数据挖掘预备役——前期数据处理(译)
原文:
https://www.analyticsvidhya.com/blog/2016/01/guide-data-exploration/
介绍:
通往数据挖掘的道路没有捷径。如果你认为机器学习可以让你远离数据风暴。相信我,它不会的。在一段的学习之后,你会意识到它只是一直拼命的提升模型的准确性。数据挖掘技术会帮你走出这个困境。
我可以很确定这么说,因为我已经经历了太多这些情况。
到目前为止我已经从事商业分析三年了,在我最开始的时候,我的导师建议我花大量的时间在数据分析和挖掘上。遵照他的建议,我平步青云。
这个教程帮你明白数据挖掘的基础技术,我也尽力用最简单的方法来解释这些概念。
目录
1、 数据挖掘的准备
2、 缺失值处理
3、 异常值检验和处理
4、 特征设计的艺术
一、 数据挖掘的准备
源数据的质量决定你输出的质量。因此,你会花整个项目70%的时间进行数据挖掘的清洗和准备才能获得到商业假设。下面是在建设预测模型需要清洗和准备的步骤:
1. 变量定义
2. 单变量分析
3. 二维变量分析
4. 缺失值处理
5. 异常值处理
6. 变量转化
7. 变量生成
最终我们会迭代4-7步多次直到提出改进的模型。
现在让我们详细的学习每一步
1. 变量定义
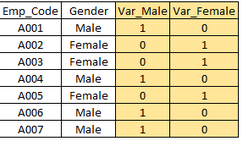
最先定义因变量和自变量,然后定义数据类型(数值、文本等)和变量的种类(连续,离散)。举个例子:
假设我们预测学生是否玩板球
下面图示,变量被定义为不同类别

2. 单变量分析
这一步,我们逐个分析变量。变量类型是连续还是离散的影响单变量分析方法。让我们来整理下针对不同变量类型的统计方法和量度。
连续变量——我们需要理解集中趋势和集中程度。他们用以下显示的统计指标来度量。
注意:单变量分析也是被用来标识出缺失值和异常值的方法。

离散变量——用频率去理解每个分类的分布。可以频数和频率两个指标来衡量每个分类,一般用柱状图进行可视化。
3、二维变量分析
二维变量分析找出两个变量之间的关系。在预先定义的显著水平中探寻变量的相关性。连续性和离散性变量可以任意两两做相关分析,但要针对不同的搭配用相应的分析手段。
连续变量&连续变量
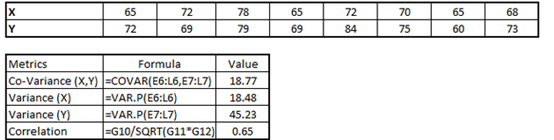
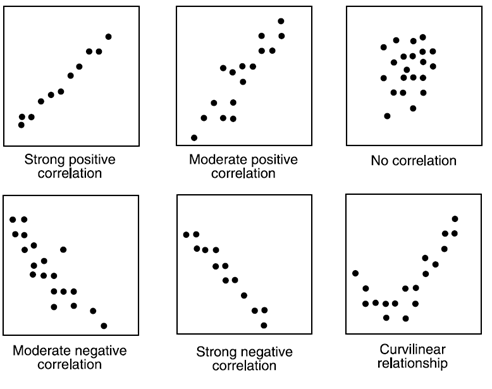
利用散点图可以快速发现彼此关系。可以判断是否线性相关,但不能预测相关的强度。用相关性来确定关系的强度,它介于-1到1之间,-1代表负线性相关,+1代表正线性相关,0代表无线性相关性。线性相关公式为
Correlation= Covariance(X,Y) / SQRT( Var(X)* Var(Y))
大量工具可以计算出相关情况,excel中的CORREL(),下面案例:
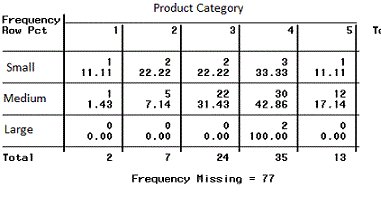
类别型&类别型
二维表
创建二维表格,表格内填入数量或者百分比。行和列分别代表一种变量。
堆积柱形图
这个方法可视性较好

卡方检验
卡方检验是用来推导变量之间的统计显著性。它检测是否样本数据足够概括总体情况。它是根据期二维表中一个或多个类别期望值和观察值的不同,他返回的概率用于计算卡方检验的自由度
概率为0:类别变量是相依赖的
概率为1:类型变量是独立的
概率小于0.05:两个变量显著性在95%置信区间内。卡方检验统计两个类别型变量独立性的函数:
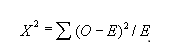
O代表观察的频率,
E代表零假设下期望的频率,其计算公式
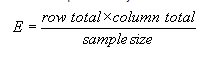
类别型&连续型
可以给每个标准类别型变量画箱线图,如果标准数值比较小,他不能展示数据的显著性,我们可以用Z检验,T检验或者方差分析
Z检验/T检验:两者都是估计两组的平均值是否不同
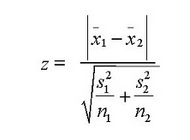
如果Z值越小表明两组平均越显著。T检验与Z检验很相似,但两个类别型数量要小于30个
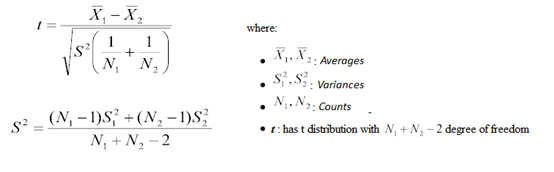
方差分析:他估计两组数据平均是否不同
例子:假设我们想检查下五种锻炼的效果,我们募集20个志愿者,每4人一组练习一种锻炼项目,记录他们几个星期的体重变化,可以通过5组数据比较来判断锻炼项目效果是否一致
二、缺失值处理
1、为什么处理缺失值是必须的?
