上周结合了一个简单的例子为大家全面介绍Modeler的数据挖掘方法论,CRISP-DM,那么这周将为大家介绍在咱们日常利用SPSS Modeler进行数据分析时,如何借助一些小技巧提高分析效率。

一
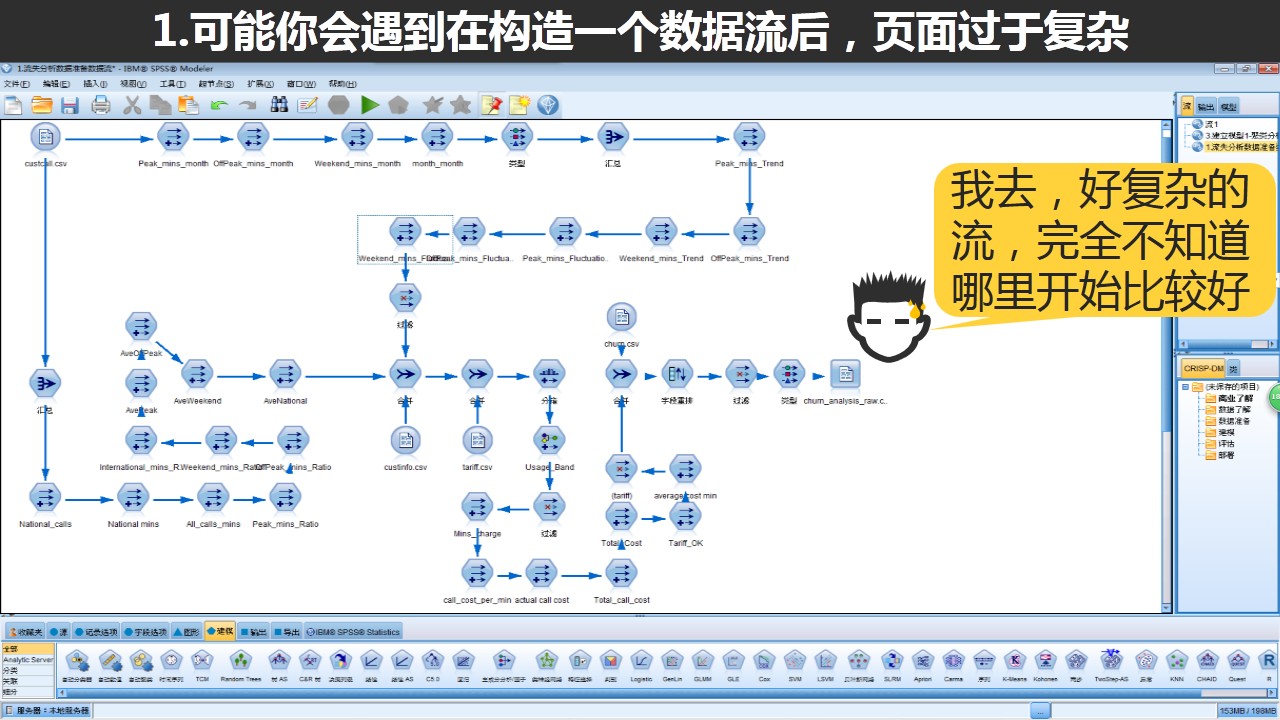
一个数据流中往往包含有很多的节点,上图展示的就是一个流失分析数据挖掘项目当中的“数据处理流”,这时候我们可以看到大量的节