1.爬虫系统设计
1.1总体概览
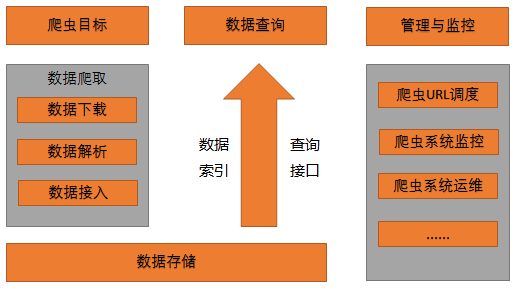
1.2模块划分
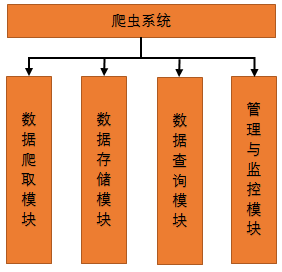
1.2.1数据爬取模块
 HttpClient进行html页面下载
HttpClient进行html页面下载
 HtmlCleaner+ Xpath
HtmlCleaner+ Xpath
Jsoup
正则表达式
 JDBC接入方式
JDBC接入方式
mongo-java-driver接入方式
HDFS/HbaseAPI 接入方式
1.2.2 数据存储模块
JDBC接入存储到传统数据库,如PG,GP
mongo-java-driver接入存储到MongoDB
HDFS/Hbase API 接入存储数据到Hadoop,根据业务应用情况,选择对应的数据接入方式和存储。
1.2.3 数据查询模块
全文检索
后台接口
第三方查询工具
1.2.4管理与监控模块
 redis创建URL仓库,队列优先级调度
redis创建URL仓库,队列优先级调度
 Ganglia、Zookeeper
Ganglia、Zookeeper
 邮件提醒
邮件提醒
2.开发部署规划
优先开发数据爬取和存储模块,数据查询和管理监控模块可选或二期开发。
2.1代码模块
spider.entity 存储实体
spider.service 爬虫接口
sipder.service.impl
sipder.entry 执行入口
sipder.crontab 爬虫调度
sipder.solr 数据查询
sipder.mail 邮件提醒
sipder.zookeeper 爬虫监控
spider.util 公共类
2.2部署
一期单机:爬虫项目
二期集群(至少3台):
redis集群服务,开源
solr集群服务,开源
zookeeper集群服务,开源
爬虫项目
其他软件部署:待定
3.设计难点
网站反爬策略,主要是访问用户限制,访问请求携带浏览器中相关信息;减缓爬取频率,如10s抓取1次;
网站模板变动,使用配置文件,如果模板变更,则对应更改配置项,或者将规则保存到数据库,实时更改数据库信息
网站URL抓取失败,httpclient默认的方式(失败URL重试3次);将失败URL重新加入到抓取队列,失败3次后停止抓取
频繁抓取IP被封,采用IP代理库,随机使用IP去抓取;部署多个爬虫应用;降低爬取频率
