昨天的博客介绍了一下所有的技术场景基于PostgreSQL的流式计算数据库PipelineDB--技术应用场景
今天主要测试一下,continuous view和基本的流数据复制功能。
注意PipelineDB是没有事务概念的,这个一定要记住。
如果用其他工具去连可能不要选择autocommit选项,我用dbvisualizer就不能选这个。
准备表和stream
create stream test_stream (n_id int, project text, view_count bigint);
create table test_tgttable1 (n_id int, project text, view_count bigint);
create table test_tgttable2 (n_id int, project text, view_count bigint);
continuous function
create continuous view test_stats as
select project,count(*) as total_pages, sum(view_count) as total_views
from test_stream group by project;
continuous transform
--continuous function
create or replace function insert_testtgttable1()
returns trigger as
$$
begin
insert into test_tgttable1(n_id,project,view_count) values (new.n_id, new.project,new.view_count);
return new;
end;
$$
language plpgsql;
create continuous transform test_ins_testtgttable1 as
select n_id::int, project::text, view_count::bigint from test_stream
then execute procedure insert_testtgttable1();
验证结果:
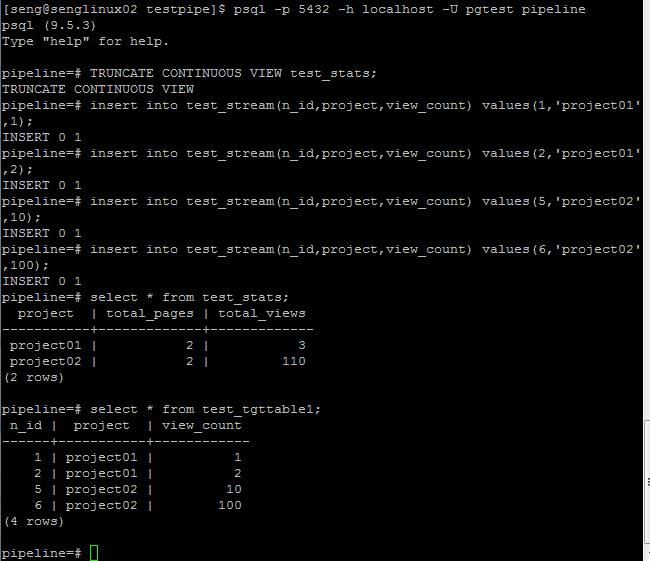
触发流的更多语句:
--多值, 不过这个我觉得没什么用^-^
INSERT INTO test_stream(n_id,project,view_count) values(11,'project03',11),(12,'project03',22);
--从其他的表insert
INSERT INTO test_stream(n_id,project,view_count) SELECT n_id,project,view_count FROM test_tgttable2;
--从文件导入 ,这个最有用了
COPY test_stream(n_id,project,view_count) FROM '/postgre/workfiles/filetest01.csv';
--这是官方文档的示例, 用命令行就可以集成了数据了,很方便
curl -sL http://pipelinedb.com/data/wiki-pagecounts | gunzip | \
psql -h localhost -p 5432 -d pipeline -c "
COPY wiki_stream (hour, project, title, view_count, size) FROM STDIN"
PS.
今天把<白说>看完了,不过就前面几章不错,还是推荐去看看。
今天开始看<上帝掷骰子吗:量子物理史话>,都是在kindle上看的,看书比较杂.^-^

