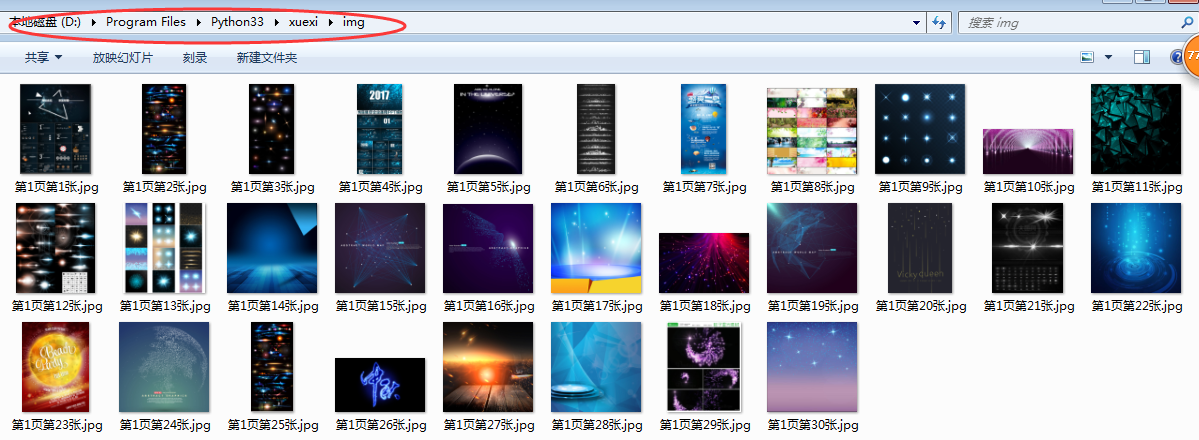
爬取千图网星空频道的图片
import urllib.request
import urllib.error
import re
#浏览器伪装
headers=("User-Agent","Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:49.0) Gecko/20100101 Firefox/49.0")
opener=urllib.request.build_opener()
opener.addheaders=[headers]
#opener设置为全局
urllib.request.install_opener(opener)
for i in range(1,2):
try:
url="http://www.58pic.com/tupian/xingguang-0-0-"+str(i)+".html"
data=urllib.request.urlopen(url).read().decode("utf-8","ignore")
pat='"(http://pic.qiantucdn.com/.*?)!qt226"'
imagelist=re.compile(pat).findall(data)
for j in range(0,len(imagelist)):
this_image_url=imagelist[j]
#保存位置设置
file="D:/Program Files/Python33/xuexi/img/第"+str(i)+"页第"+str(j+1)+"张.jpg"
urllib.request.urlretrieve(this_image_url,filename=file)
#异常处理
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
爬取保存结果: