一、整体介绍及环境准备
作为S语言的一个分支,R语言基本一直在传统的统计领域发光发热。但是随着大数据热炒的兴起,R语言愈发成为当下一门炙手可热的分析工具,而从TIOBE 编程语言排行榜中,我们也可以看到R语言的排名一直在往上游走。
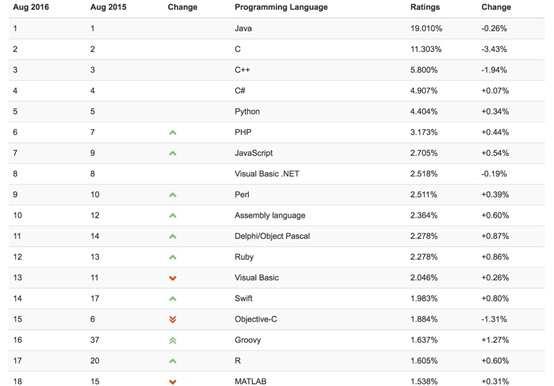
TIOBE 2016年8月 编程语言排行榜
正如浩彬老撕之前所讨论的,机器学习作为一个充满生命力的技术领域,每天都能看到长足的进步,为了能够在Modele中能够应用到更新的技术,因此早在15.0版本中,以及开始了与R语言的集成。而到了18.0版本,SPSSModeler与R语言的集成在使用上已经非常的便利,接下来,浩彬老撕将给大家介绍SPSS Modeler与R语言的集成使用。

环境准备
(1) 先安装SPSS Modeler客户端
试用教程可见:SPSS最新版本完美试用教程(及技术交流社区)
(2) 下载和安装对应的R程序版本
https://cran.r-project.org/上下载对应系统及版本的R语言版本
(注意,因为SPSS 与 R语言的集成有版本要求,所以需要选择对应的版本,对应关系可见下面总结)
(3) 安装集成插件:IBM SPSS Modeler - Essentials for R(包含Statistics以及Modeler)
插件链接:
https://www-01.ibm.com/marketing/iwm/iwm/web/preLogin.do?source=swg-tspssp
注意:安装顺序需要先安装Modeler客户端以及R语言后再安装集成插件,集成插件安装过程中需要选择已安装R的路径地址。
以上三者的版本对应关系为:
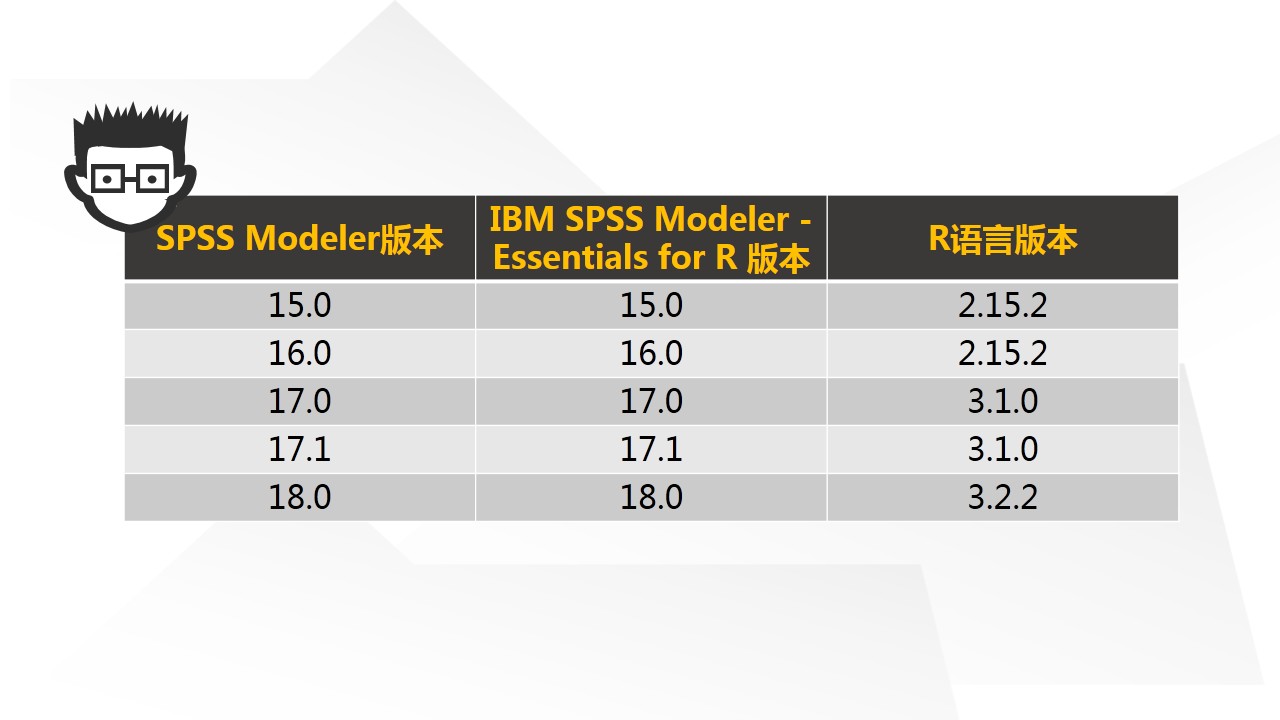
吐槽一句,上面的版本对应关系竟然一直没有人总结,浩彬老撕只能对应每个版本的安装文档逐个检索出来了。

