闲来无事,在博客园的论坛里随意游荡,看到一个开源的python库,名字叫做结巴分词,一直很好奇这些自然语言的处理方式,但是网上的相关介绍却少的可怜,仅有的一些博客写介绍的比较浅。幸好代码量不多,花了两周的时间把代码和设计的算法仔细的梳理了一边,供大家参考,也希望能够抛砖引玉。
分词算法介绍
先看一下分词用到了哪些算法,文档里面如下介绍:
• 基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG)
• 采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合
• 对于未登录词,采用了基于汉字成词能力的HMM模型,使用了Viterbi算法
实现方案
估计是我水平比较菜,反正我看完之后不知所云。废话也不说了,下面好好来讲讲代码,结巴分词最顶层的目录jieba下有如下文件,dict.txt是一个词库,里面记录了大约350000个词语的词频和词性,结巴分词提供的功能接口都定义和实现在__init__.py中,finalseg文件夹中提供了隐马尔科夫维特比算法相关的代码,用于文本切词;analyse中提供了TF-IDF算法和textrank算法相关的实现,可以用于提取文章关键词以及文本摘要;唯一让我比较抑或的是posseg文件夹中的代码,和finalseg极其相似,实在猜测不出添加这么一个文件夹的意图。
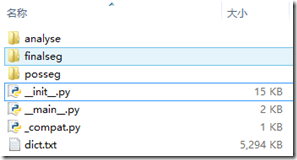
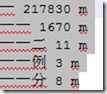
概括的讲完结巴分词的文件结构后,再详细的讲一讲各个文件的内容。dict.txt的内容如下图所示,里面有每个词的统计次数和词性,在文档中提到的算法二中用到了词的统计次数,但是似乎所有的算法都没有用到词性,有想法的小伙伴可以尝试改进一下。
_compat.py文件是处理python2和python3之间差异的一个文件,有一个函数strdecode专门用来将字符串转换unicode, 感觉还蛮有用的
def strdecode(sentence): if not isinstance(sentence, text_type): try: sentence = sentence.decode('utf-8') except UnicodeDecodeError: sentence = sentence.decode('gbk', 'ignore') return sentence
__main__.py文件将底层的接口通过命令行的方式暴露给用户,用户可以设置自己的词典,需要处理的文件,是否使用隐马尔可夫模型,这个文件不涉及分词的算法,看起来没有什么难度,原来一直没有搞清楚__main__.py和__init__.py这两个文件的关系,通过万能的度娘总算搞清楚了,这里贴一个链接,http://www.tuicool.com/articles/iYRfe2 写的非常通俗易懂。
__init__.py这个文件是结巴分词的核心,里面提供了分词的接口:cut。它有三种模式:
1. 全模式,把句子中所有在词库中出现的词都找出来
2. 不使用隐马尔科夫模型的精确模式,基于最大概率路径, 找出基于词频的最大切分组合
3. 同时使用最大概率路径和隐马尔科夫模型,对于未登录词也有比较好的切分效果
这三种模式都会根据字典生成句子中汉字构成的有向无环图(DAG),实现的函数如下:
def get_DAG(sentence): global FREQ DAG = {} N = len(sentence) for k in xrange(N): tmplist = [] i = k frag = sentence[k] while i < N and frag in FREQ: if FREQ[frag]: tmplist.append(i) i += 1 frag = sentence[k:i + 1] if not tmplist: tmplist.append(k) DAG[k] = tmplist return DAG
以“但也并不是那么出乎意料或难以置信”这句话作为输入,生成的DAG如下,简单的讲就是把句子中词的位置标记出来
0 [0] 但
1 [1] 也
2 [2] 并
3 [3, 4] 不是
4 [4] 是
5 [5, 6] 那么
6 [6] 么
7 [7, 8, 10] 出乎意料
8 [8] 乎
9 [9, 10] 意料
10 [10] 料
11 [11] 或
12 [12, 13, 15] 难以置信
13 [13] 以
14 [14, 15] 置信
