天气逐渐寒冷,觉得应该给自己添加几件保暖的衣服了,于是想到了天猫,搜寻了一番,觉得南极人的保暖内衣还是不错的。到低怎么选择这么多的衣服呢?我一般选择按销量排序,毕竟销量也能侧面反映商品的受欢迎度和口碑状况,所以我来到了这个页面https://list.tmall.com/search_product.htm?spm=a220m.1000858.1000724.4.8qg2Js&cat=50025983&brand=107380&q=%C4%CF%BC%AB%C8%CB%B1%A3%C5%AF%C4%DA%D2%C2&sort=d&style=g&from=.list.pc_1_suggest&suggest=0_1#J_Filter,

接着点进去后,发现有非常多的历史累计评价,于是我一条条的查看,一页页的翻,觉得口碑还是非常不错的,于是选择这款商品。我想大家可能也是这样的购物模式,也许还可能更加复杂(货比三家,口碑比较,联系卖家......)。
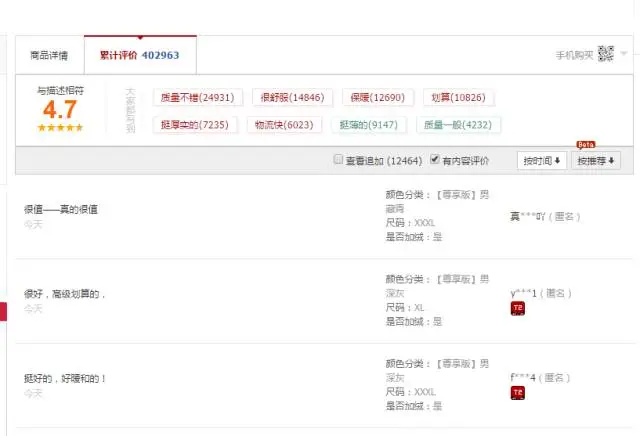
如果有一天,我想研究这些个评论数据,然后玩玩高大上的自然语言处理,我是不是该把这些评论复制下来拷贝到一张大表里呢?虽然可以这么做,但总觉得效率有点低(相比于爬虫不是低一两个量级哦~)。如果你会爬虫的话,你就会感受到自动化给你带来的兴奋,接下来我们就研究研究如何使用Python对天猫的评论数据进行抓取。
按照常规出牌,发现然并软。。。。
一般常规是这样进行的,在上面的评论页中,右击选择“查看网页源代码”,于是代码是长这样的:

我想搜一下原始网页中有一条评论“很好,高级划算的”这句话在源代码的什么位置,非常不幸的是,当我按下Ctrl+F,并输入“很好”,尽然没有这样的字眼。。。难不成我抓不了天猫网站的评论数据了?No,方法还是有的,只不过不能出常规牌了,因为天猫的评论数据是异步存储在其他地方的。
非常规方法,两眼发光!
在评论页面,我们按一下F12(我用的是Chrom浏览器)那个键,于是出现了这个:
也许你的页面布局是上下两部分,而且下半部分什么也没有,这个时候你需要做两件事:1,选择Network底下的JS部分,因为天猫的评论数据是异步存储在一个JS连接里面的;2,刷新页面,找到一个叫“list_detail_rate“开头是文件。当你打开这个文件后,它是长成这样的:
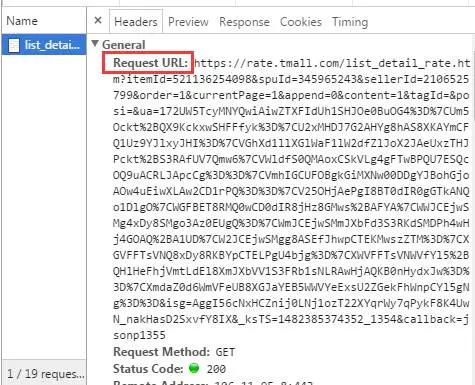
你会发现有一个请求连接,接下来你只需要将这个链接复制下来,并在浏览器中粘贴这个地址,你就会发现,原来这些评论隐藏在这个地方啊。。。
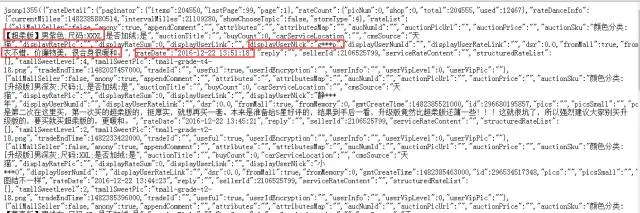
哈哈,接下来我们就可以通过正则表达式,把类似于红框中的信息抓取下来(用户昵称,评论时间,购买的套餐,衣服尺寸,评论内容)。你可能还会问一个问题,你这个页面里也只是装的一页的评论信息,如何把所有页面的评论信息全部抓下来呢?我们发现一个规律,那个复制下来的连接可以总结为这种形式:https://rate.tmall.com/list_detail_rate.htm?itemId=521136254098&spuId=345965243&sellerId=2106525799&order=1¤tPage=1,可以每次更换最后的currentPage值就可以抓取出不同页的评论信息了。
爬虫知识:
requests模块:
get方法向对方服务器发送一个url请求;
text方法可以将get请求的回应转换为文本的字符串格式;
re模块:
findall函数借助于正则表达式在文本中寻找所有匹配的结果,语法格式:
findall(pattern,string,flags)
pattern接受一个正则表达式对象;
string接受一个需要处理的字符串;
flags接受一个模式参数,如是否忽略大小写(flags = re.I);
上菜:
# 导入所需的开发模块
import requests
import re
# 创建循环链接
urls = []
for i in list(range(1,100)):
urls.append('https://rate.tmall.com/list_detail_rate.htm?itemId=521136254098&spuId=345965243&sellerId=2106525799&order=1¤tPage=%s' %i)
# 构建字段容器
nickname = []
ratedate = []
color = []
size = []
ratecontent = []
# 循环抓取数据
for url in urls:
content = requests.get(url).text
# 借助正则表达式使用findall进行匹配查询
nickname.extend(re.findall('"displayUserNick":"(.*?)"',content))
color.extend(re.findall(re.compile('颜色分类:(.*?);'),content))
size.extend(re.findall(re.compile('尺码:(.*?);'),content))
ratecontent.extend(re.findall(re.compile('"rateContent":"(.*?)","rateDate"'),content))
ratedate.extend(re.findall(re.compile('"rateDate":"(.*?)","reply"'),content))
print(nickname,color)
# 写入数据
file = open('南极人天猫评价.csv','w')
for i in list(range(0,len(nickname))):
file.write(','.join((nickname[i],ratedate[i],color[i],size[i],ratecontent[i]))+'\n')
file.close()
最终呈现的爬虫结果如下:

今天的爬虫部分就介绍到这里,本次的分享目的是如何解决网页信息的异步存储。在之后的分享中我将针对这次爬取的评论数据进行文本分析,涉及到切词、情感分析、词云等。
每天进步一点点2015
学习与分享,取长补短,关注小号!

长按识别二维码 马上关注
