版本:IBM InfoSphere DataStage V11.3.1
操作系统:linux redhat 6.4
前言:
对于一些复杂的DS作业,我们在遇到作业报错或预警,甚至得到的结果与我们想象的不一致时,会通过分析跟踪日志来做相应问题处理方法。
本篇主要是对DS作业日志展现和节点配置,提取日志,便于在实际工作中根据日志解决问题。
DS日志变量
CC_MSG_LEVEL 环境变量用于过滤作业日志中的连接器消息。该环境变量适用于所有连接器。
表 1. CC_MSG_LEVEL 环境变量值

当 CC_MSG_LEVEL 环境变量未设置时,其默认值为 3。当将其设置为值 1 时,作业日志的大小可能会显著增加,尤其是在有多个连接器阶段在处理许多记录的情况下。当希望收集详细的作业日志和跟踪级消息,且将 CC_MSG_LEVEL 设置为 1 时,需要确保运行的作业具有较少量记录,最多几百条。在生产环境中,绝不要将此环境变量设置为值 1 或者甚至是 2。通过确保该值设置为 3 或更高的值,或者完全不设置,不仅可预防作业日志潜在地使用大量空间,还可确保作业的性能不会受到过量日志记录活动的影响。
要确定在作业运行时为此环境变量使用了哪个值,请检查位于作业日志顶部的 Environment variable settings 消息中的环境变量列表,如果列表中不存在 CC_MSG_LEVEL,则表明其没有显式定义,在该情况下将使用默认值 3。
变量设定
该变量值,我们会在Administrator 客户机中设定如下:
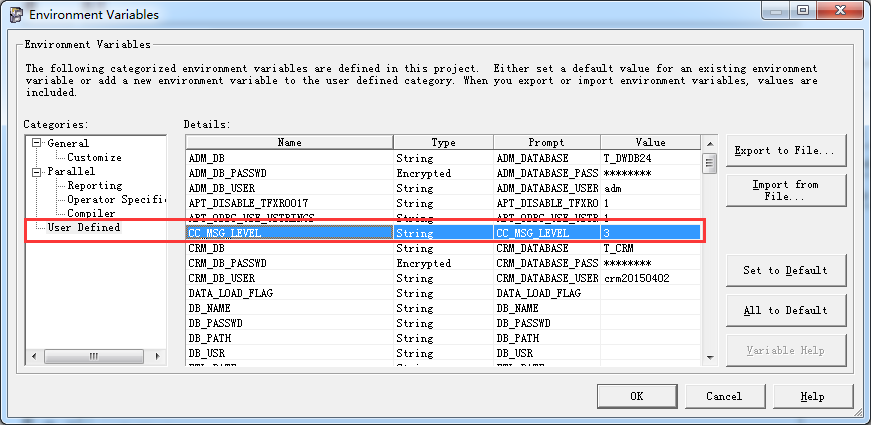
当然如果我们需要分析调试及跟踪信息则需要将日志级别变为1 如下设定:
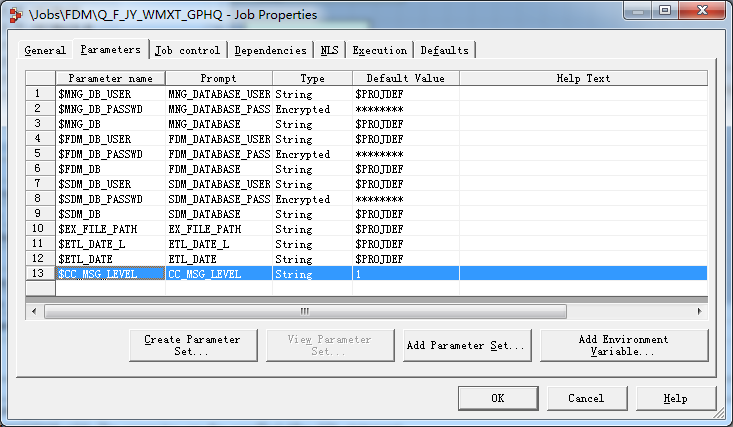
运行作业会发现日志增加。根据需要去做相应过滤。
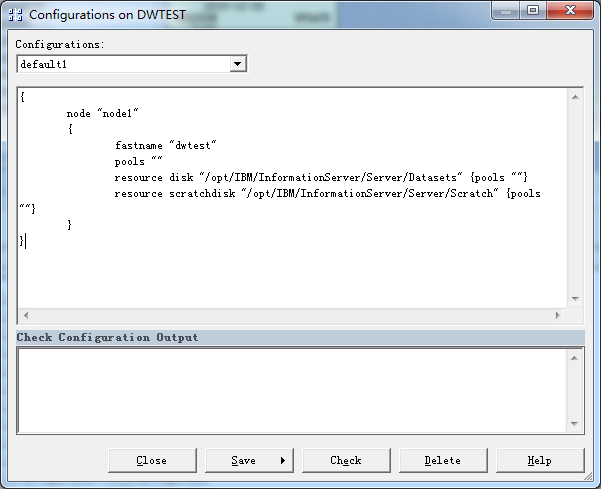
配置节点:
配置节点文件,具体位置可以通过操作数据库DSODB来查询
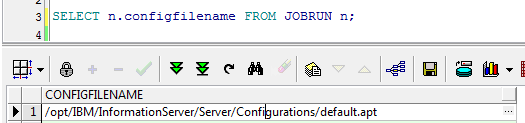
配置节点内容:
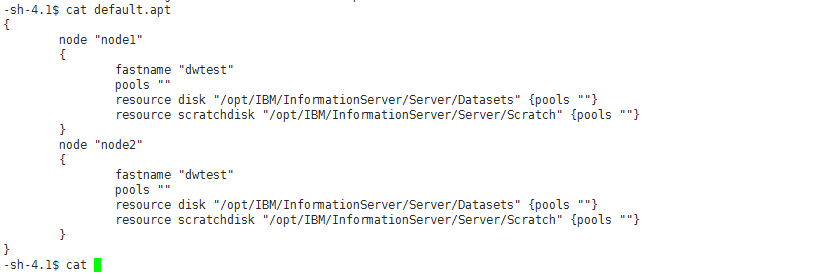
- node: 节点的逻辑名称,通常情况下根据此节点本身具有的功能来定义。配置文件中不能包含多个相同的节点名字。
- Fastname: 机器的 host name
- Pools: 定义了这个节点被分配到的节点 pool 的名称,一个节点可以分配到多个节点 pool 中。因此这里的 pools 可以有多个值。如果这个值为空,那么将使用默认 pool,默认 pool 对所有的 stage 都是可用的
- resource disk: 定义了这个节点用来存储持久数据的存储资源
- resource scratchdisk: 定义了这个节点用来存储临时数据的存储资源
性能优化提示:在上面的示例配置中,每个节点都使用了相同的 scratchdisk /u1/Scratch,这并不是一个好的实践。出于性能的考虑,一般情况下并不建议这么做,而是针对每一个节点都使用一个本身专用的 resource scratchdisk。
转:DataStage 七、在DS中使用配置文件分配资源
