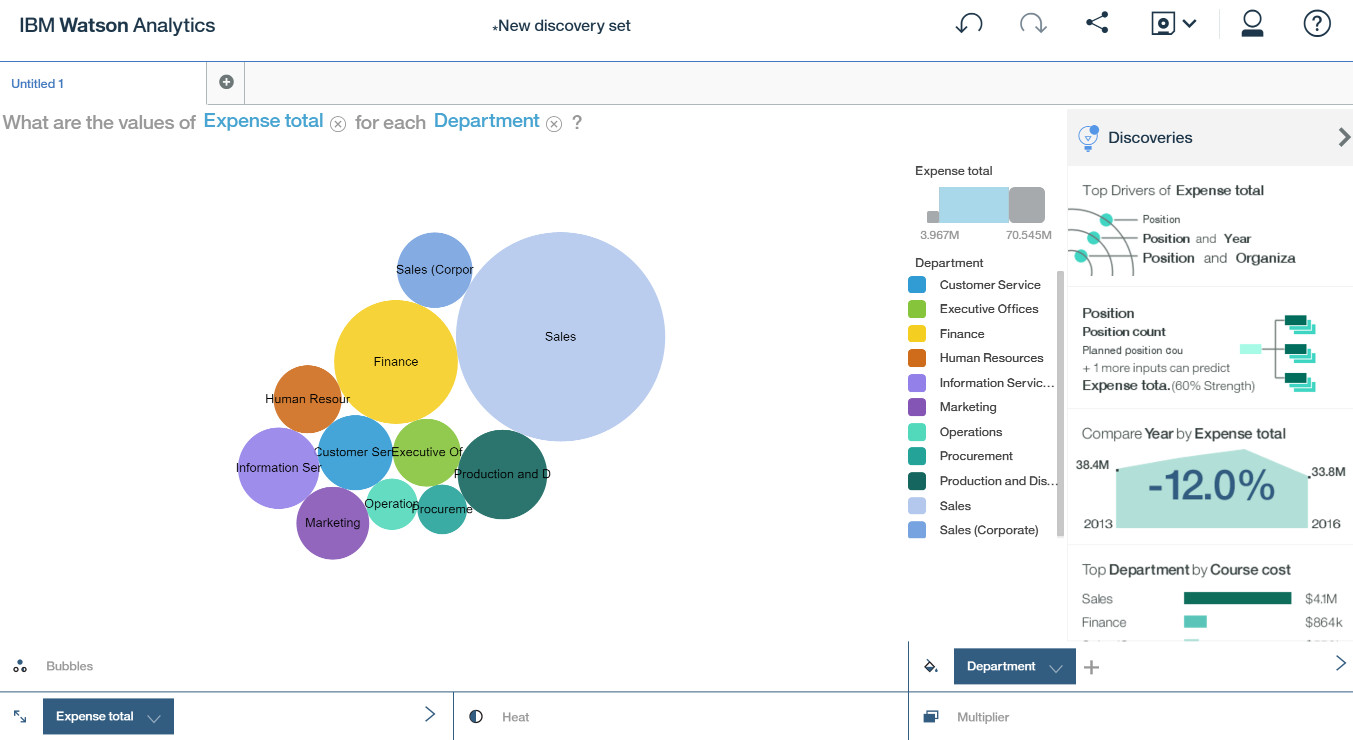
在实际的分析过程中,我们通常会一个接一个的抛出另外的问题,要探索究竟。比如,这里的分析结果可以展示出哪些部门的培训花费最高,比如 Sales、Finance 部门。但接着可能更想知道的是为什么花费要哪么高,是哪些问题导致的呢? 有些原因我们可能可以根据一些日常的经验来判断,比如职位越高的培训费用就越高,比如不同的部门、培训时间天数、培训涨价了等等,但到底哪些因素重点影响了这些结果 ?
