1.数据分析的流程

2.R语句由函数和赋值构成。使用“ <- ”作为赋值符号而不是“ =” ,例如:
x <- rnorm(5) 或者 反赋值 rnorm >- x
这个语句创建了一个名为x的向量对象,它包含5个来自标准正态分布的随机偏差
注释由符号#开头。即R语句运行时#符号后面的字符会被忽略
3.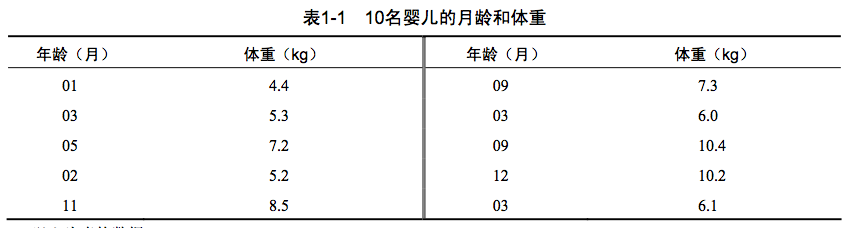
> age <- c(1,3,5,2,11,9,3,9,12,3) #用函数c( )以向量的形式输入“月龄”数据
> weight <- c(4.4,5.3,7.2,5.2,8.5,7.3,6.0,10.4,10.2,6.1) #用函数c( )以向量的形式输入“体重”数据
> mean(weight) #计算平均“体重”
[1] 7.06
> sd(weight) #计算“体重”的标准差
[1] 2.077498
> cor(age,weight) #“月龄”和“体重”相关度
[1] 0.9075655
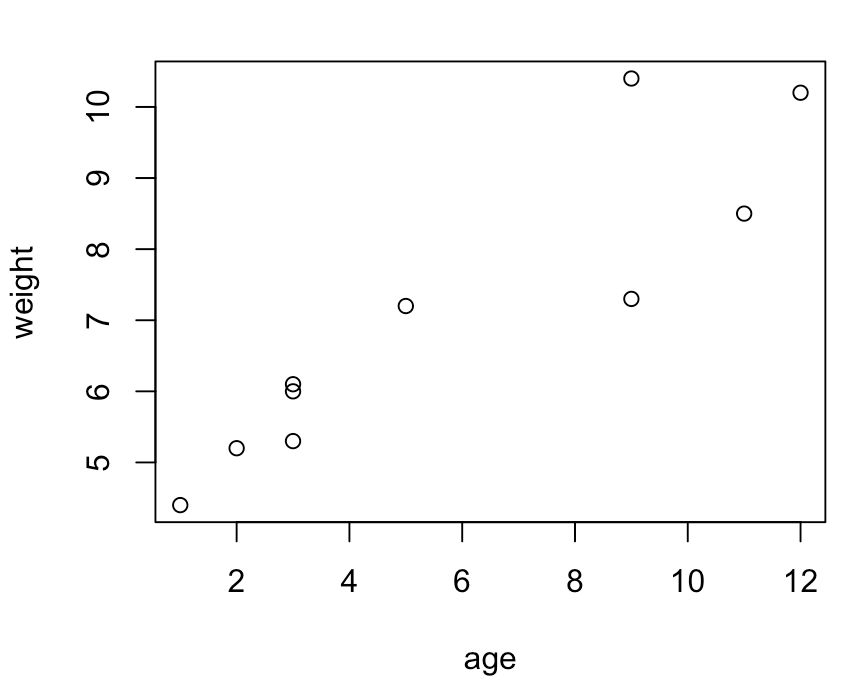
> plot(age,weight) #“月龄”和“体重”关系的散点图
4.demo( )示例
demo(graphics), demo(Hershey), demo(persp), demo(image)忒好玩了。。

4.帮助命令
> help.start #打开帮助文档主页
> help("foo")或者?foo #查看函数foo的帮助
> help.search("foo")或??foo #foo为关键字搜索本地帮助文档,这里是两个问号
> example("foo") #函数foo的使用示例(引号可以忽略)
> RsiteSearch("foo") #以foo为关键字搜索在线文档和邮件列表存档
> apropos("foo",mode = "function") #列出名称中含有foo的所有可用函数
> data( ) #列出当前已加载包中所含的所有可用示例数据集
> vignette( ) #列出当前安装包中所有可用的vignette文档,vignette文档一般是介绍性的pdf文章
> vignette("foo") #为主题foo显示指定的vignette文档
5.工作空间
> getwd( ) #获得当前默认目录
> setwd("myfile") #修改当前的工作目录为myfile
> ls( ) #列出当前工作空间中的对象
> rm(objectlist) #移除一个或多个对象
先写这么多。。。

