
1.写出分析代码

答案:
select
case when a.order_num<=5 then '0-5'
when a.order_num>=6 and a.order_num<=10 then '6-10'
when a.order_num>=11 and a.order_num<=20 then '11-20'
when a.order_num>20 '20以上' end 单量
,count(客户id)
from
(select
客户id
,count(运单号) order_num
from table
where create_time between '2020-05-01' and '2020-05-31'
group by 客户id
) a
group by case when a.order_num<=5 then '0-5'
when a.order_num>=6 and a.order_num<=10 then '6-10'
when a.order_num>=11 and a.order_num<=20 then '11-20'
when a.order_num>20 '20以上' end
2.考察窗口函数的用法
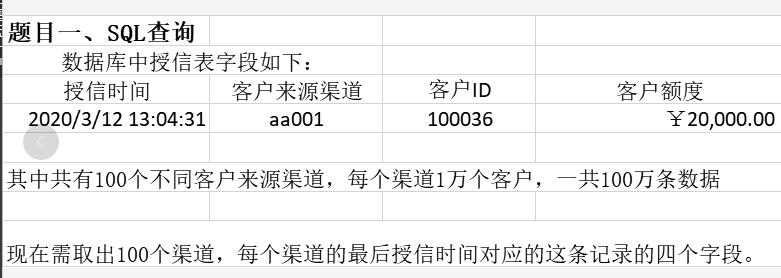
select *
from
(select *
,row_number() over(partition by 渠道 order by 授信时间 desc) rn
from table
) a
where rn=1
3.一张成绩表class有如下字段,班级ID,英语成绩,数学成绩,语文成绩
id english math chinese classid
1 78 89 95 2
2 68 86 79 2
3 59 98 78 1
4 68 96 86 3
5 58 87 68 3
6 97 87 68 3
7 97 87 76 1
8 67 98 97 2
9 78 76 96 1
10 99 99 98 3
求:每个班级英语成绩最高的前两名的分值差为多少?
第一步,首先分组取top2的数据;
select
english,
classid
from
(select
english,
classid,
row_number() over (partition by classid order by english desc) rank
from class) temp1
where rank < 3;
--结果输出
english classid
97 1
78 1
78 2
68 2
99 3
97 3
第二步,将每个班级分组数据的最大值减去最小值;
select
classid,
max(english) - min(english) as eng_difference
from
(select
english,
classid
from
(select
english,
classid,
row_number() over (partition by classid order by english desc) rank
from class) temp1
where rank < 3) temp2
group by classid;
--结果
classid eng_difference
1 19
2 10
3 2
如果求所有的分值差,如下:
select
classid,
max(english) - min(english) as eng_difference,
max(math) - min(math) as math_difference,
max(chinese) - min(chinese) as china_difference
from
(select
english,
math,
chinese,
classid
from
(select
english,
math,
chinese,
classid,
row_number() over (partition by classid order by english desc) rank
from class) temp1
where rank < 3) temp2
group by classid;
--结果输出
classid eng_difference math_difference china_difference
1 19 11 20
2 10 3 16
3 2 12 30
hive中一般取top n时,row_number(),rank,dense_rank()这三个函数就派上用场了,
先简单说下这三函数都是排名的,不过呢还有点细微的区别。
通过代码运行结果一看就明白了。
除Row_number外还有rank,dense_rank
以下是语法:
rank() over([partition by col1] order by col2)
dense_rank() over([partition by col1] order by col2)
row_number() over([partition by col1] order by col2)
功能差不多,但是有细微的差别
row_number的排序不允许并列,即使两条记录的值相等也不会出现相等的排序值
rank排序时出现相等的值时会有并列,即值相等的两条数据会有相同的序列值
dense_rank排序的值允许并列,但会跳跃的排序,像这样:1,1,3,4,5,5,7.
select empid,
deptid,
salary,
rank()over( order by deptid desc ) rank,
dense_rank() over( order by deptid desc ) dense_rank,
row_number()over( order by deptid desc) row_number
from employee
rank() 排序相同时会重复,总数不会变
dense_rank()排序相同时会重复,总数会减少
row_number() 会根据顺序计算
正好听到一个需求,求sal前50%的人,
基于row_number函数也很容易实现分页:
SELECT
*
FROM
(
SELECT
row_number() over(ORDER BY empid DESC) AS rnum ,
employee.*
FROM
employee
) t
WHERE
rnum >= 1
AND rnum <= 5;
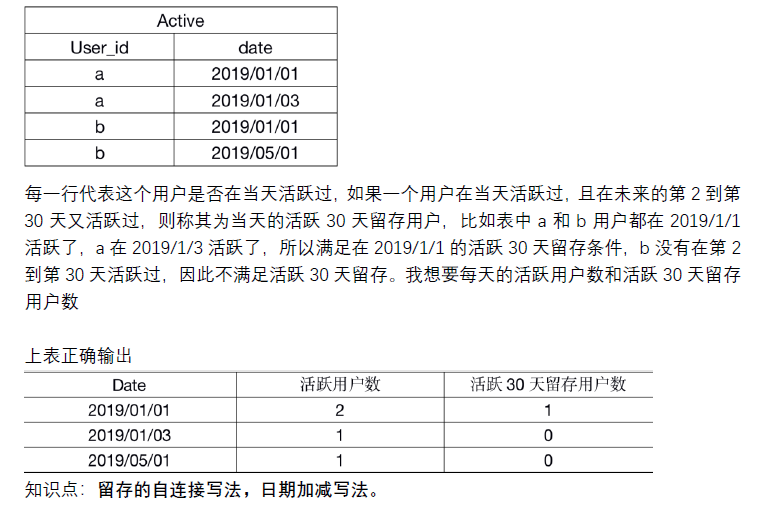
select a.date,count(a.user_id)as '每天活跃用户数',count(b.user_id) as'活跃30天留存用户数'
from (select User_id,date from Activate) a
left join (select User_id,date from Activate) b
on a.User_id=b.User_id
and date_add(a.date,interval 1 day)<=b.date
and b.date<=date_add(a.date,interval 29 day)
group by 1
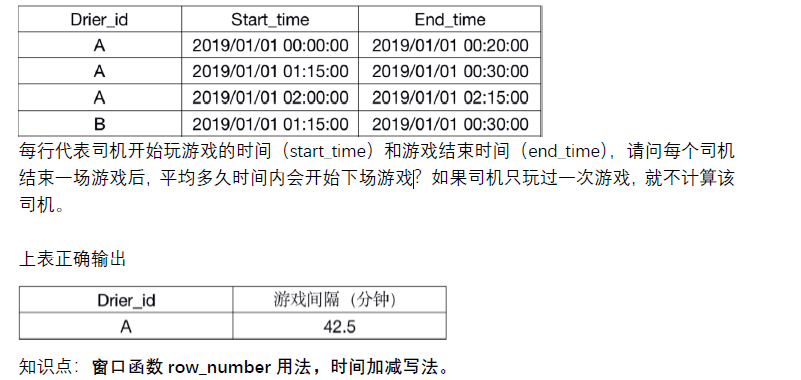
--------求结束一场游戏后,平均多久时间内会开始下场游戏?如果司机只玩过一次游戏,就不计算该
select a.drier_id,avg(timestampdiff(minute,a.end_time,b.start_time))as '平均游戏间隔'
from
(select drier_id,start_time,end_time
,rank() over (partition by drier_id order by start_time) as rank1
from game) a
left join
(select drier_id,start_time,end_time
,rank() over (partition by drier_id order by start_time) as rank2
from game) b
on a.drier_id=b.drier_id
where a.rank1+1=b.rank2
group by 1
6.连续登录天数
题目:数据表table1中记录用户登录日志,包含两列,uid和login_time,需要找出连续登陆3天的用户
样例数据如下(提示:可用窗口函数)
uid,login_time
1,2020-01-01 00:00:00
1,2020-01-02 01:23:45
1,2020-01-01 00:00:00
2,2020-01-01 02:01:00
2,2020-01-01 00:00:00
2,2020-01-01 00:00:00
3,2020-01-01 04:05:00
3,2020-01-02 00:00:00
3,2020-01-03 16:26:00
4,2020-01-01 00:00:00
4,2020-01-02 23:04:34
4,2020-01-04 00:00:00
4,2020-01-05 00:00:00
答案:
--1、连续3天登录SQL
select
uid as `用户数`,