点分布在整个版面上显得比较凌乱,而且大量的节点也不容易让我们能够很快分辨出每个节点的用途。
这个时候,我们就可以使用超节点帮助我们简化。
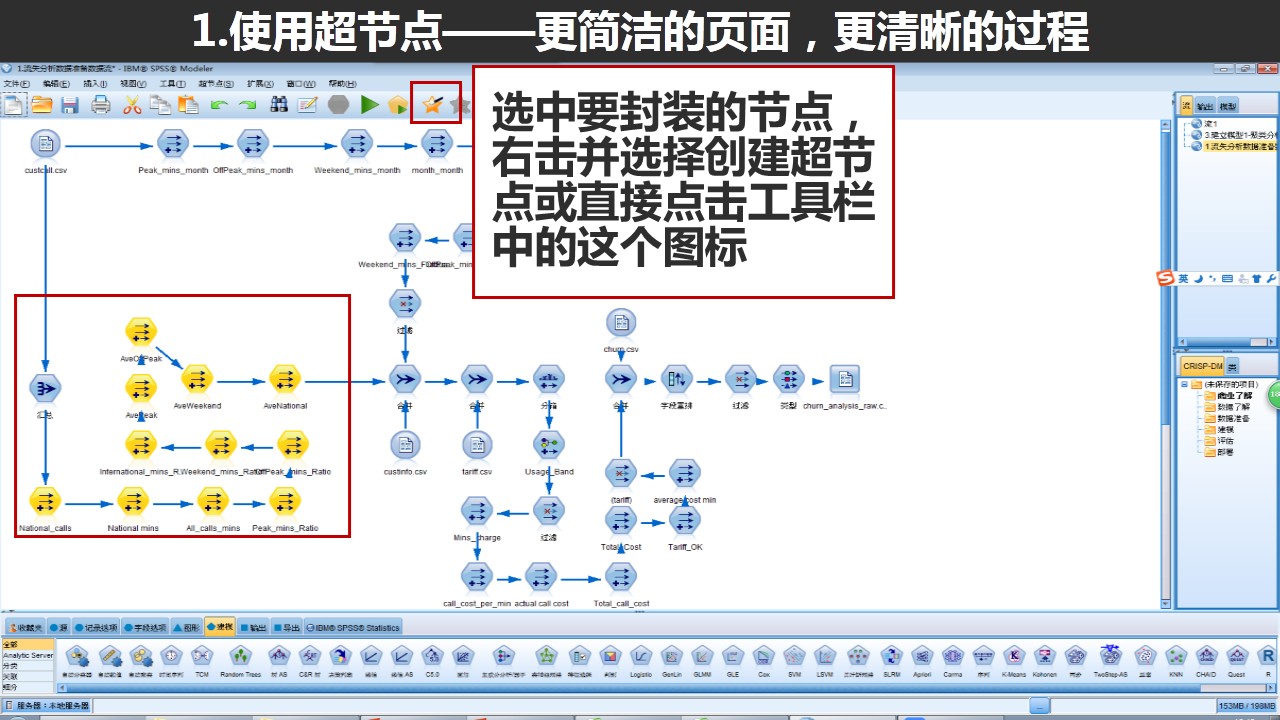
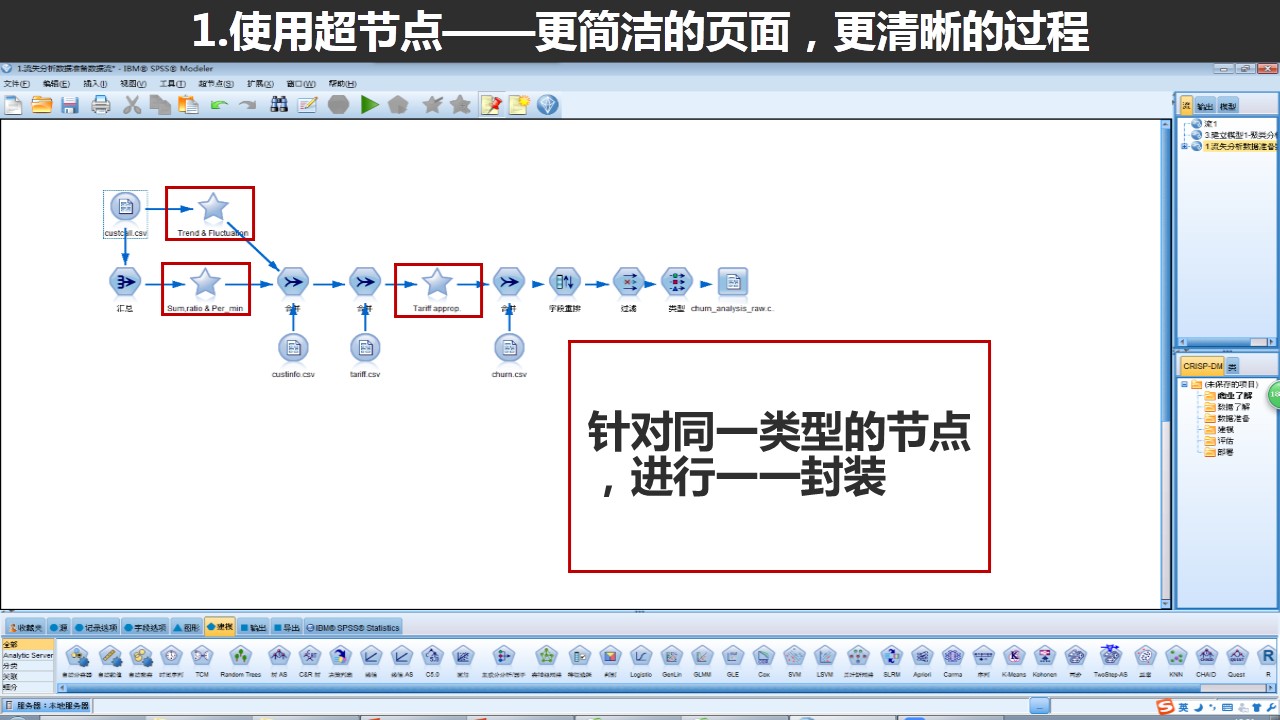
经过超节点的封装,这个数据流变得更加简洁清晰了。一般来说,我们会把实现功能大概一致的节点进行封装,如我们使用10个导出节点针对10个变量进行新的字段计算。
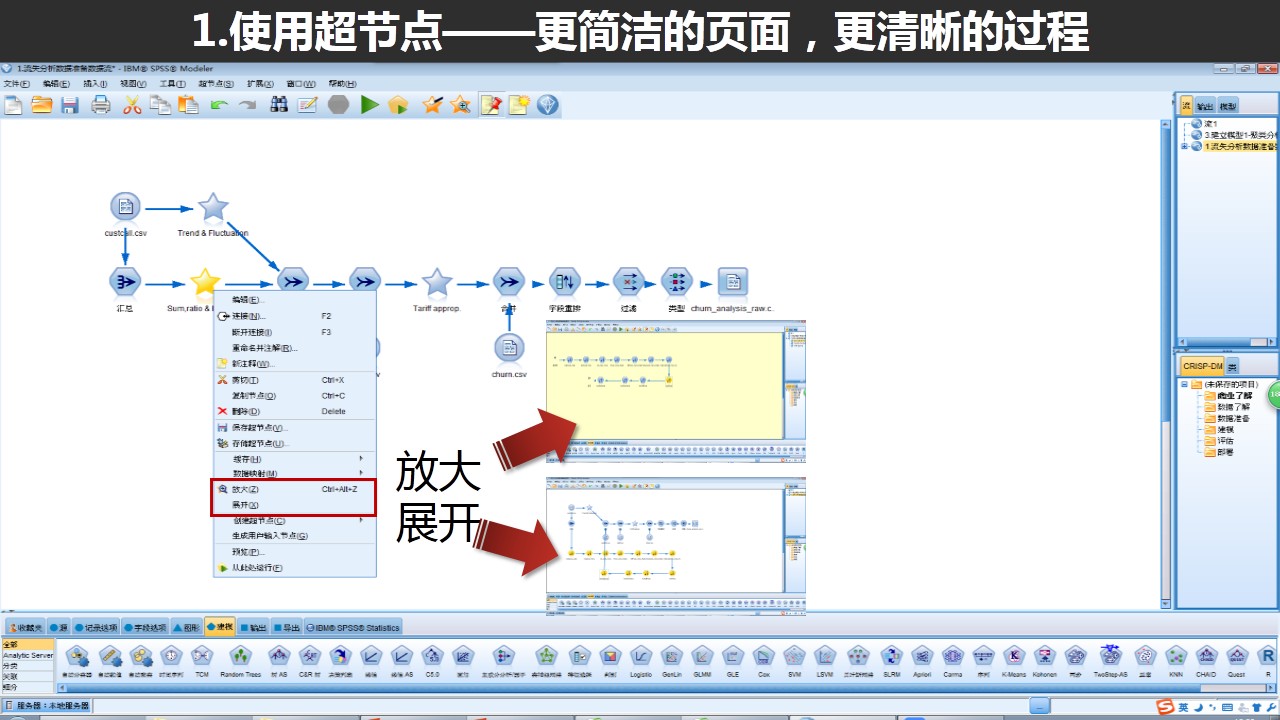
右键超节点,选择“放大”选项,将进入超节点内部查看具体细节;选择“展开”选项,则会拆开超节点,恢复原来状态;
二
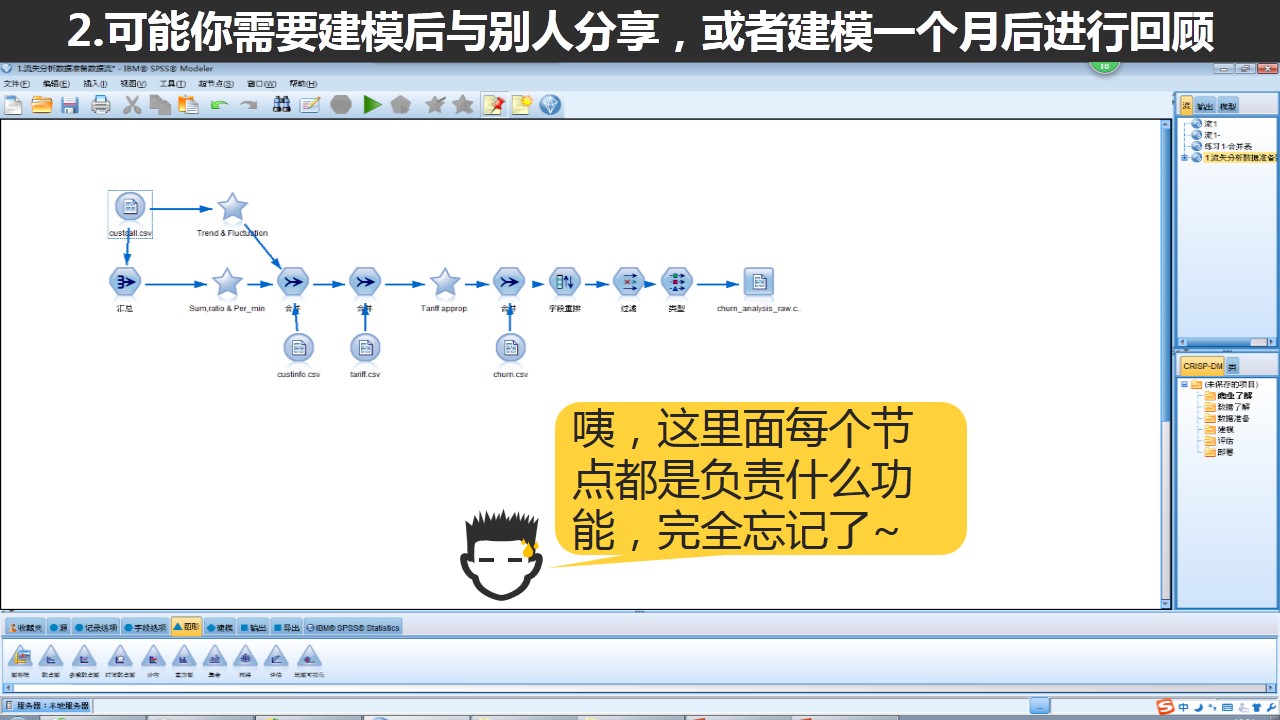
即使使用超节点将整个数据流变得更加直观与清晰,但是太多的的节点承担大