前文传送门:
从零开始学自然语言处理(十六)—— 统计语言模型(上)
在上一章中,我们从语言模型讲到N-gram,并在文末点出了一个N-gram的问题,当训练N-gram的语料库中如果没有出现某种词语组合,导致计算包含这种组合的句子概率计算为0,这显然是不合理的,在训练语料库中不存在不代表在总体中不存在,所以有一种叫做平滑的方法被提出来了。平滑解决了这样一个问题:根据训练集的频率分布,估计那些未在训练集中出现的词在测试集中的概率分布,从而在测试集上获得较为合理的概率分布。
拉普拉斯平滑是一种常用的平滑技术,也称为加1平滑。例如我们使用Bi-gram时,加1平滑的公式如下:
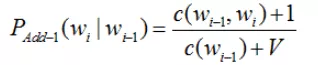
其中,wi和wi-1是相邻的两个词,V为训练中所有不同的Bi-gram数量,其中c代表在训练集出现的次数。举个简单的例子:
训练集:T={数据科学 杂谈 公众号 可以 带你 学习 数据科学 知识}。
需要计算概率的句子:V={数据科学 杂谈 公众号 挺好}。
不经过平滑处理,使用Bi-gram,需要计算的句子的概率为:p(数据科学 杂谈 公众号 挺好)=0,因为这个式子按照Bi-gram公式展开后有一项为p(挺好|公众号)=0,如果忘记了,可以看上一篇的内容。此时使用加1平滑,V=7,即训练集的Bi-gram为:{数据科学 杂谈}、{杂谈 公众号}、{公众号 可以}、{可以 带你}、{带你 学习}、{学习 数据科学}、{数据科学 知识}。
我们可以计算加1平滑后的条件概率:
p(挺好|公众号)=(c(公众号,挺好)+1)/(c(公众号)+V)=(0+1)/(1+7)=0.125同理可以算出以下概率:
p(公众号|杂谈)=(1+1)/(1+7)=0.25
p(杂谈|数据科学)=(1+1)/(2+7)=2/9p(数据科学) =1 (因为训练集中以“数据科学”开头的句子概率为1)于是p(数据科学杂谈公众号挺好)=1*2/9*0.25*0.125=0.00694
加1平滑有效解决了训练集中未出现过的N-gram概率为0的问题。我们再来想想为什么分母要加V?而不是加上任意一个其他数呢?难道不是保证分子和分母都不为0就可以了么?其实,当分子加1后,为了保证概率和为1,即确定了w之后, 对于某个条件概率 p(Wi | W) 需要有:p(w1|w)+p(w2|w)+...+p(wn|w)=1分子上每一个计数都加1,则所有分子一共加了V个1,此时需要分母加V才能让总和为1,即概率之和为1。归纳为数学公式表示如下:
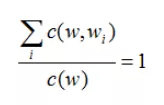
这就是分子加1后,分母加V的原因。
扫码下图关注我们不会让你失望!

