公告
周五BI飞起来,每周一个主题,一场跟数据有关的行业、工具、技术的交流盛宴,锁定在每周五晚20:30,不见不散!
未来几期的微信直播活动分享主题将包括谈谈BI在生产企业的应用、数据科学家应用 、SPSS数据挖掘、腾讯大数据分析与挖掘应用、R语言实战、数据挖掘经典案例赏析等,具体日期安排请关注天善智能问答社区活动版块https://www.hellobi.com/events。
主持人:加入本群的同学们,感谢大家参加由天善智能举办的 Friday BI Fly 活动,每周五微信直播,每周一个话题敬请关注。
【群规】本群为商业智能和大数据行业、技术、工具的交流学习群。不准发广告,只能发红包,发广告者一律移除微信群。
本期分享内容
腾讯大数据分析与挖掘应用
本期嘉宾介绍
彭远权 腾讯 高级数据分析师
主持人:大家好,我是微信直播活动的主持人咖啡,每周一个主题,一场跟数据有关的行业、工具、技术的交流盛宴。我们的口号是“Friday BI Fly 周五BI飞起来”。有请嘉宾进行下面的分享,腾讯大数据分析与挖掘应用,有请!
腾讯大数据分析与挖掘应用

彭总:大家好,我是来自腾讯的数据分析师,彭远权。很高兴有机会和大家一起交流,首先感谢天善智能提供这个交流的平台。
大家都知道,最近两年,大数据,机器学习,数据挖掘,深度学习等名词一直在整个IT业界都很火。
第一、 对于传统行业的朋友来说,可能会很想了解数据相关工作到底是做什么的?意义何在?
第二、 对于目前数据建设起步阶段的企业来说,数据体系改如何建设?
第三、 建设好数据体系之后,我们可以有哪些发力的地方?
第四、 对于开发人员,我们可以怎么做?做哪些事情?
针对这些疑问,本次分享的主要内容主要有如下几个方面:
1. 数据相关工作是做什么的?
2. 数据体系该如何建设?
3. 具体的一个数据相关算法应用&优化案例
前半部分,会主要讲一些思路和理论,后面侧重面向开发人员,讲一个实际算法案例。
首先回到第一个内容:数据工作是做什么的?
在这个问题之前,那么大家先思考下“产品”这个词的含义。
当然,这个词大家并不陌生,无论传统行业,还是IT行业,各个公司都有自己的产品。
比如:服装行业,产品是衣物。 游戏公司的产品是游戏。
衣物为了满足穿或者美观时尚的需求。 游戏为了满足用户娱乐和竞赛的需求。
我个人的对产品的总结就是:为用户做某种事情提供便利的平台
那么产品和数据工作的关系是什么?
还是送上面举的例子来讲。
衣物的销量,衣物的尺寸,衣物的颜色,衣物的受众年龄,都是数据。
这些可以抽象成衣物的相关Profile.
那么为什么衣物要指定某种设计尺寸,颜色等标准呢?
这其实就是一种数据工作的内容
我给数据工作的定义是:
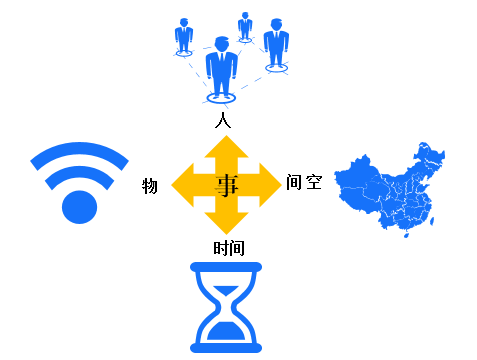
记录用户和其他物品在不同时间、空间上发生事件的事实并研究其规律
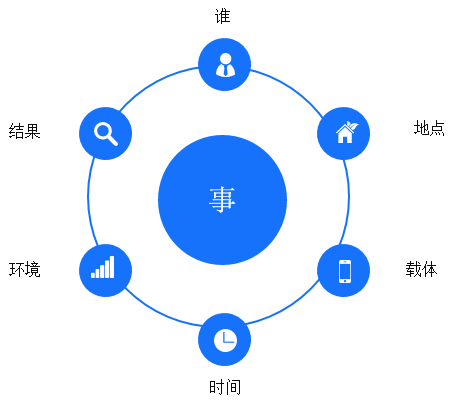
数据工作其实主要研究 (谁)WHO,(什么时间)WHEN,(什么地点)WHERE,(发生了什么)WHAT,(在什么环境下发生的)HOW,(为什么会发生)WHY,(发生的程度怎样)HOW MUCH这7个维度之间的关系。

那么对于想往数据方向发展的同学来说,会考虑我应该具备哪些能力?后期职业规划是怎样的。
这里,我给出一些个人的经验。
大致情况,我会把数据能力分为3个阶段:
1. 青铜级
2. 白银级
3. 钻石级
青铜级,就是初学者的群体。我的建议是掌握如下4个方面的知识:
1. excel
2. 数据库(mysql 或其他数据容器,SQL等技能)
3. 编程能力(学习一门编程语言)
4. 统计学基础
白金级,就是上述基础可能都具备,但是没有数据工作经验,比如从客户端开发或者服务端开发准备学习数据相关知识的同学。我的建议也是有4个方面:
1. 大数据平台(Hadoop体系,Spark体系等开源大数据平台思想)
2. 数据挖掘原理
3. 数据挖掘库(Spark ML,sklearn等)
4. 算法实现能力(可能会面临多种语言混合编程,比如python,scala,java等)
再往高一个层次,就是钻石级以上的,对整个技术体系比较清晰,有工作经验,而且对业务非常熟悉的同学。相信这部分同学的各方面能力都是比较强的。
从入门到进阶 再到 熟练。应该是一种 从基础技术工具学习,到框架体系学习,再到知识体系,业务相关长远眼光培养的一个过程。
好了,上面讲了数据工作的一些基础知识和职业发展的一些建议。
那么我们应该如何建设自己业务相关的一个数据体系呢?
下面和大家分享一个数据理念的话题:数据体系建设方法论
这里我有一个数据规划的4项基本原则:
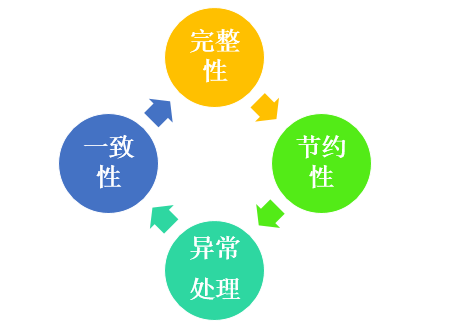
A:数据完整性:
上面已经讲到,数据工作是研究5W1H问题相关规律的过程。
那么我们分析的基础数据,当然要必备上述几个方面。这样我们的数据才能描述清楚事情发生的缘由和真相。
数据完整性这里有3个点:
1. 主题完整性。比如事是人-物,或者物-物之间产生的
2. 主题属性完整性
3. 记录完整性
B:数据一致性:
这个数据原则,主要是解决信息不对称导致的额外工作量增量。
举一个最简单的例子,我们有两个平台的数据。都是关于用户的数据
A平台数据协议:0代表男 1代表女
B平台数据协议:1代表男 0代表女
这样数据整合的时候中间多了一些转换,直接的含义往往会混淆,当然这个例子比较简单,在工作中遇到的一些因为定义不一致的问题,很多很多,尤其是团队非常大的时候,需要有一个数据一致性的规划。
C:数据节约性:

比如像这样的记录,那我们完全不知道张三和food1到底发生过多次关系,还是一些重复上报的误操作导致。
这个问题很典型,往往导致我们在统计分析中看到虚假数据。如果事后做去重处理,也是耗时耗力。那么数据节约性也是数据体系规划的一个重要点。
D: 异常处理

这4种情况都数据异常的范畴,如果我们没有妥善处理。那么在分析数据的时候可能会收到很大干扰。
综合上面讲到的4项基本原则。那么在事件记录方面,我们可以从日志6要素来考虑:
在腾讯这边是以业务分工的。根据经验,我这边也总结了一套比较通用的数据体系架构。经过在几个业务上的验证,整个体系还是比较清晰。
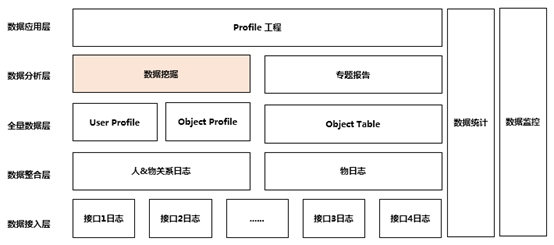
上面分享的是数据体系建设相关的内容,那么有了数据体系,有了数据,我们怎么来挖掘数据的价值呢?