量不同的工作,往往事后,即使建模工程师也需要大量时间才能回顾整个建模逻辑。
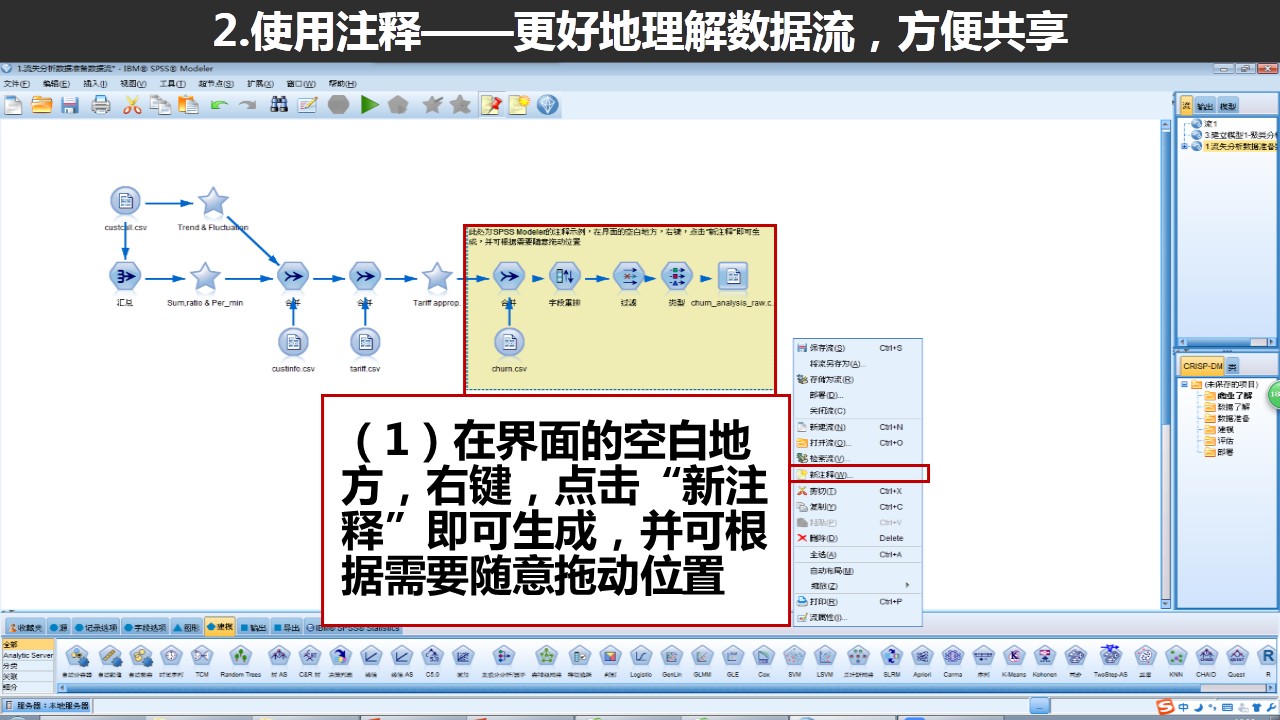
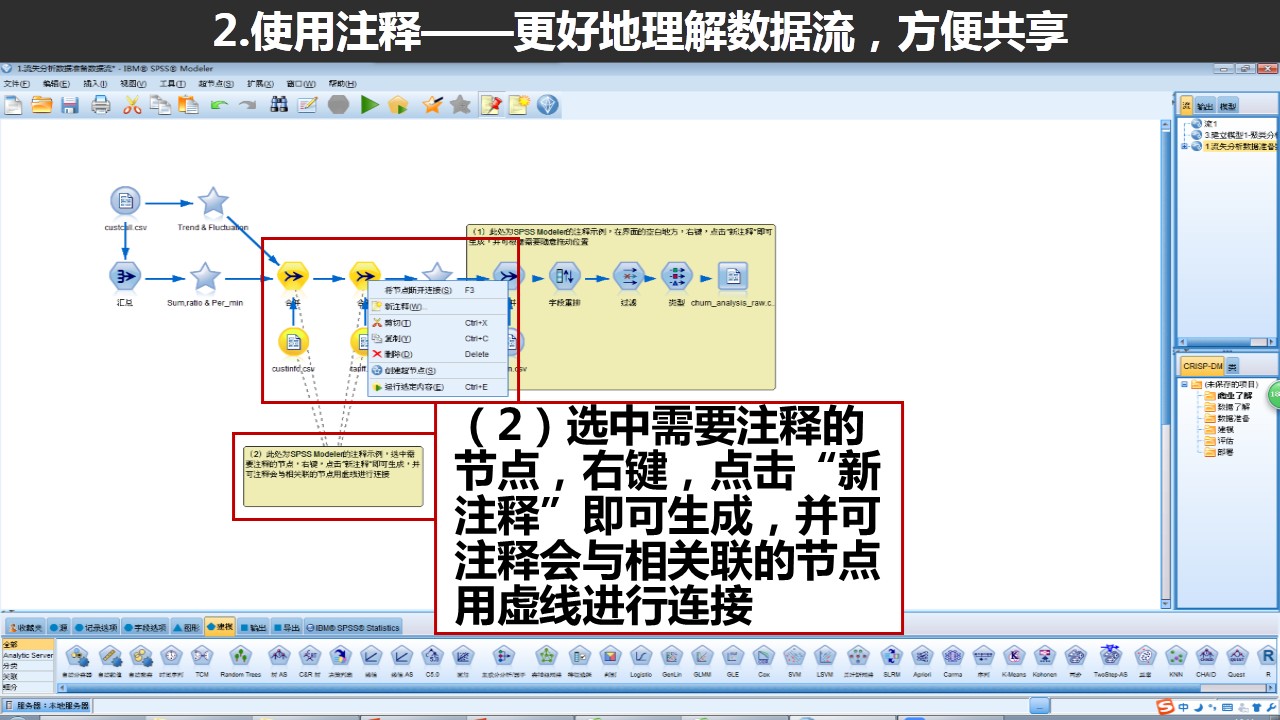
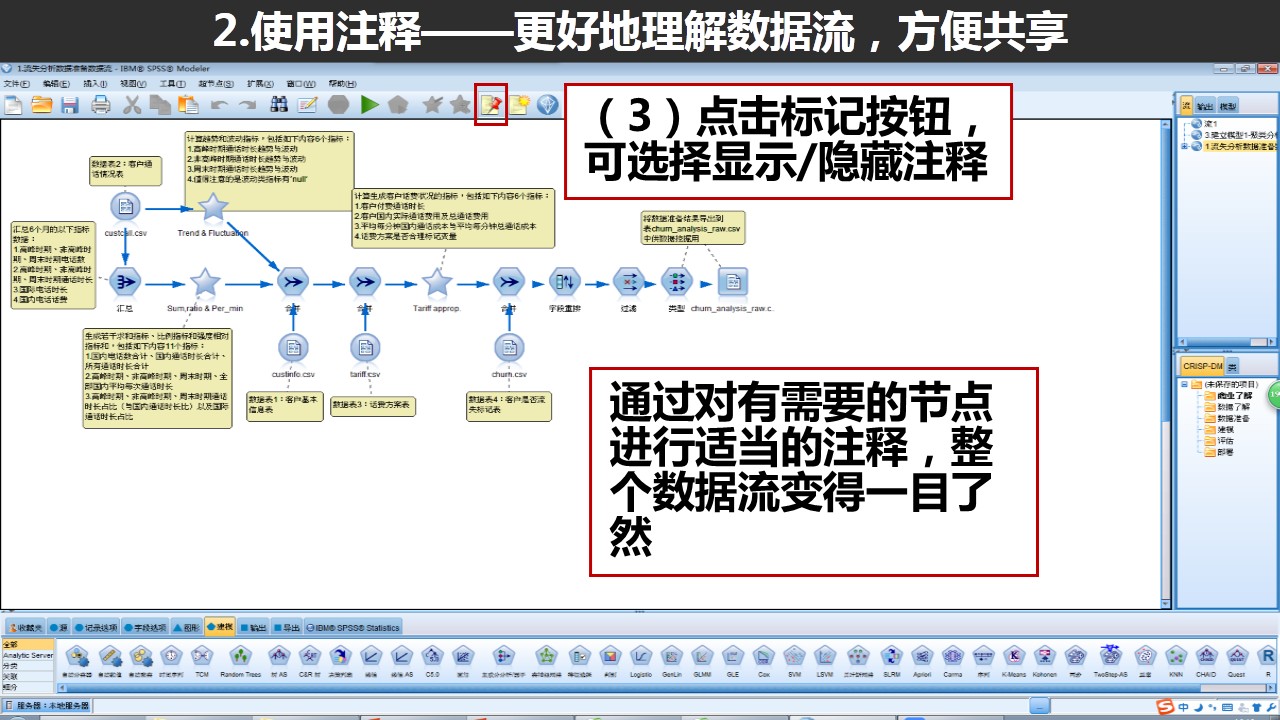
三
在构建一个数据流的时候,由于需要加入很多的节点,并且需要不断地进行测试验证重复