15 [15] 信
一、全模式 现在看一下全模式的代码:
def __cut_all(sentence): dag = get_DAG(sentence) old_j = -1 for k, L in iteritems(dag): if len(L) == 1 and k > old_j: yield sentence[k:L[0] + 1] old_j = L[0] else: for j in L: if j > k: yield sentence[k:j + 1] old_j = j
就是把上面生成的DAG中的所有的组合显示出来,还是以上面的句子为例,全模式切分的结果如下,是不是觉得这么非常的easy。
但/也/并/不是/那么/出乎/出乎意料/意料/或/难以/难以置信/置信
二、 不使用隐马尔科夫模型的精确模式,用一个比较简单的句子为例,输入的句子是“难以置信”,按照全模式会输出:难以/置信/难以置信 三个组合。作为一个将汉语的人,我们明显知道最佳的分词结果就是“难以置信”这一种结果。下面用最大概率的方法解释为什么是这个结果。子啊字典中我们可以查询“难以置信”所有的组合以及它们出现的概率(除以所有词出现的总次数)如下:
词次数出现概率
难185053.08*10-4
以1361362.27*10-3
置111451.85*10-4
信111881.86*10-4
难以56819.45*10-5
置信641.06*10-6
难以置信1692.81*10-6
根据上面各词的概率,可以算出“难以置信”所有分词方式的概率,而最大出现的可能就是“难以置信”,而且它的概率相比其他组合高的可不是一倍两倍。
分词方式出现概率
难 以 置 信1.37*10-14
难以 置 信3.65*10-14
难 以 置信7.41*10-13
难以 置信1.01*10-10
难以置信2.81*10-6
实现的代码如下,相信参考我的例子,看下面的代码也就不是什么大难题了,在计算概率的时候,结巴分词用的方式是log函数
def calc(sentence, DAG, route): N = len(sentence) route[N] = (0, 0) logtotal = log(total) for idx in xrange(N - 1, -1, -1): route[idx] = max((log(FREQ.get(sentence[idx:x + 1]) or 1) - logtotal + route[x + 1][0], x) for x in DAG[idx]) def __cut_DAG_NO_HMM(sentence): DAG = get_DAG(sentence) route = {} calc(sentence, DAG, route) x = 0 N = len(sentence) buf = '' while x < N: y = route[x][1] + 1 l_word = sentence[x:y] if re_eng.match(l_word) and len(l_word) == 1: buf += l_word x = y else: if buf: yield buf buf = '' yield l_word x = y if buf: yield buf buf = ''三、 同时使用最大概率路径和隐马尔科夫模型
由于这一部分设计到的理论知识比较多,建议先看一下相关的论文和博客。然后再通过代码验证对理论算法的知识,可以更深刻的理解隐马尔科夫模型。在这个地方中文句子作为可观测序列,对应的隐藏状态值集合为(B, M, E, S): {B:begin, M:middle, E:end, S:single}。分别代表每个状态代表的是该字在词语中的位置,B代表该字是词语中的起始字,M代表是词语中的中间字,E代表是词语中的结束字,S则代表是单字成词。
在HMM模型中文分词中,我们的输入是一个句子(也就是观察值序列),输出是这个句子中每个字的状态值。比如:“小明硕士毕业于中国科学院计算所”,隐藏序列为
BEBEBMEBEBMEBES,根据这个状态序列我们可以进行切词:BE/BE/BME/BE/BME/BE/S,所以切词结果如下:小明/硕士/毕业于/中国/科学院/计算/所。
finalseg中有BMES各个状态间的转移概率以及隐藏状态对应于各个中文的发射概率,再根据维特比算法,计算分词就相当的容易了。由于对隐马尔科夫理解有限,也就不瞎写了,有兴趣的可以看一下http://blog.csdn.net/likelet/article/details/7056068,写的非常的赞。