遇到这些问题业务人员如何来解决? 数据分析师该如何解决? 提出假设再分析再验证? 验证完了再分析? 这个过程会相对漫长。对业务熟悉对数据熟悉,分析和判断的方向可能是对的,如果不熟悉不敏感,这个方向可能就是错误的。
IBM Watson Analytics 很好的解决了这一点,在该分析结果的右侧区域 Discoveries 自动给出了一些探索式预测分析结果,而这一切不需要任何的具体操作。
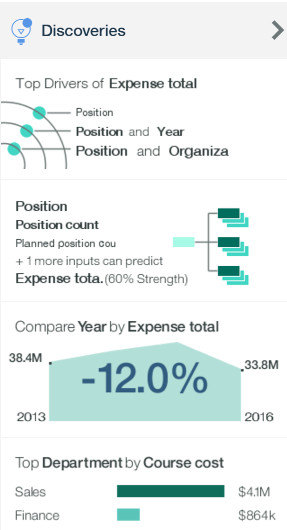
点击 Top Drivers of Expense Total ( 驱动/改变/导致/影响 Expense Total 变化的最高的几个因素或者原因),这时问题就变成了 What drives Expense total ?
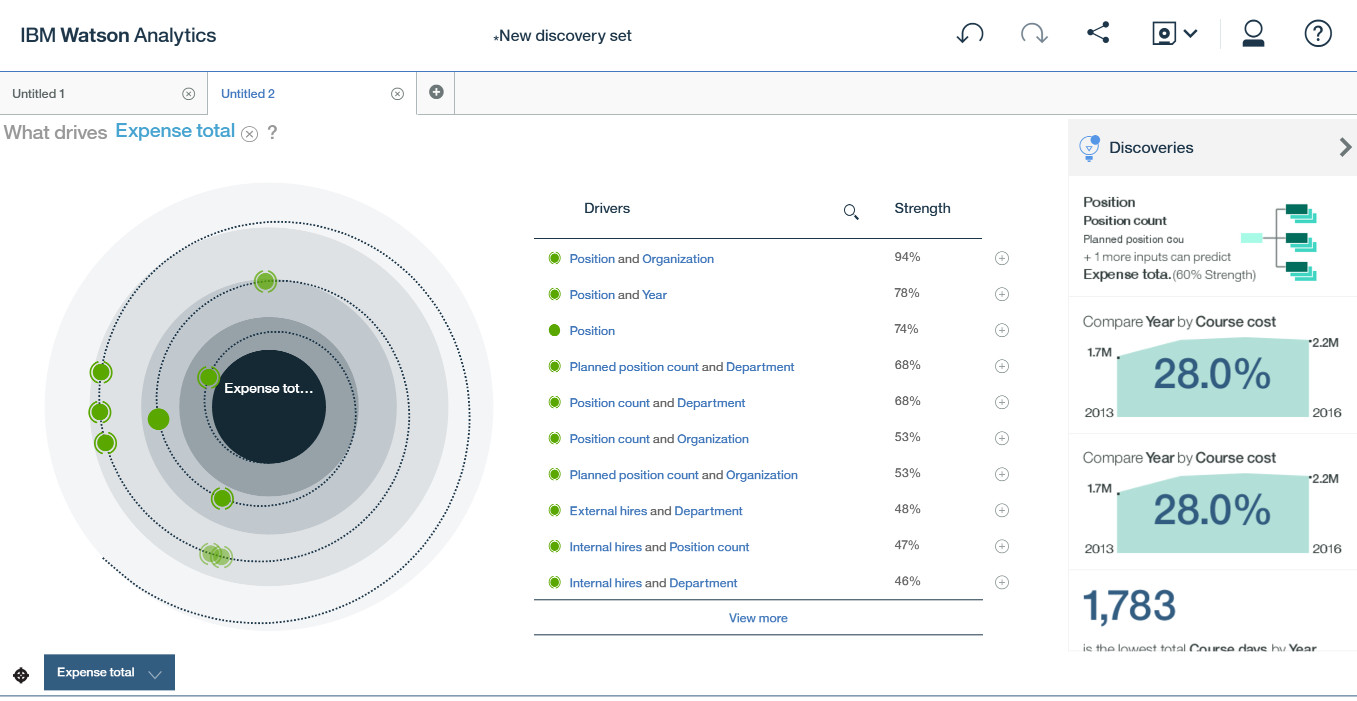
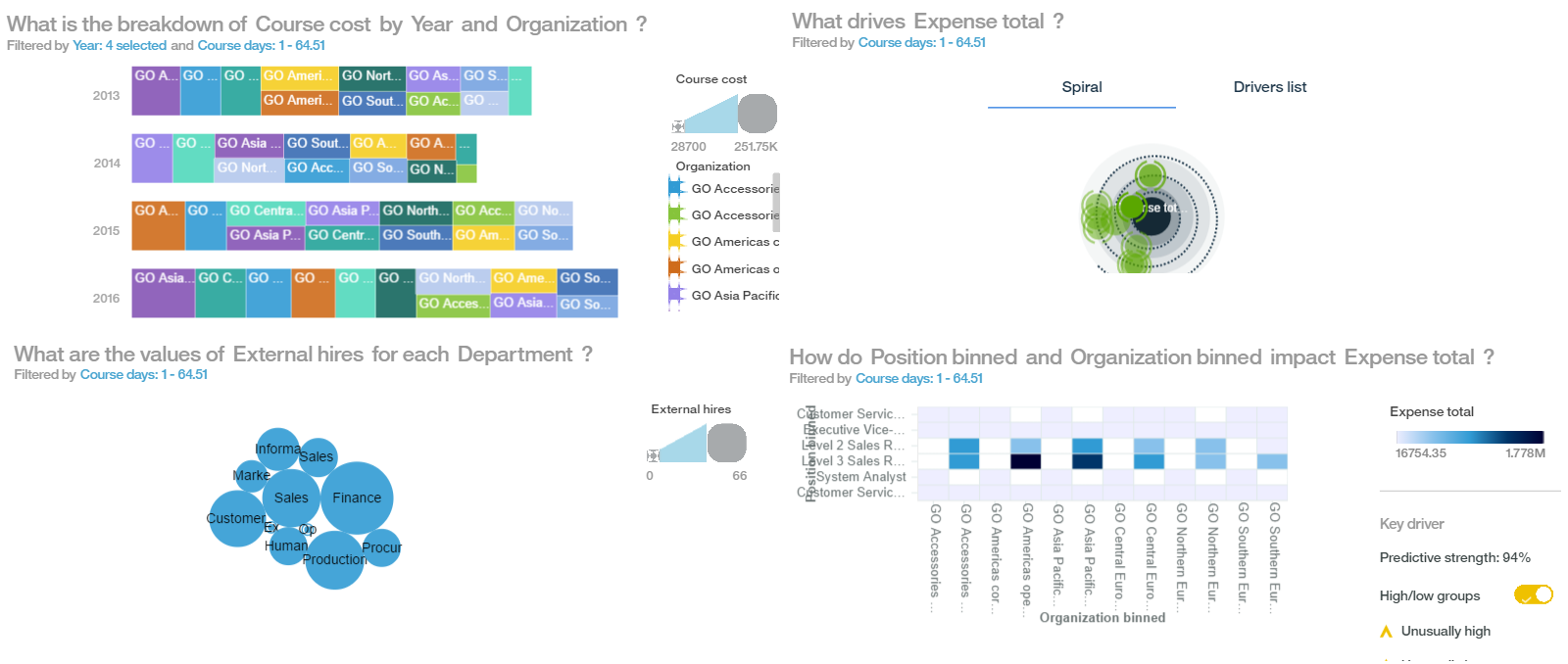
左侧的螺旋图中,越靠近中间点的维度越说明了它们对 Expense Total 影响越大。从这个图中可以看出 Position 职位和 Organization 组织的双向组合对 Expense Total 总花费越大,也就是说 Expense Total 总花费受职位和组织影响最大。
我们还可以点击 Position and Organization 旁边的 + 号对这一点进行更进一步细致的分析,这时问题就变成了 How do Position binned and Organization binned impact Expense Total ? 职位和组织是如何影响 Expense Total 总花费的,颜色的深浅告诉了我们哪些组织的哪些职位 Expense Total 总花费最大。
比如这里看到的在横轴上 Level 2 Sales Representative 和 Level 3 Sales Representative 销售代表他们的培训消费最高,同时也可以看到与之交汇的组织是 GO Central、GO Asia Pacific、GO Americas。
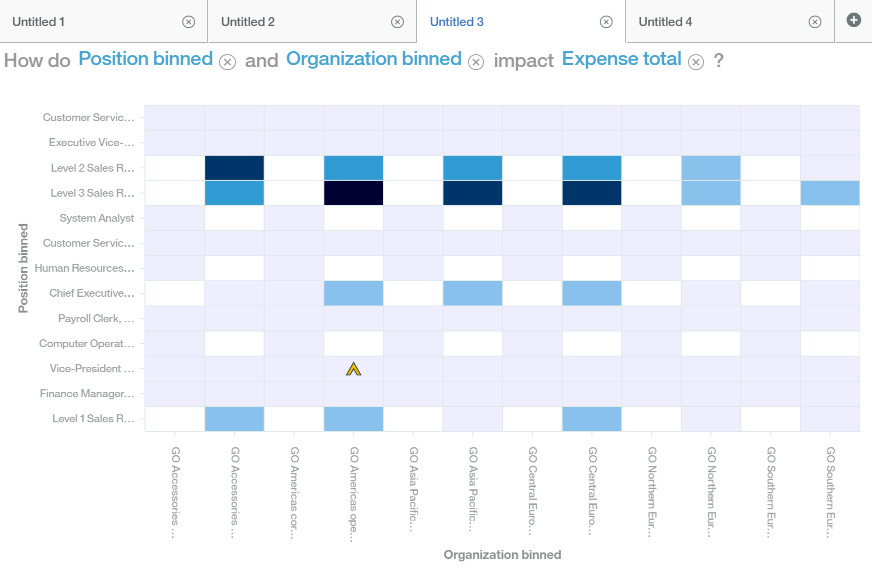
这些问题还可以继续分析下去,整个过程不需要做任何的编程和手工拖拉拽维度和事实,所有的分析非常自然的由 Watson Analytics 给呈现出来。
回顾这个简单的分析流程
1. 各个部门培训课程的成本,通过自然语言提问,Watson 给出了我想要的问题,一次点击就呈现了分析的结果。
2. 之后发现我还想了解各个部门培训的总消费(实际消费),很自然的切换了一个字段我找到了所要的分析结果。