运行,因此如果每次测试的时候都需要从数据源节点开始运行的话将会耗费大量的时间。
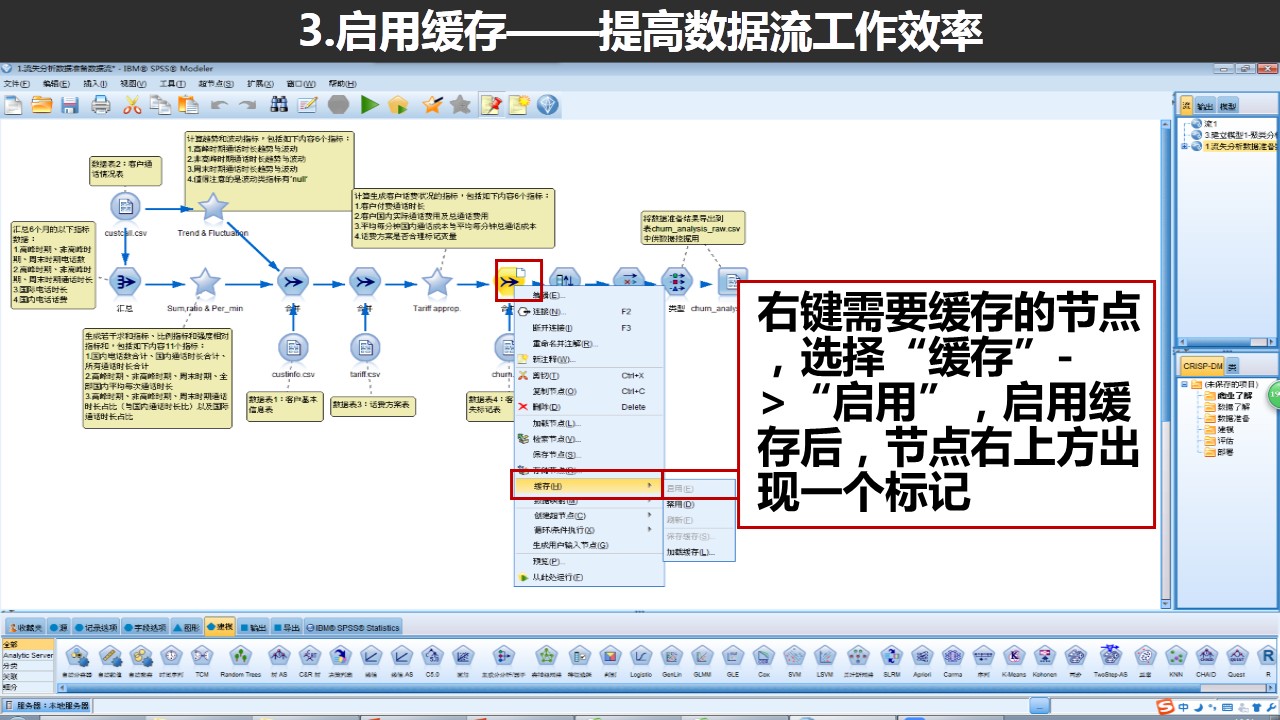
在但是当我们在某节点启用缓存后,Modeler会把到该节点为止的结果保留在内存中,那以后再执行数据流后将直接从该节点之后开始执行,大大提升效率!
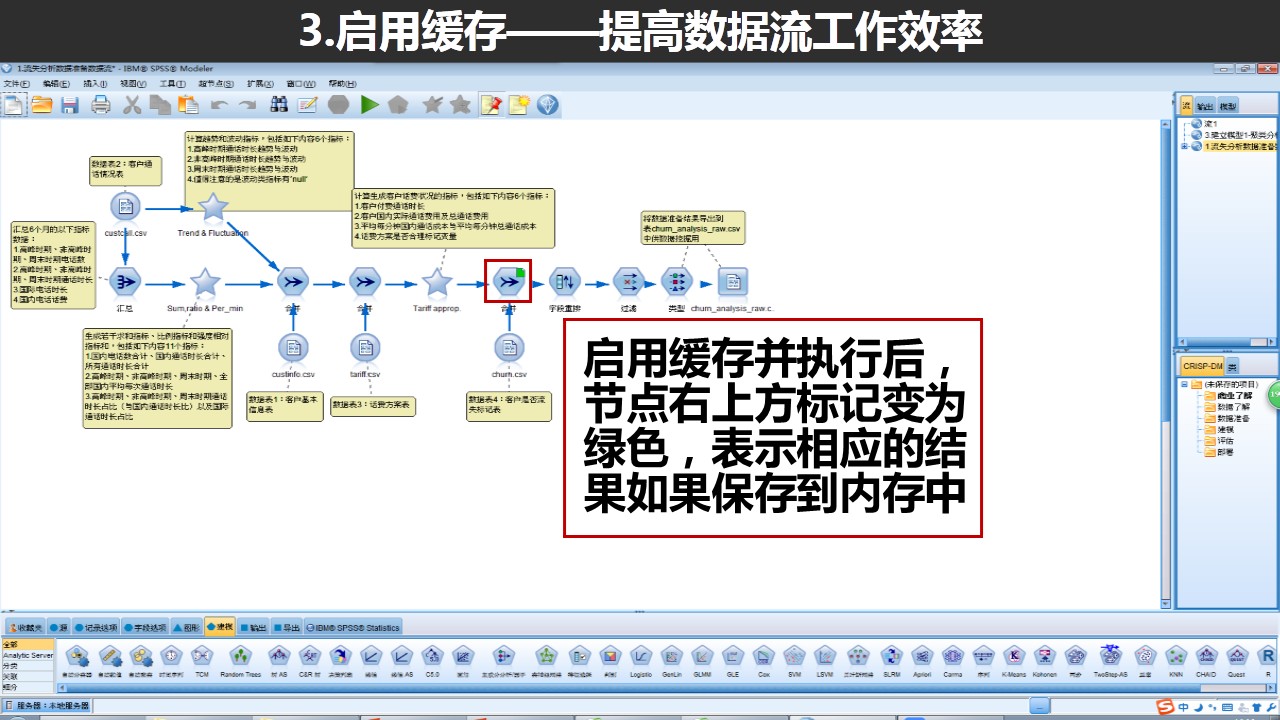