在样本中有缺失值会减弱模型的强度,或者能导致有偏模型因为我们不能正确的分析变量间行为和关系,导致错误的预测和分组。
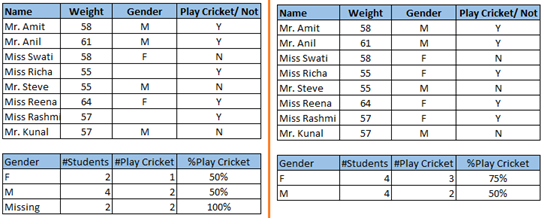
看上图的缺失值:左侧的方案,不处理缺失值,表明玩板球的男性概率等于女性。右侧的方法表明女生高于男生的
2、为什么我的数据有缺失值
数据提取:发生在数据收集的时候而且很难去修正。大致分为四个类型
A. 缺失值完全随机的:对观察对象丢失值发生的概率是一样的,例如数据收集过程的调查者是否说明他的收入取决于仍硬币,正面朝上就告诉你,反面就不告诉。
B. 缺失值随机:变量随机丢失而且不同维度的比例失调,例如我们收集年龄的数据,女性缺失值高于男性
C. 缺失值取决于未观测的自变量:缺失值不是随机的,与因变量息息相关。例如,在医学中,如果特定的诊断引起不舒服,会有很高的概率导致逃课。(Ina medical study, if a particular diagnostic causes discomfort, then there ishigher chance of drop out from the study. This missing value is not at randomunless we have included “discomfort” as an input variable for all patients.)
D. 缺失值取决于缺失值本身:例如:高收入或者低收入不愿意回应他们的收入。
3、处理缺失值的方法有哪些
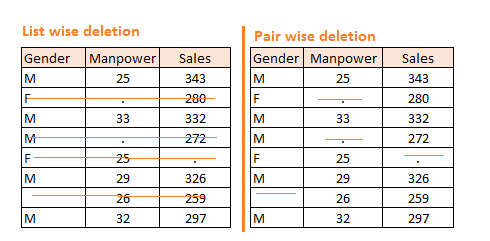
A. 删除:用于缺失值完全随机的情况
如下图,两种删除方式。左侧是缺失值的整条记录删除,这个方法削弱数据的强度。右侧仅删除缺失值项,但不同的变量的样本数量不同。
B.平均值、中位数、众数填充
1) 广义性填充:我们用所有变量均值或者中位数填充所有缺失值变量
2) 相似性填充:我们计算每类变量的的平均值,按照分类进行对应缺失值填充
C.预测模型:
是比较复杂的方法。把数据分为2组,一组是无缺失值为训练组,另一组有缺失值为测试组(其中有缺失值变量为因变量)。我们根据训练组属性建立模型来预测因变量填充测试中缺失值。可以用回归,方差,逻辑回归等多种建模方法。这个方法有缺点:估计出来的值比真实在表现更好,如果数据和缺失值没有相关性,那么预测模型不能准确估计缺失值。
D.KNN算法填充
用距离公式判断给定数据中与缺失值最相似的数据,用其进行填充。优点:KNN可以预测定性或者定量的属性;不需要为缺失值每个属性创建一个预测模型;多重变量的属性很容易处理;数据结构相关性也被考虑在内
缺点:KNN算法比较耗时间;K值的选择很关键,k值选高了把不同属性的数据也囊括进来,选低了错失数据
三、异常值处理
异常值是偏离样本模型的值。例如在做客户剖析,发现顾客年度平均收入是$0.8,但有两个顾客收入为$4、$4.2。这两个顾客远比其他人高,被看做异常值。
1、异常值有什么类型
单变量异常值和多变量异常值,上述例子就是单变量异常值,通过观察一个变量分布就可以发现异常值。多变量异常值需要在多维空间分布内才能发现异常值
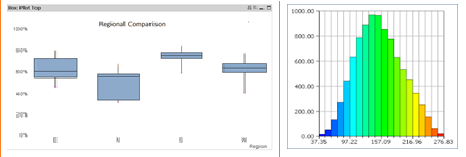
观察下图身高和体重的关系,列出单变量和二维变量分布图。观察盒图,没有发现异常值(都在在1.5极差内),但看散点图,有两个点很低和一个点高于平均水平

2、什么引发异常值
无论什么时候我们碰到异常值,最理想的办法处理是发掘异常值的原因是什么。
数据输入错误,测量错误(测量仪器错误),实验错误(例如7个选手参加100米比赛,其中一个因溜号错过发枪号令,因此他的时间可能为异常值),故意异常值(经常发生在敏感问题的自我评估上,例如调查青年人的喝酒量,仅有一小部分会吐露真情,大部分会低于其真实值,这会导致真实值成为异常值),数据处理错误(进行数据挖掘的时候,需从多方面资源提取数据,可能处理或提取错误可能导致数据异常),样本错误(例如,要测量运动员身高,样本包含篮球运动员数据,他们很大肯定为异常值),非人为异常值(例如,世界50强经济数据异常高于其他公司,但并不是错误,此时需要分成两部分来处理)
3、异常值的影响
异常值能改变数据分析结果和统计模型
4、如何发现异常值
运用可视化,异常值经验法则如下