这块的工作,就是上述数据体系的数据分析层,数据挖掘模块。
下面和大家分享一个数据实战:DBScan算法在LBS上的应用
我们要做什么?最终效果是什么?
1. 我们要识别WiFi群落。
2. 我们要识别楼宇
WiFi群落就是,类似于CMCC或者公司WiFi一样,在一定的区域内部署了多个热点。
当然大家使用的时候看到的WiFi名字都是一个,其实背后是有很多个物理设备为大家提供服务的。
何谓DBScan?

这个算法的优点:
具体为什么说它有这些优点,接下来我们看看这个算法的核心思想:
基础概念定义:
邻 域:给定对象半径r内的邻域称为该对象的r邻域;
核心对象:如果对象的r邻域至少包含最小数目MinPts的对象,则称该对象为核心对象;
密度可达:给定一个对象集合D (p q 如果p在q的r邻域内,并且q是一个核心对象,则我们说对象p从对象q出发是直接密度可达的;
密度可达传递性:
Ø 如果存在一个对象链,,,...,,=q,=p,对于D,i 1~n,是从关于r和MinPts直接密度可达的,则对象p是从对象q关于r和MinPts密度可达的;
Ø 如果存在对象o属于D,使对象p和q都是从o关于r和MinPts密度可达的,那么对于对象p到q是关于r和MinPts密度相连的;
Ø 密度可达是直接密度可达的传递闭包,这种关系非对称,只有核心对象之间相互密度可达;密度相连是一种对称的关系;
下图是一个MinPts=3的密度可达示例。
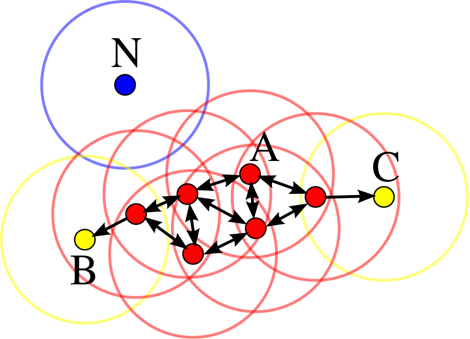
如图,红色的点,就是密度间接可达的。蓝色就是噪声点。
整体的实现思路如下:
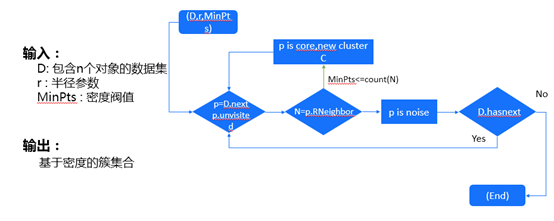
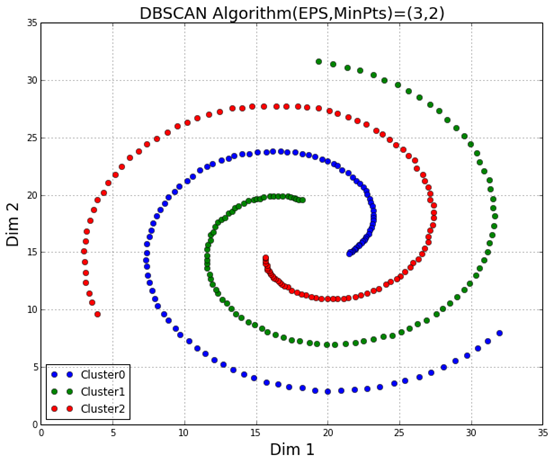
看完这些定义和思路,那么有人可能会说和k-means算法有什么差异?
上面就是一个典型的应用差异,这些不规则形状的聚类识别,k-means效果就不如DBSCAN
但是通过这个算法思路我们也可以看到,有一个问题,就是时间复杂度比较高。
时间复杂度O(m2)
单机计算瓶颈
测试数据4w 耗时近1小时
但是全量数据:8亿+
那么我们就要对这个算法进行优化,让其有能力处理这样庞大的数量级。
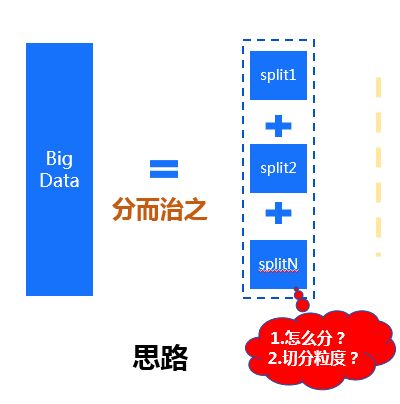
大数据的最基础思想,就是分而治之,那么怎么分,切分的粒度又如何把控呢?