值得注意的是,当位于缓存节点之前的节点发生改变或者关闭Modeler后,缓存也会消失。如果你想在关闭以后继续使用,可以在右键菜单中选择“缓存”-“保存缓存”,Modeler会生成文件保存在指定位置上,那么你下次使用的时候,只需要在同样的节点中,右键菜单,选择“缓存”-“加载缓存”即可以继续使用
四
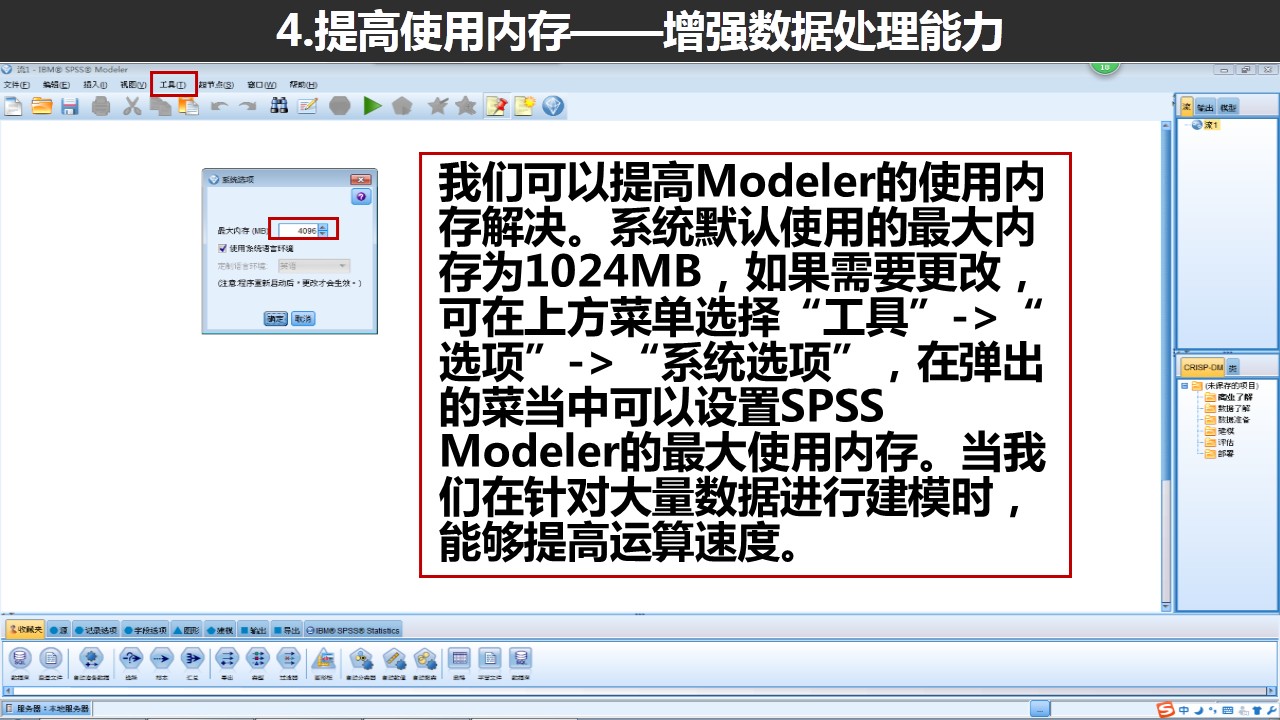
五
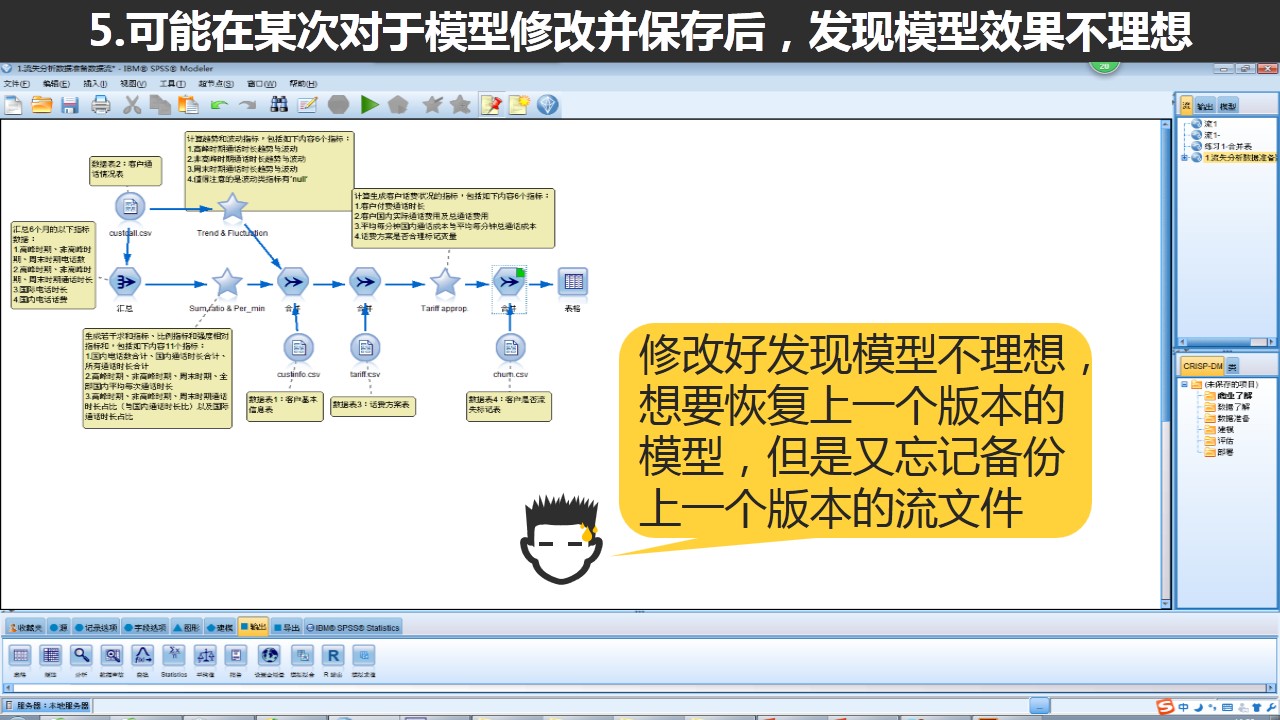
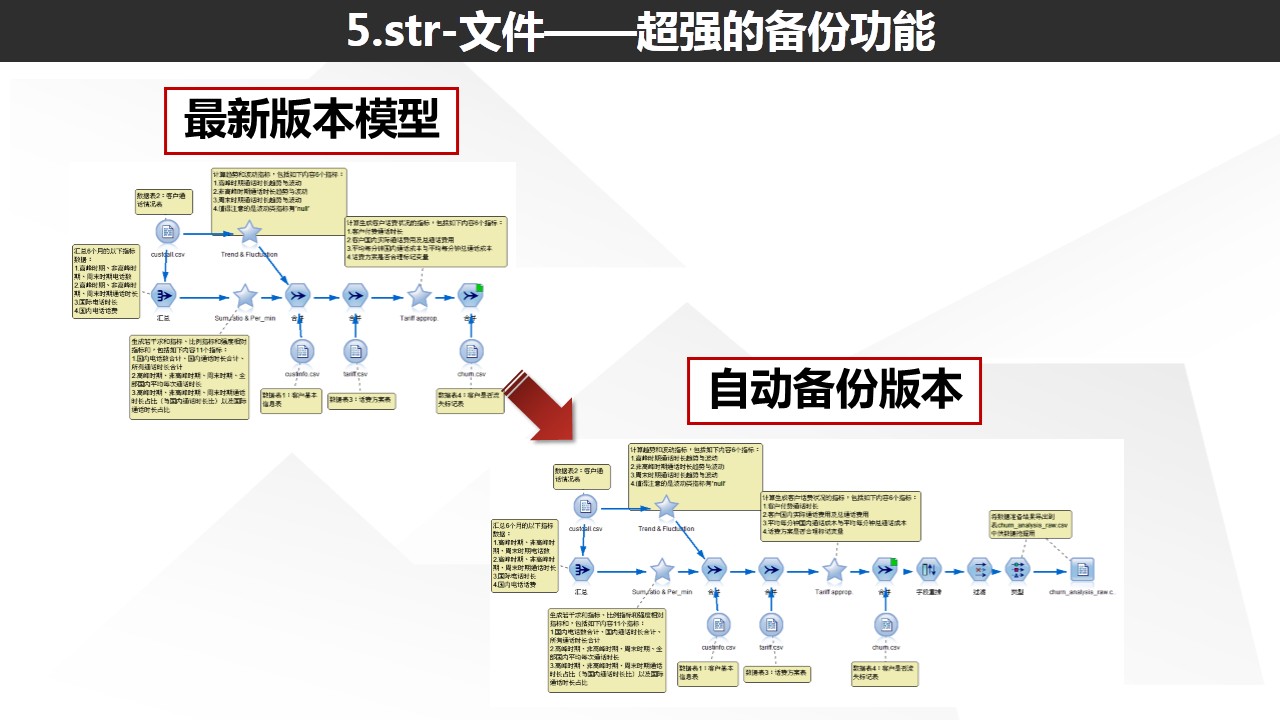
使用IBM SPSS Modeler的同学可能疑惑,对已有的数据流进行保存后,在同样的目录路径会生成一个名称一样,但是后缀名是.srt-的文件,这个文件是干什么的呢?其实这个文件是我们Modeler帮我们自动备份的文件。

重新修改.str-的后缀名,更改为.str即可使用上一个版本的文件了。
浩彬老撕正在努力做一些事情,希望能够以比较轻松的方式为大家讲述一些统计学,数据挖掘的知识,包括算法,包括工具使用问题,也包括一些科技八卦,同时也会举办一些送书活动(咱第一期送的是《数学之美》),希望大家能够喜欢。另外如果你想联系我,欢迎在公众号中直接发送你想说的话与浩彬老撕直接交流~
长按二维码即可关注!如果你觉得浩彬老撕的内容还不错,希望你可以推荐给其他小伙伴↓↓↓