注意:处理节点node1和node2是逻辑节点不是物理节点,它不代表物理CPU的个数,可以在一个物理机器中定义一个或多个逻辑节点。逻辑节点的定义决定了在并行作用运行时可以产生多少个并行进程和有多少的资源可用,等同于Unix上的物理进程数,逻辑节点越多产生的进程和使用的内存或磁盘空间(如排序操作)就越多。在IBM的官方文档中建议创建逻辑节点的个数为物理CUP数的一半,当然这还要取决于系统配置、资源可用性、资源共享、硬件和JOB设计,比如如果JOB需要高的IO操作或者要从数据库中获取大量的数据,这时可能要考虑定义多个逻辑节点来完成操作。
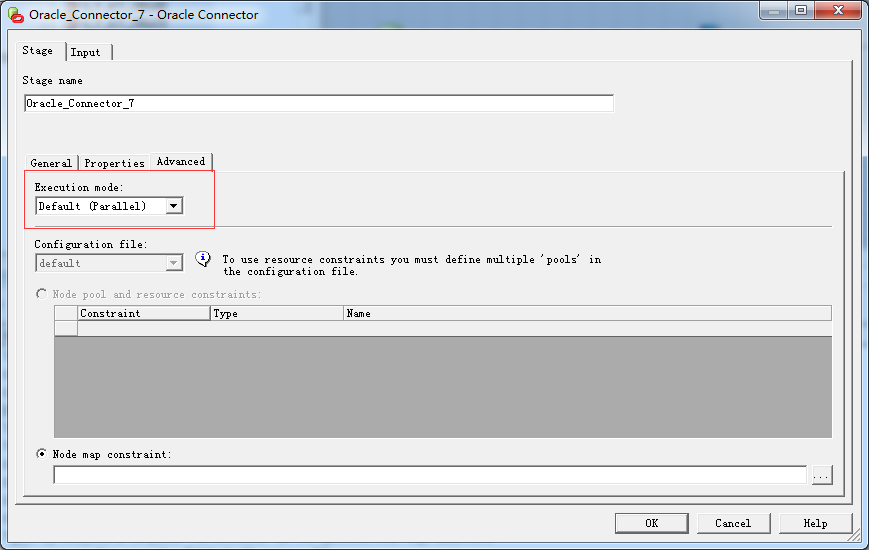
DS配置控件里面默认配置都为并行模式,所以在查看日志会看到日志很多,我们需要只个设定一个节点,或者可以更改为串行。
设置为1个节点,点击工具栏Tools ,点击Configuration,选择之前配置节点文件。
关于并行验证
关于并行实验操作如下:
图1:
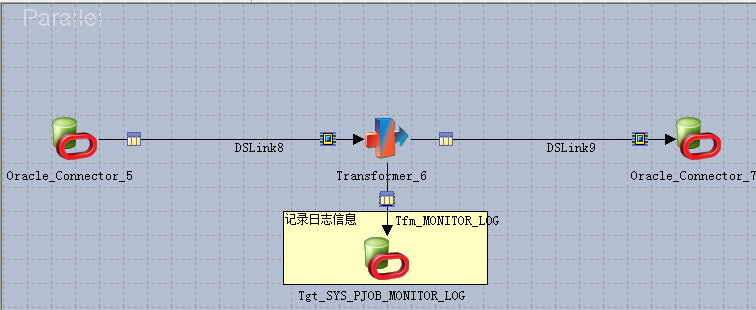
图2 默认并行:
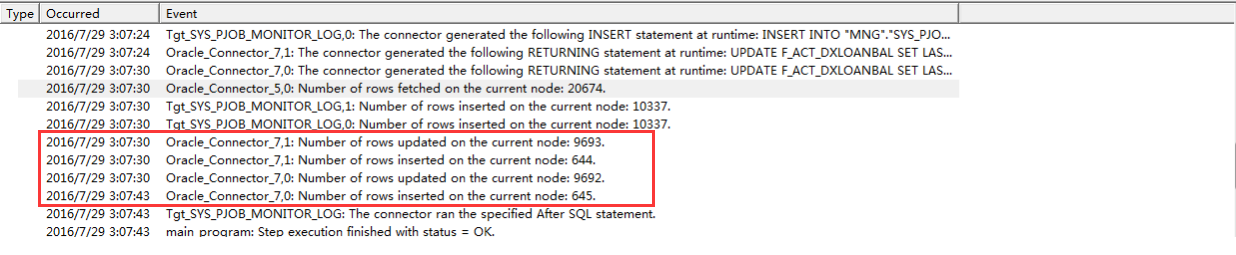
图三 日志信息
图四:更改设置为串行
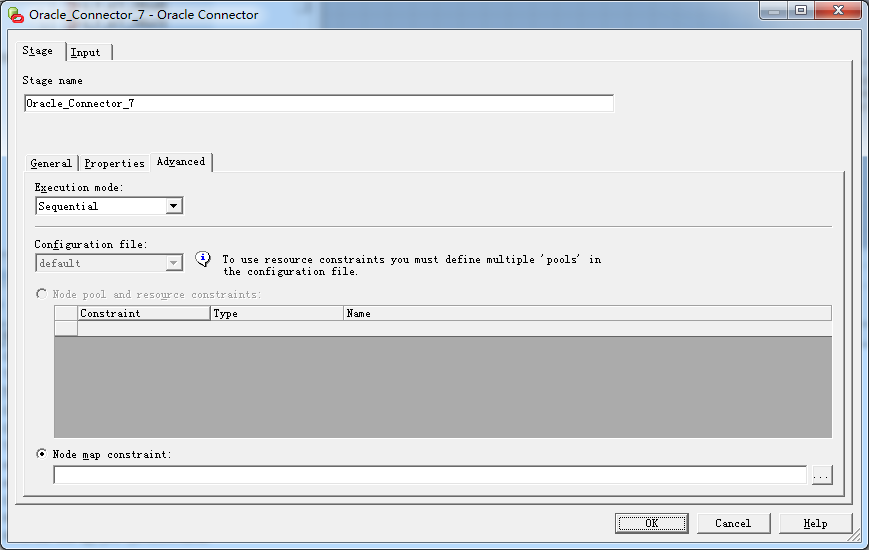
图五 再次查看日志

日志导出:
@'DataStage Director', find 'your-job'job -> Menu 'Project'->'Print'->Checked 'Full details'+'All entries'+'Print to file'->Click OK.
导出日志,请检查一下, 确认不是只有一百条, 还有日志量很多.
总结
本文主要涉及,查看日志等级设置,节点配置和日志导出部分,掌握这三点对分析Pjob问题是非常有用的。