date_sub(t2.login_time,t2.rank) as flag_dt,
count(1) as num --联系登录数
from
(
select
t1.uid as uid,
t1.login_time as login_time,
row_number()over(partition by t1.uid order by t1.login_time) as rank
from
(
select
distinct
uid,
to_date(login_time) as login_time
from table1
)t1
)t2
group by uid, date_sub(t2.login_time,t2.rn)
having count(1) =3
--2、代码注释:
1、第一步:取每天用户登录去重distinct,保证只有一条记录每天;
2、第二步:排序row_number,每个用户登录uid、dt降序打标签;
3、第三步:取用户登录天数,count(1) num=3,取登录3次的;
4、第四步:date_sub(t2.login_time,t2.rank),用户登录时间减去排序,应该是同一天;
5、第五步:取数连续3天登录用户记录
select user_id,p_day_new,count(1)
from (
select user_id,p_day,rn,format_datetime(date_add('day',-rn,from_iso8601_timestamp(p_day)),'yyyy-MM-dd') as p_day_new
from (
select user_id,p_day,row_number() over(partition by user_id order by p_day) as rn
from (
select p_day,user_id
from ug.fact_activity_user_event_detail
group by p_day,user_id
) a
) b
) c
group by user_id,p_day_new
having count(1)>=3
8.查询连续登录天数
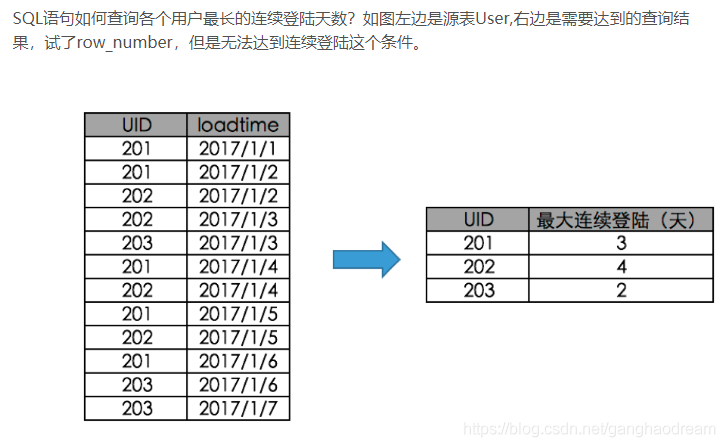
第一步:使用ROW_NUMBER() 窗口函数 按UID分组,按date1升序排
-- 第一段首先根据用户分组,登陆时间排序,结果按照登陆时间升序排列
SELECT
UID,
date1,
row_number() OVER(PARTITION BY UID order by date1) as sort
FROM user_login
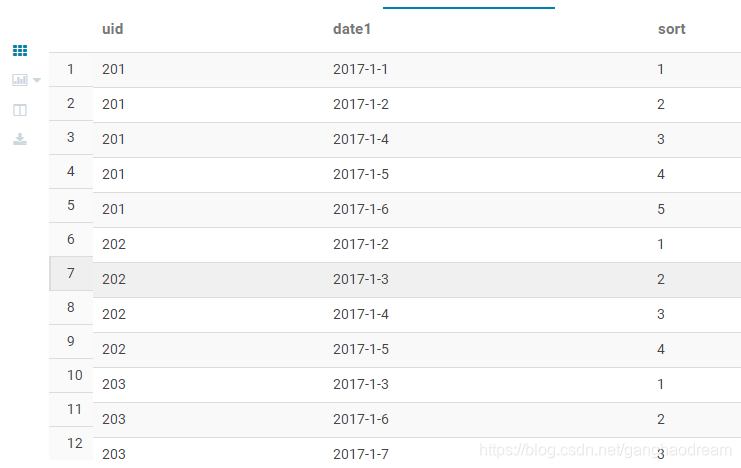
第二步:判断是否连续:
(升序排序后 : 用date1-sort 如果连续则做差后值一样,然后再用UID,login_group分组算出每个UID下连续的天数)
SELECT
UID,
date_sub(date1,sort) as login_group,
min(date1) as start_date1,
max(date1) as end_date1,
count(1) as continuous_days
FROM (
-- 第一段首先根据用户分组,登陆时间排序,结果按照登陆时间升序排列
SELECT
UID,
date1,
row_number() OVER(PARTITION BY UID order by date1) as sort
FROM user_login
) a
GROUP BY UID,date_sub(date1,sort)
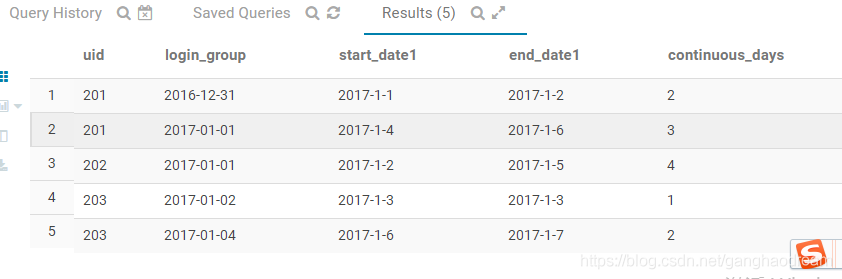
第三步:再以UID分组,去取max(continuous_days)
SELECT
UID,
max(continuous_days) as maxday
FROM
(