盒图:超过正负1.5极差为异常值
限制方法:在5%-95%以外的数据为异常值
数据点:数据与平均值的差值三倍或更多时为异常值
业务逻辑:对业务了解
公式算法:二维变量或多维变量经常用指数影响或者距离影响。例如马氏距离和Cook距离
5、如何处理异常值
异常值处理和缺失值处理很多类似。
删除观察值:数据输入错误,数据处理错误或者异常值数量很小。也可以删除两端极值去除异常值
转化和分类数据:数值的自然对数减少异常值,Binningis also a form of variable transformation.决策树可以很好处理变量分类。也可以给不同变量权重。
人为赋值:与处理缺失值一样。但只有人为因素导致异常才能用此方法。
分开处理:异常值数量不少的时候
四、特征工程的艺术
特征工程是一门科学,从已存在的数据中挖掘更多信息,使数据变得更有价值。
例如:根据日期预测购物中心到客率,如果直接用日期不太可能发现有用的见解,但使用星期去度量数据,可能会发现相关规律
1、特征工程的过程是什么?
变量转化和变量/特征创建,这对于数据挖掘影响很大。
A.变量转化:数据模型中,转化是指用平方/立方根或者对数等公式算法替代原数据,或者说转化就是改变变量与其他变量的分布或者关系。
2、什么时候使用变量转化?
1)当为了更好理解变量而改变其单位或者标准。当数据单位不同时,这个转换是必须的,此时的转化不会改变变量间的分布情况。
2)把复杂非线性的关系转化线性关系,散点图可以展示连续型变量的关系,对数转化是最常用的手法
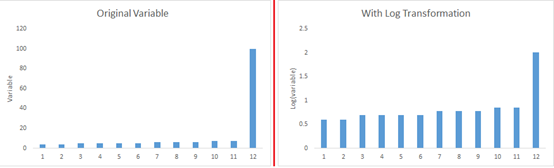
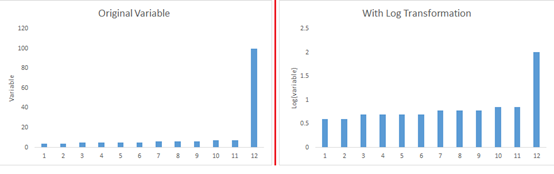
3)对称分布好于有偏分布:当数据右偏,用平方/立方根或者对数方法;当数据左偏,用平方,开方或者指数方法。
- 4)Variable Transformation is also done from an implementation point of view(Human involvement). Let’s understand it more clearly. In one of my project on employee performance, I found that age has direct correlation with performance of the employee i.e. higher the age, better the performance. From an implementation stand point, launching age based progamme might present implementation challenge. However, categorizing the sales agents in three age group buckets of <30 years, 30-45 years and >45 and then formulating three different strategies for each group is a judicious approach. This categorization technique is known as Binning of Variables.
3、常见变量转化方法有哪些?
有很多种转化方式,像平方,开方/立方根,对数,分组,互换等。下面介绍常见的方法优缺点
对数:通常用在右偏数据中,但不能处理0和负值
平方/立方根:有效的影响分布,但没有对数显著,立方根处理负数占有优势
分组:针对类别型变量,对原始百分比或频率。分组基于对业务的了解。例如,可以把收入分为高、中、低。
B什么是特征/变量创建,他的好处?
针对存在的变量生成一个新变量。例如,在数据列日期形式是(dd-mm-yy) ,可以生成日,月,年三个单独的变量。也许一周数据对目标数据有更好的相关性,用这个方法可以突出隐藏的关系。
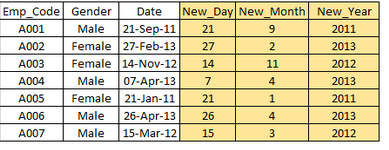
常见生成新变量的方法如下
1) 生成衍生变量:
用公式或者其他方法创建新变量。例如:数据性别列很多缺失值,但在姓名中有Mr,Miss,可以根据姓名确定性别
2) 生成虚拟变量:
最常见的是把类别型变量转化为数值型变量