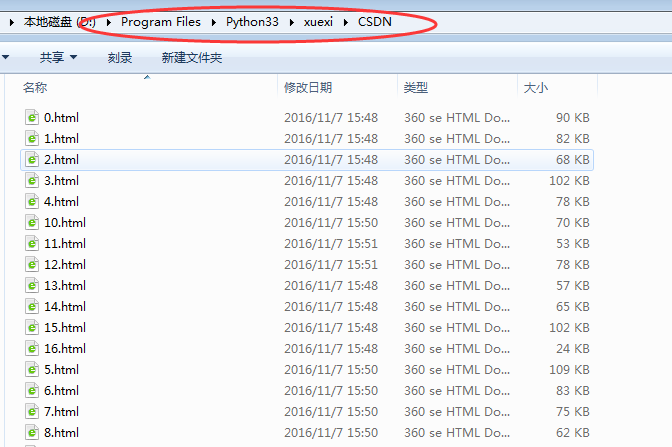
1、方法一:for循环里添加报头伪装成浏览器爬取
import urllib.request
import re
import urllib.error
url="http://blog.csdn.net/"
#设置报头,chrome浏览器伪装
headers=("User-Agent","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36\
(KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36")
#添加报头
opener=urllib.request.build_opener()
opener.addheaders=[headers]
#读取url
data=opener.open(url).read()
#解码
data=data.decode("utf-8","ignore")
#正则
pat='<h3 class="tracking-ad" data-mod="popu_254"><a href="https://ask.hellobi.com/(.*?)"'
allurl=re.compile(pat).findall(data)
for i in range(0,len(allurl)):
try:#异常处理
print("第"+str(i)+"次爬取")
thisurl=allurl[i]
#添加报头、读取url
opener1=urllib.request.build_opener()
opener1.addheaders=[headers]
data2=opener.open(thisurl).read()
#打开文件,赋给句柄
fh=open("D:/Program Files/Python33/xuexi/CSDN/"+str(i)+".html","wb")
fh.write(data2)
fh.close()
print("-----------成功------------")
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
2、方法二(韦玮老师讲解):opener设置为全局
import urllib.request
import re
url="http://blog.csdn.net/"
#设置报头
headers=("User-Agent","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36\
(KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36")
#添加报头
opener=urllib.request.build_opener()
opener.addheaders=[headers]
#opener设置为全局
urllib.request.install_opener(opener)
#读取url
data=urllib.request.urlopen(url).read().decode("utf-8","ignore")
data=opener.open(url).read()
#解码
data=data.decode("utf-8","ignore")
#正则
pat='<h3 class="tracking-ad" data-mod="popu_254"><a href="https://ask.hellobi.com/(.*?)"'
allurl=re.compile(pat).findall(data)
for i in range(0,len(allurl)):
#异常处理
try:
print("第"+str(i)+"次爬取")
thisurl=allurl[i]
file="D:/Program Files/Python33/xuexi/CSDN/"+str(i)+".html"
urllib.request.urlretrieve(thisurl,file)
print("-----------成功------------")
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
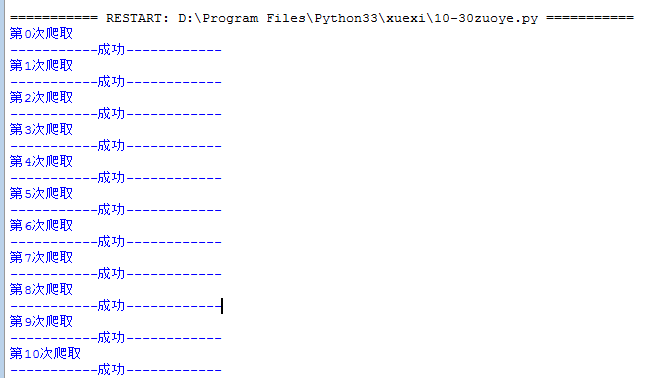
运行如下:
保存文件