上一篇讲解了一下,pandas两个主要数据结构之一:用于存放一维数据的Series,本篇介绍一下存放二维数据的Dataframe。
Dataframe(简称df)是pandas处理与分析数据的重要数据结构,df像关系型数据库的表,列是属性,行是记录,行列之间的数据处理方式较SQL来说更灵活多变,能够解决工作中大部分的数据处理任务。
先讲一下Dataframe的声明参数
pandas.DataFrame(data,index,dtype,columns,copy):
data是array或dict;
index表示行索引,默认从0开始分配;
dtype设置数据类型;
columns表示列名;
copy备份数据。
下面进入代码实操:
先引入pandas与numpy
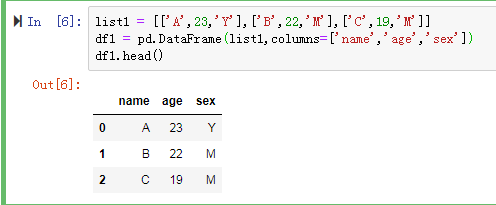
df声明方式1:
声明一个3*3的列表 list1,作为data;
设置列名,columns=['name','age','sex'];
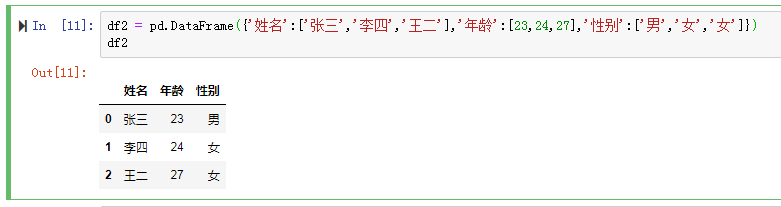
df声明方式2:
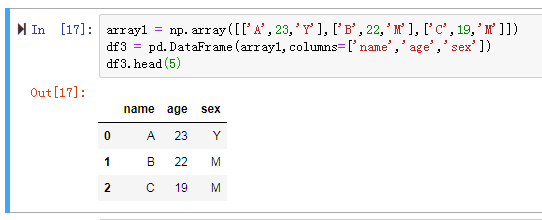
df声明方式3:
接下来,我们尝试一下df基本的功能:
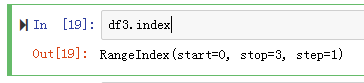
1. df.index
获取行索引
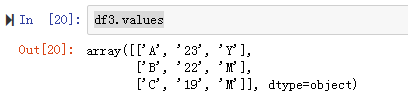
2. df.values
返回ndarray类型的对象,也就是返回df存储的数据
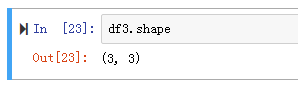
3. df.shape
返回df的形状,也就是几行几列
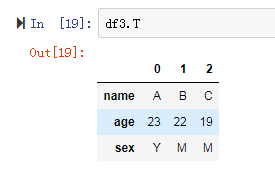
4. df.T
转置
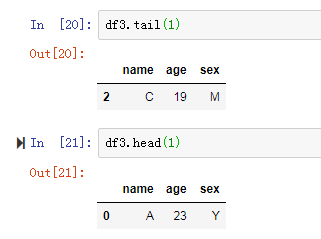
5. df.head()与df.tail()
df前一行与后一行
了解df基本的操作,接下来数据读取,存储,增删改查,等复杂编程。