我们这边是用geohash的方法,对数据进行分割,经过数据调研,可以看到geohash key长度为4的时候,单节点计算量会有15W*15W,也是不能忍受的,那么我们只能选择key更长的。
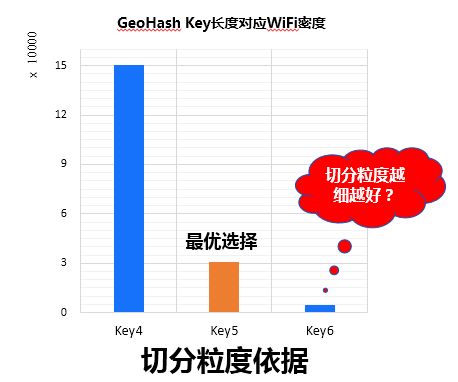
那么切分粒度是不是越细越好呢?
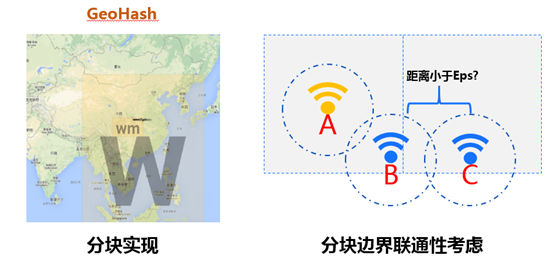
可以看到,切分越细,我们需要考虑的边界问题也会越多。对应算法的迭代次数也会越多。
综上我们选择key长度为5
数据分块聚类è边界点迭代处理è数据输出
最终聚类效果如下:
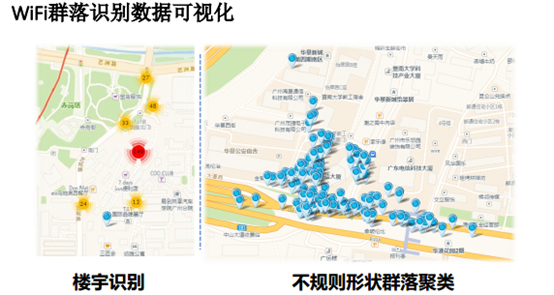
这样的思路就是dbscan算法突破大数据瓶颈的武器。
最终的算法效果(在MapReduce框架上实现)如下:

谢谢大家!欢迎有问题继续交流
主持人:好的,感谢彭老师给大家带来的精彩分享,大家比照一下彭老师讲的,自己在数据这条路上是什么级别呢,还需要掌握哪些技能呢,后面那个实战的案例,我只想说“这三五太难了,一点都不简单”,你们是不是都听懂了呢,有疑问的快来提问吧,下面进入自由提问环节啦
自由讨论
1、彭老师,社区上有个人发问“京东金融数据分析岗和腾讯大数据分析,职场如何选择?各分析下利弊吧~?”
彭老师:好的,这个问题确实是很多朋友会遇到的,两个工作 都是关于数据方向很好的平台:
1. 京东金融,听这个职位名字 金融领域数据分析会多一些风控方面的应用;
2. 腾讯一般侧重于互联网产品。 为了更好的把产品体验提升服务于用户。
从数据量级来讲 腾讯的体量应该大很多,以上是技术方面,另外可以考虑自己的职位发展空间 , 和自己的喜好来选择。
2、23群的提问请问这个聚类有没有完整的步骤和数据让我们具体实现下啊?
彭老师:这块的原谅我只能提供思路,代码这些 可能不允许、数据就更隐私了。不过大家在遇到大数据瓶颈的时候 可以找我交流。
3、楼宇识别指的是什么,能否识别出楼宇的功能商业、办公或者居住,WIFI数据怎么获取的?
彭老师:1. 楼宇商业功能,这个不属于DBSCAN算法解决的范畴。可以通过用户流动性,和用户行为规律结合分析;
2. wifi数据 目前wifi 基站 用于补充GPS定位的精度问题已经很成熟。
4、大数据交流群的提问 :老师您好,您一开始说的事件日志是什么用途?前期不是获取数据并清洗了吗?直接分析不就可以吗?谢谢老师
彭老师:公司团队比较大的时候,客户端开发和数据分析人员是独立两个团队。可能客户端同学写的日志 并不符合数据分析同学的要求。这个时候就需要数据清洗 比如ETL也是一个职业方向。
5、现在大数据计算平台感觉都在往spark上迁移,那刚讲的dbscan为什么仍然用mapreduce实现呢?