SELECT
UID,
date_sub(date1,sort) as login_group,
min(date1) as start_date1,
max(date1) as end_date1,
count(1) as continuous_days
FROM (
-- 第一段首先根据用户分组,登陆时间排序,结果按照登陆时间升序排列
SELECT
UID,
date1,
row_number() OVER(PARTITION BY UID order by date1) as sort
FROM user_login
) a
GROUP BY UID,date_sub(date1,sort)
)b
GROUP BY UID

表:create table user_mission_finish_table
(
userid string comment '用户id',
missionid string comment '任务id',
finish_dt string comment '完成日期'
)
注意:只有用户mission完成了,才会有记录,如:2020-08-01日,用户没有做mission,表中无该用户2020-08-01日的记录
连续完课定义: 指相邻2天都完成了课程任务,如:2020-08-18日完成任务1,2020-08-19日完成任务3,则用户是一个有连续完课记录的用户
问题:
1.有连续学习行为的用户数
2.计算用户历史以来最大的连续学习天数,并按倒序输出,输出字段:用户id,最大连续学习天数数
2.
----1、有连续学习行为用户数
select保存草稿
count(distinct t3.uid) as `有连续学习行为用户数`
from
(
select
uid,
date_sub(t2.finish_dt,t2.rn) as flag_dt,
count(1) as num --连续登录数
from
(
select
t1.uid as uid,
t1.finish_dt as login_time,
row_number()over(partition by t1.uid order by t1.finish_dt) as rank
from
(
select
distinct --用户当天完成数据去重
userid as uid,
to_date(finish_dt) as finish_dt --完成时间
from user_mission_finish_table
)t1
)t2
group by uid,date_sub(t2.login_time,t2.rn)
having count(1) >=2 --连续两天及其以上学习记录
)t3;
----2、有连续学习行为用户,输出最大连续学习天数
select
uid as `连续最大学习用户数`,
max(t3.num) as `连续最大学习天数`
from
(
select
uid,
date_sub(t2.finish_dt,t2.rn) as flag_dt,
count(1) as num --连续登录数
from
(
select
t1.uid as uid,
t1.finish_dt as login_time,
row_number()over(partition by t1.uid order by t1.finish_dt) as rank
from
(
select
distinct --用户当天完成数据去重
userid as uid,
to_date(finish_dt) as finish_dt --完成时间
from user_mission_finish_table
) t1
) t2
group by uid, date_sub(t2.login_time,t2.rn)
having count(1) >=2 --连续两天及其以上学习记录
)t3
group by t3.uid;
-----3.
