天善的博客系统有个bug 只能存一份草稿....
首先申明我不是技术大牛,只是一个奋斗在一线的BI实施人员。做过几个DW相关的相关的项目,前不久有个项目客户要求对DW的各层给出准确的解释,借着这个机会总结下我所认识的DW,总结不对的地方欢迎拍砖指教。
DW是是1990年w.h.inmon提出的,定义是:面向主题的,集成的,稳定的,随时间变化的数据集合,用于支持管理决策过程。 DW是属于BI的一个子集,BI(Business Intelligence)是将与企业有关的数据包括内部数据,外部数据等转化成有用信息,形成竞争力的过程。结构如下:
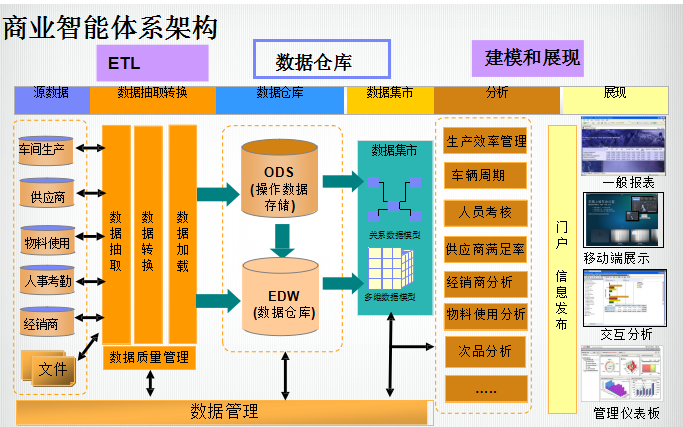
数据仓库主要包括:源端数据,ETL,ODS,DW,数据集市
源端数据:
对企业有价值的数据都可以称作源端数据,主要是企业OLTP系统产生的数据。但在大数据时代数据往往不限于这些,见BI简介。比如对于某出国留学机构,新浪微博中关于出国留学话题的微博是有用数据,他们可以通过爬虫爬取微博,经过Python或者R语言处理(因为微博一般是非结构的文本)形成用户需求,情感倾向等有用信息。
ETL: 数据清洗转化加载。主要通过工具(比如DataStage,SSIS,Kettle等)结合sql实现。ETL可以说是DW的基石,数据的质量,更新的效率都由ETL决定。
ODS:操作数据存储(Operational Data Store)它是贴源的,全局的,近期的数据存储。主要作用是:
●近期数据的OLAP:基于ODS制作近期近实时的报表。近期是指客户查看报表频率最高的时间段,比如物料供应报表99%的查询都是最近一个月的数据,此时如果你的
报表是基于DW(DW存放了全部7年的历史数据)开发的,首先查询查询效率上肯定没有基于ODS快,其次当涉及频繁更新和异常数据修改时DW处理起来就比较麻烦。
●支持企业级跨系统OLTP:比如新增一个代理商涉及CRM系统,财务系统,物理供应系统的记录改变,如果没有ODS层就需要一个个去修改子系统,这样既麻烦又对数据的准确性带来了风险。
DW:顾名思义就是对集团数据的全面存储,也有两大作用:
1、准统一的,高质量的集团信息统一视图,更好的保护企业数据资产
2、为数据分析和挖掘提供基础。
数据流从源端经过ETL可以直接进入DW也可以经过
不得不吐槽下:一个20多年提出的概念,现在没有必要亦步亦趋去实现,应该根据实际情况灵活的选择工具或者方法区去实现。 就像20多年前有人告诉你从A地到B地要先走路去C,再从C做汽车去D,再从D坐火车去B。在当时可能是个标准的解决方案。但20年后的今天你没有必要去实践那个路线,因为时代变化太快,特别是IT行业。