彭老师:我们早期也是主要在MR上 目前很多算法已经在向spark迁移,算法思路都是一样的。
6、26群的提问:不过如果数据达到T级别之后,时间复杂度会怎样呢?
彭老师:分而治之的思路就是专门解决大数据问题,100g 比如可以切 1000块,100T 切 1000*1024块就行。
上述数据只是举例,思路就是切块解决单节点瓶颈。
7、10群同问:算法复杂度是咋算的?
彭老师:时间复杂度,针对这种要计算相似度 或者举例的算法,主要思路是剔除掉不需要计算的问题。
比如北京的一个wifi 和广州的wifi 距离这么远完全没必要进行比较。 这个我们用hash算法就可以区分。
8、彭老师,请问DBScan算法和最近一些论文中,效果非常好的DensityPeak算法相比,在处理大数据方面有何优劣呢?
彭老师:DensityPeak这个算法目前还没学习过,我可以抽时间学习后对比下再同步。
9、老师~数据体系架构是不是就是BI体系,数据体系每一层的功能以及具体的呈现方式能不能具体讲一下?
彭老师:c这块讲起来可能时间会比较久,后面我会出一个课程专门讲这块,欢迎大家关注。
10、识别出来的结果有什么应用呢?
彭老师:1. 楼宇识别;
2. 特定区域人流预测;
3. 网络流量调度 等等,应用还是挺多的。
11、老师,请问一下,我想分析一个目标变量,怎么建立各种自变量呢,建立了自变量,又如何挑选变量呢?
彭老师:这个数据数据挖掘中的特征选择和特征处理过程。大家可以搜集这两个方向的一些资料进行学习。
12、老师,请教下wifi群落也属于无线增值业务范畴吧?
彭老师:对 技术服务于产品 产品属于哪个范畴 技术就可以属于哪个范畴。
13、请问 wifi群落 怎么识别 LBS
1)gps ? 这个许多WiFi热点没有该参数
2)根据 IP ? 租用过机柜的都知道,比如在深圳的 ,有可能是用的河源的IP,我在福田,IP报罗湖
3)商家合约提供?商家有可能维护的不一定及时和正确
彭老师:这个问题我可能了解的少一些。不过目前定位技术这么成熟。这个数据很定是比较充足的。
郑大鹏:1,GPS 定位,定不到那么精准了, WIFI 热点可以
彭老师:是用wifi 热点辅助 GPS提高定位精度
原始数据 是 1. WIFI ID,2. lat,3. lng 核心信息是这3个。
郑大鹏:室内定位 不都通过 wifi 么 ?
彭老师:恩 wifi是其中一种 我了解到还有一种技术beacon
下期预告:
2016年08月05日晚8点半微信直播交流基于R语言的大数据处理及建模技术第27场
https://www.hellobi.com/event/90
今天的微信直播活动到这里就结束了,喜欢天善智能的朋友们请继续关注我们,每周五晚8:30,我们不见不散哦!
参与方式
每周 Friday BI Fly 微信直播参加方式,加个人微信:fridaybifly,并发送微信:公司+行业+姓名,即可参加天善智能微信直播活动。
天善智能介绍
天善智能 www.hellobi.com 是一个专注于商业智能BI、数据分析、数据挖掘和大数据技术的垂直社区平台。
问答社区和在线学院是国内最大的商业智能BI 和大数据领域的技术社区和在线学习平台,技术版块与在线课程已经覆盖 商业智能、数据分析、数据挖掘、大数据、数据仓库、Microsoft BI、Oracle BIEE、IBM Cognos、SAP BO、Kettle、Informatica、DataStage、Halo BI、QlikView、Tableau、Hadoop 等国外主流产品和技术。
线上活动:Friday BI Fly 每周五晚 20:30,技术和行业交流,30余个微信直播群互动交流。
线下活动:Saturday BI Fly 在全国各大城市巡回举办200人-500人规模的大数据沙龙交流活动,每月1-2次。
天善智能积极地推动国产商业智能 BI 和大数据产品与技术在国内的普及与发展