问题:user_id month【order_time】 amt
1 20170101 100
3 20170101 20
4 20170101 30
1 20170102 200
2 20170102 240
3 20170102 30
4 20170102 2
1 20170101 180
2 20170101 250
3 20170101 30
4 20170101 260
......
[Hive SQL/MaxCompute SQL]统计amt连续3个月,环比增长>50%的user
select
distinct
t1.user_id,
if((t3.amt-t2.amt)/t2.amt >0.5 and (t2.amt-t1.amt)/t1.amt >0.5,'连续3月环比超50%',null) as `用户标签`
from
(
select
month(order_time) as month,
user_id,
sum(amt) as amt
from user_order_whole --假定该表为订单全量表
where dt ='20171231
and to_date(order_time) between '20170101' and '20171231'
group by month(order_time),user_id
)t1
left join
(
select
month(order_time) as month,
user_id,
sum(amt) as amt
from user_order_whole --假定该表为订单全量表
where dt ='20171231
and to_date(order_time) between '20170101' and '20171231'
group by month(order_time),user_id
)t2
on t1.user_id=t2.user_id
(
select
month(order_time) as month,
user_id,
sum(amt) as amt
from user_order_whole --假定该表为订单全量表
where dt ='20171231
and to_date(order_time) between '20170101' and '20171231'
group by month(order_time),user_id
)t3
on t1.user_id=t3.user_id
where (t2.month-t1.month)=1 and (t3.month-t1.month)=2
having (t3.amt-t2.amt)/t2.amt >0.5 and (t2.amt-t1.amt)/t1.amt >0.5
select
distinct
t1.user_id,
if((t3.amt-t2.amt)/t2.amt >0.5 and (t2.amt-t1.amt)/t1.amt >0.5,'连续3月环比超50%',null) as `用户标签`
from
(
select
month(order_time) as month,
user_id,
sum(amt) as amt
from user_order_whole --假定该表为订单全量表
where dt ='20171231'
and to_date(order_time) between '20170101' and '20171231'
group by month(order_time),user_id
)t1
left join
(
select
month(order_time) as month,
user_id,
sum(amt) as amt
from user_order_whole --假定该表为订单全量表
where dt ='20171231'
and to_date(order_time) between '20170101' and '20171231'
group by month(order_time),user_id
)t2
on t1.user_id=t2.user_id
left join
(
select
month(order_time) as month,
user_id,
sum(amt) as amt
from user_order_whole --假定该表为订单全量表
where dt ='20171231'
and to_date(order_time) between '20170101' and '20171231'
group by month(order_time),user_id
)t3
on t1.user_id=t3.user_id
where (t2.month-t1.month)=1 and (t3.month-t1.month)=2
having (t3.amt-t2.amt)/t2.amt >0.5 and (t2.amt-t1.amt)/t1.amt >0.5
6.连续几天内有服务行为的用户
#前7天里面有4天服务的用户
SELECT driver_id from s_order_base_info_a_holo
where bi_cate_id=3
and (
(unload_time>date_trunc('day', now()) - interval '7d' and unload_time<date_trunc('day',now()))
or (service_time>date_trunc('day', now()) - interval '7d' and service_time<date_trunc('day',now()) and bi_state=8 ) )
group by driver_id having count(distinct to_char(unload_time,'yyyy-mm-dd'))=4