在18版本中,Modeler与R集成的方式主要有两种:
(1)通过预设的R节点进行代码编写实现功能,分别是R变换,R构建,R输出:

以及借助R构建后的R模型节点


“R变换”节点使得我们从Modeler从获取的数据通过定制的R脚本来进行进一步的数据准备,并且完成后,再把数据返回到数据流中。

“R构建节点”使得我们可以借助定制的R脚本使用更多不同的算法来进行模型构建一级模型评分,通过执行“R构建”节点,将生成特定的R模型块

“R模型块”与标准的IBM SPSS Modeler模型块相似,即是通过模型构建算法生成的模型节点。

“R输出”节点使得我们可以使用定制的R脚本来分析数据和展示模型评分结果,分析输出可以是文本,也可以是图形。
(2)通过“用于扩展的定制对话框构建程序”来生成自定义的节点;
通过定制对话框,我们可以把Python以及R的代码封装为一个模型节点,封装后,普通使用者不需要理解背后的代码,只需要按照Modeler中一个普通的节点一样进行参数调节即可。
二、集成与实现
在接下来内容中,浩彬老撕通过一个线性模型例子,为大家介绍如何通过预设的R节点进行模型实现功能:
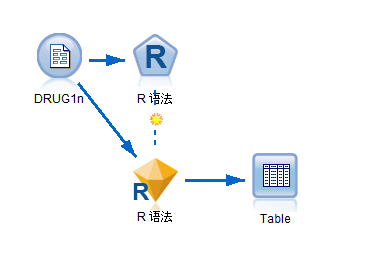
数据文件名为:DRUG1n,是一位收集研究数据的医学研究人员对于身患同一疾病的一组患者的数据。在治疗过程中,每位患者均对五种药物中的一种有明显反应,该数据文件以及流文件可以通过如下链接下载:
链接: https://pan.baidu.com/s/1pKR2dHx 密码: si92
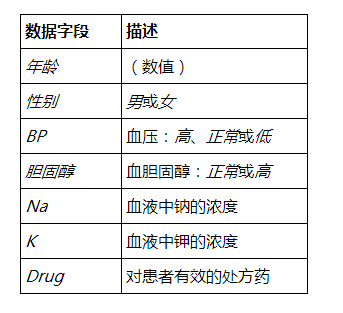
在此示例中,浩彬老撕通过R脚本的方式将变量 Age 用作模型输入字段,且将变量 Na 用作模型目标字段来将线性模型与示例数据集 DRUG1n 拟合。
具体步骤:
将“变量文件”节点从“源”选用板添加到流画布,双击“变量文件”节点可打开节点对话框。
单击文件字段右侧的省略符按钮 (...) 以选择 DRUG1n 数据集。在演示文件夹中可找到包含 DRUG1n 数据集的文件。
单击确定关闭“变量文件”节点。
将“R 构建”节点从“建模”选用板添加到流画布并将其连接到“变量文件”节点。
双击“R 构建”节点可打开节点对话框。
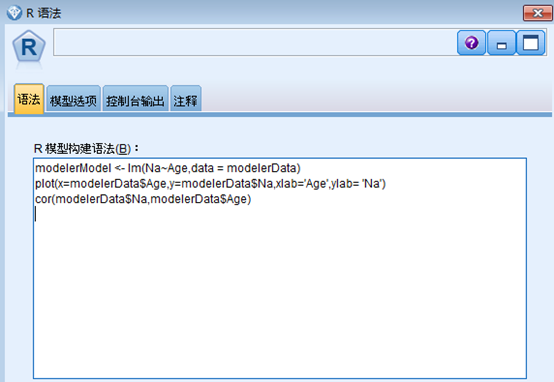
在语法选项卡上的 R 模型构建语法字段中,输入以下 R 脚本:
modelerModel<-lm(Na~Age,data=modelerData)#构建线性模型,其中此处使用的数据文件是‘modelerData’,会使用DRUG1n 数据集自动填充。
plot(x=modelerData$Age,y=modelerData$Na,xlab="Age",ylab="Na")#作图
cor(modelerData$Na,modelerData$Age)#求输入字段以及目标字段的相关系数
#执行该节点后,R 对象 modelerModel 包含线性模型分析的结果。
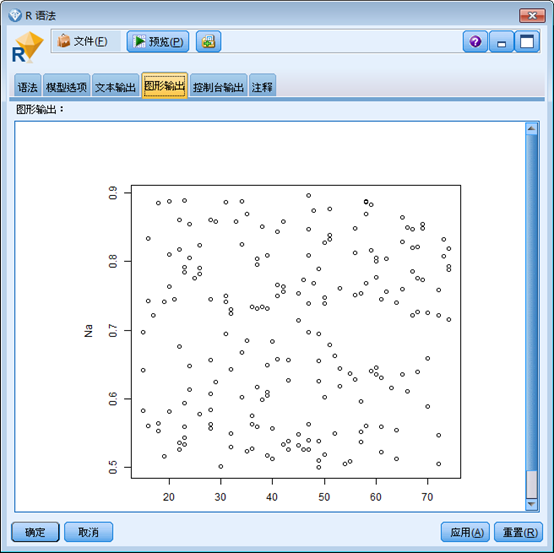
7. 在模型选项选项卡上,选择以 HTML 格式显示 R 图形。执行该节点后,R 模型块的图形输出选项卡上会显示针对输入字段 Age 的目标字段 Na 的图。
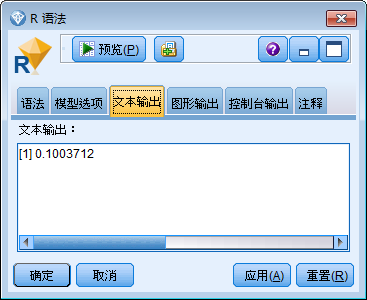
8. 在模型选项选项卡上,选择显示 R 文本图形。执行该节点后,目标字段 Na 与输入字段 Age 之间的关联将写入 R 模型块的文本输出选项卡。
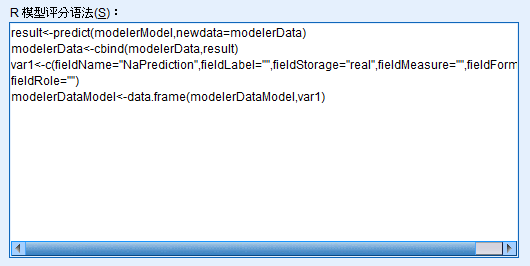
9. 在语法选项卡上的 R 模型评分语法字段中,输入以下 R 脚本:
result<-predict(modelerModel,newdata=modelerData)
modelerData<-cbind(modelerData,result)
var1<c(fieldName="NaPrediction",fieldLabel="",fieldStorage="real",fieldMeasure="",fieldFormat="",fieldRole="")
modelerDataModel<-data.frame(modelerDataModel,var1)
执行 R 模型块后,会创建以下 R 对象:
10. 单击运行以执行“R 构建”节点。将 R 模型块添加到“模型”选用板。
11. 将 R 模型块添加到流画布。
12. 将“表”节点从“输出”选用板添加到流画布。
13. 要查看目标字段的预测值,请将“表”节点连接到 R 模型块,双击“表”节点,然后单击运行。
14. 该表在名为 NaPrediction 的字段中包含预测值;该字段由模型评分 R 脚本创建。
值得注意的是,上面代码中有三个对象需要大家留心:
(1)ModelerData:这是Modeler在当前流中的数据对象,该数据会自动填充到R的数据对象中,在本例中,ModelerData就是通过变量文件节点读入的DRUG1n数据
(2)ModelerModel:这是在R节点中,通过脚本生成的模型分配到R对象modelerModel中。
(3)modelerDataModel:这是关于对象” ModelerData”的描述,主要包含流入数据的类型和结构。
在我们借助于模型生成了新的预测数据,并将该预测数据添加到modelerData中时,我们还必须对modelerDataModel添加一个新的字段,该字段是用来描述新增数据字段的类型和结构,该字段具有的语法结构如下所示:
c(fieldName="",fieldLabel="",fieldStorage="",fieldMeasure="",fieldFormat="",fieldRole="")
fieldname 是字段名称,属于必需项目,引号内即为需要输入的字段名称;
fileLabel 是字段的标签,属于可选项目,引号内即为需要输入的字段名称;
fileStorage 是字段的存储类型,属于必须项目,可以选择下列其中一项作为输入:integer,real,string,data,time以及timesstamp
filedMeasure 是字段的测量级别,属于可选项目,可以选择下列其中一项作为输入:nominal、ordinal、flag、discete以及typeless;
fieldFormat 是字段的格式设置,属于可选项目,可以选择下列其中一项作为输入: standard,scientific, currency, H-M, H-M-S, M-S, D-M-Y, M-D-Y, Y-M-D, Q-Y, W-Y,D-monthName-Y, monthName-Y, Y-dayNo, dayName以及monthName
fileRole 是字段的角色,属于可选项目,可以选择下列其中一项作为输入:input, target, both, partition,split, freqWeight, record以及none。
近期热门文章精选:
1.数据人也要懂的“装逼利器”,数据驱动下的“增长黑客”
2.菜鸟数据岛采访:数据分析工作的一些思考
3.一个蛇精病的R语言包,每天给你一个花式自动赞~
4.SPSS Modeler 18.0新功能权威解读(文末试用指南)

作者简介:浩彬老撕
好玩的IBM数据工程师,
立志做数据科学界的段子手,
致力知识分享,每月至少一次送书活动