3. 其次,相对这个结果做深入分析,想看看这个总消费为什么这么高,受哪些因素影响最大、为什么,我通过 IBM Watson Analytics Discoveries 小面板也找到了答案。
这个逻辑是我们最简单的一个分析问题、思考问题和寻找答案的一条再清晰不过的逻辑。我们可以试想一下,利用我们手边的工具、纸笔、SQL 查询、报表分析工具,我们大概需要多长的时间来从一层逻辑来打通到另外一层逻辑,并且中间还需要层层验证逻辑推理的正确性和合理性。
但是在使用 IBM Watson Analytics 的过程中,我的逻辑猜想和逻辑实现就是三次点击,这就是 IBM Watson 的强大之处,也是人工智能认知计算的魅力。
最后可以将刚才几个相关的分析结果重命名保存到一个文件夹中,比如 Personal,同时回到 IBM Watson Analytics 主页点击 Display。
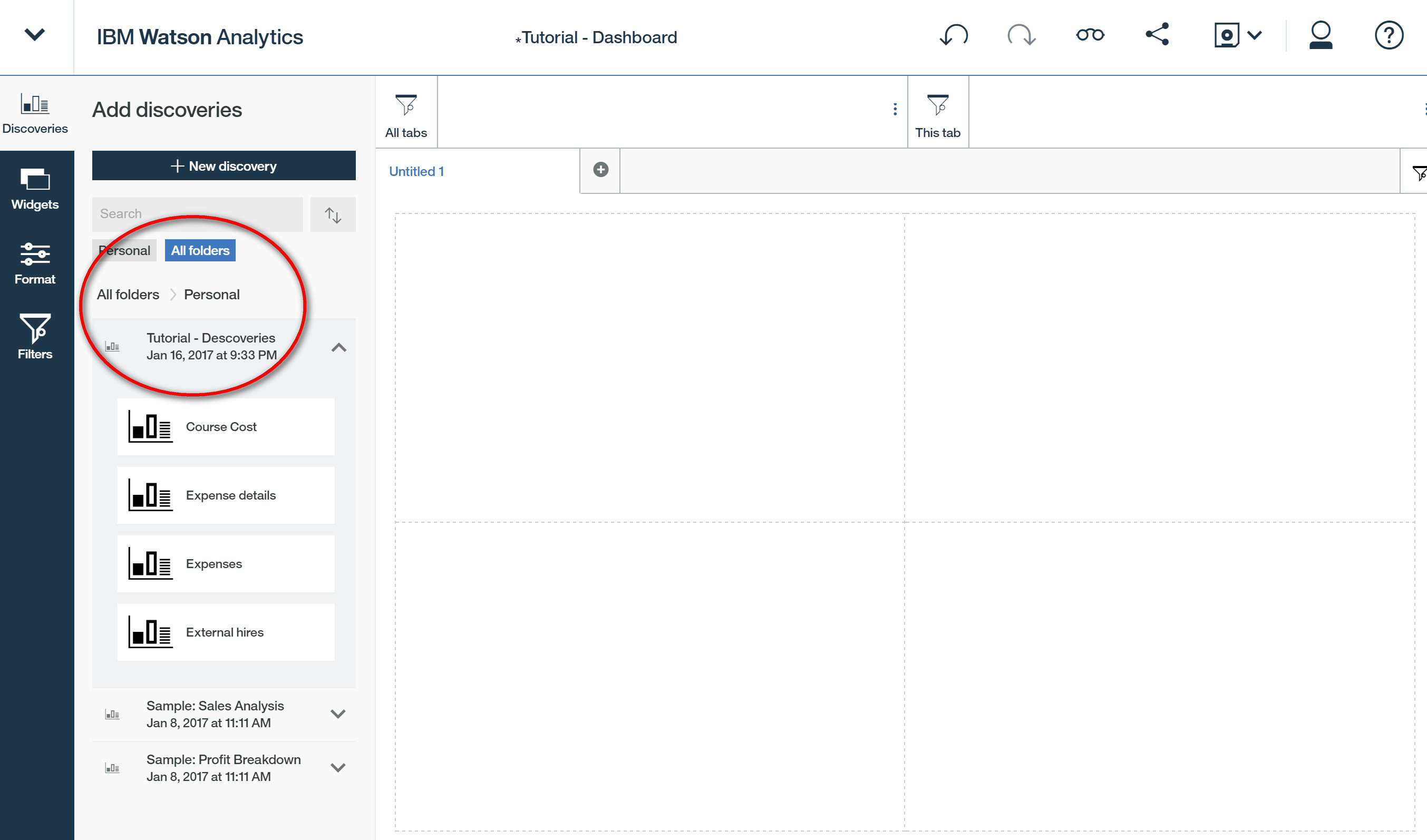
新建一个 Display 显示选择一种布局方式以及找到刚才保存的分析结果。
把分析的结果放到不同的面板中保存下来。
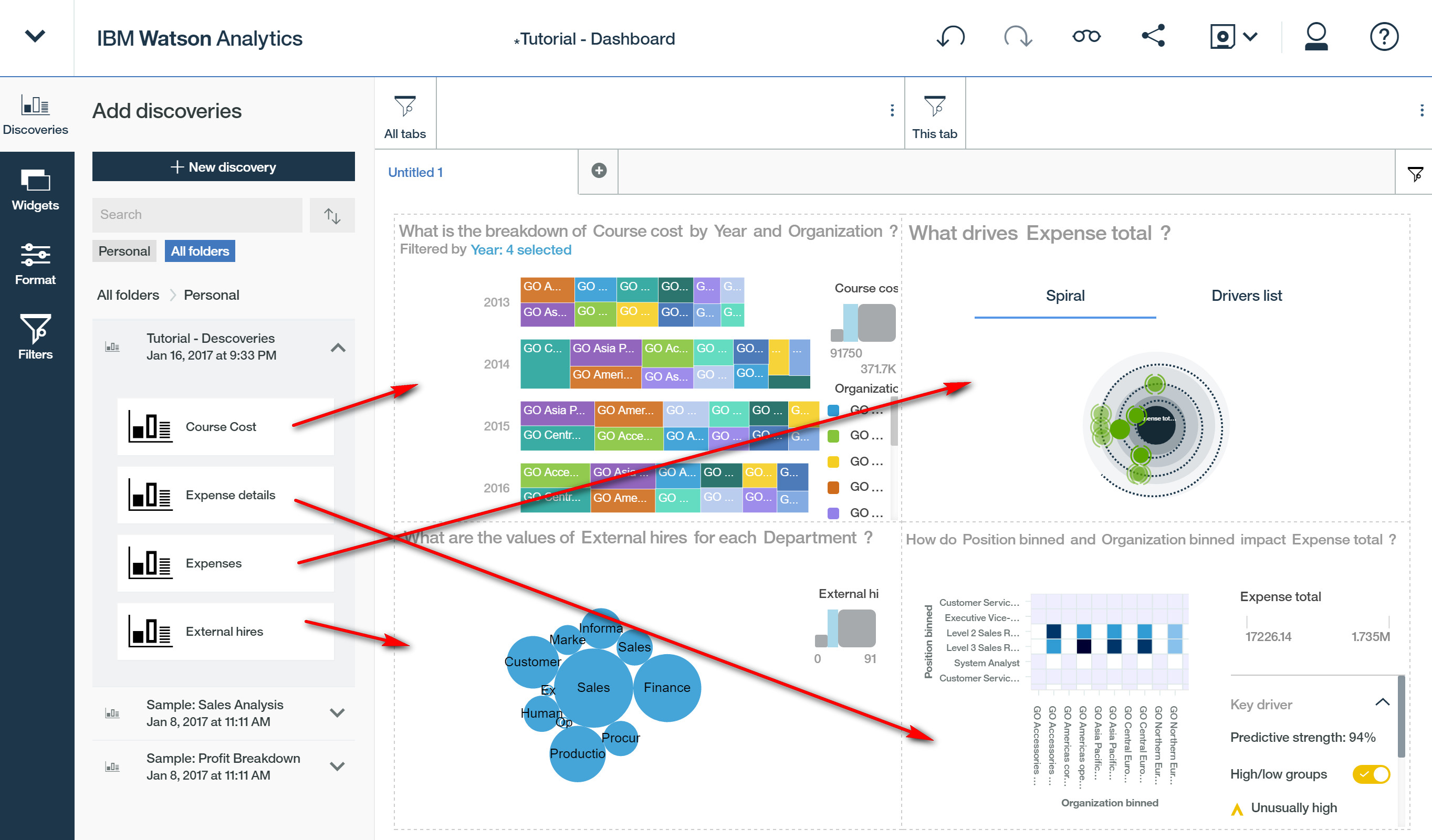
在展示版块,我们随时可以看到我们保存的数据分析结果,还可以做很多筛选过滤等操作。
最后可以对这些分析结果进行分享,分享的选择也很多。

对于分析结果,发送邮件可以使用图片的格式,也可以是 PDF 或者 PowerPoint 的形式。
收到邮件的效果
附件中的图片
至此,整个对于 IBM Watson Analytics 的试用体验就正式完成了,整个分析的过程不超过 10 分钟。当然还有很多需要去研究的细节,可以帮助我们完成更多更深入和精细的分析,这还需要对 IBM Watson Analytics 做进一步的研究和深入体验。
IBM Watson Analytics 适合使用的人群
1. 普通的业务人员,不需要专业的数据分析背景,通过对 Watson 的提问和 Watson 给出的引导就可以展开分析的工作。
2. 数据分析和数据挖掘工程师,IBM Watson 会给出关于同一问题的不同分析角度,这对大家分析和思考问题是一个很好的补充。同时,专业的数据挖掘和分析素养和对数据的意识,可以让大家对 IBM Watson Analytics 驾驭的更好。
IBM Watson Analytics 需要改善的地方
1. 目前通过试用发现 IBM Watson Analytics 对中文的支持还是不够,缺乏中文本地化的展现界面,提问环节所展现的结果是中英文混杂的。这一点如果能够解决,相信还是降低了不少的使用门槛。但是,中国文化博大精深,汉语言文化丰富多彩,类似于“冬天:能穿多少穿多少; 夏天:能穿多少穿多少。”这样的自然语言处理也很期待 IBM Watson Analytics 的表现。
2. 由于 IBM Watson 云在国外的缘故,导致在实际的分析和操作过程中页面加载有一定的延迟,最后通过 VPN 链接完成了整个产品试用的过程。
IBM Watson Analytics 试用总结
虽然有很多功能可能并没有使用到,但是目前体验到的功能还是给我留下了比较深刻的印象。在数据分析的整个过程中不需要任何 IT 人员的引导、也不需要特定的数据分析背景,这应该就是 IBM Watson Analytics 对自己的一个定位。
一个好的产品设计需要很多人性化的思考,IBM Watson Analytics 在这些方面做的很好。Watson Analytics 对人们考虑问题和分析问题、分解问题的逻辑梳理的比较清晰,通过一步一步的提示、引导、相关性的分析展示让人的逻辑在 Watson Analytics 的使用过程中得到了很好的补充和延续。
当然,越让人觉得使用简单的产品,背后所隐藏的技术实现和为此所做出的努力就越大。
(全文完,作者:吕品,天善智能联合创始人&运营总监,微信号:tianshanlvpin)
附件含测试数据,可下载使用。
本文原创,如需转载,请注明以下信息:
本文由天善智能原创,原文链接:https://ask.hellobi.com/blog/lvpin/6065


