在前面几篇文章中我们已经学会了如何了编写Spider去获取网页上所有的文章链接及其对应的网页目标信息。在这一篇文章中,我们将主要介绍Scrapy中的Item。
在介绍Item之前,我们需要知道明确一点,网络爬虫的主要目标就是需要从非结构化的数据源中提取出结构化的数据,在提取出结构化的数据之后,怎么将这些数据进行返回呢?最简单的一种方式就是将这些字段放到一个字典当中来,然后通过字典返回给Scrapy。虽然字典很好用,但是字典缺少一些结构性的东西,比方说我们容易敲错字段的名字,容易导致出错,比方说我们定义一个字段comment_nums,但是在另外一个爬虫中我们将传递过来的该字段写成comment_num,少了个s,那么届时到pipeline中统一处理字典的时候就会发生错误。
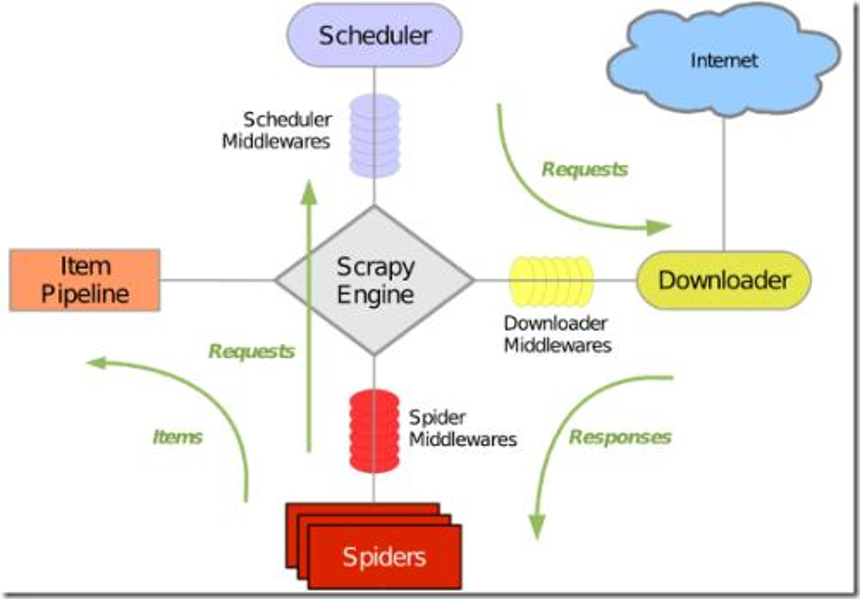
为了将字段进行完整的格式化,Scrapy为我们提供了Item类,这些Item类可以让我们自己来指定字段。比方说在我们这个Scrapy爬虫项目中,我们定义了一个Item类,这个Item里边包含了title、release_date、url等,这样的话通过各种爬取方法爬取过来的字段,再通过Item类进行实例化,这样的话就不容易出错了,因为我们在一个地方统一定义过了字段,而且这个字段具有唯一性。
这个Item有些类似我们常说的字典,但是它的功能要比字典更加齐全一些。同时当我们对Item进行实例化之后,在Spider爬虫主体文件里边,我们通过parse()函数获取到目标字段的Item类,我们直接将这个类进行yield即可,然后Scrapy在发现这是Item类的一个实例之后,它就会直接将这个Item载入pipeline中去。这样的话,我们就可以直接在pipeline中进行数据的保存、去重等操作。以上就是Item带给我们的好处。
接下来我们一起来到items.py文件,去定义item,如下图所示。
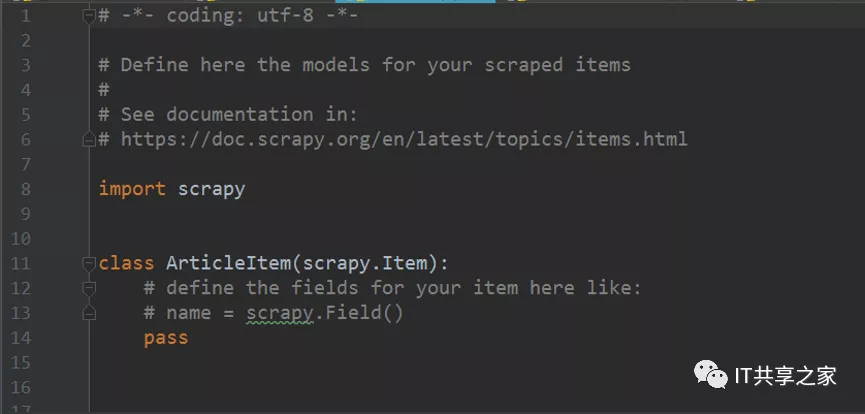
在这个文件中默认已经给出了示例代码,我们可以直接在这个示例代码中写入代码,当然也可以自定义的重新写一个类,形如示例代码这种模式即可。这个类需要继承scrapy中的Item,默认是已经给出来的,即scrapy.Item。下面我们根据自己待获取的目标信息的字段,在这个Item中去定义具体的字段。关于具体目标信息的字段提取,在之前的文章也有提及,主要有title、release_date、url、front_img_url、tag、voteup_num、collection_num、comment_num、content等,如下图所示。

在Item当中,它只有Field这一种类型,这个Field表示任何传递进来的数据类型都可以接收的,从这个角度来看,确实和字典有些相似。在这个文件中主要是更改字段,Item的右边统一为scrapy.Field()。由于需要不断的进行复制,这里介绍一个在Pycharm中的快捷键Ctrl+d,这个快捷键可以自动的复制鼠标光标所在的某一行的代码,可以很快的帮助我们复制代码,相当于Windows下的Ctrl+c和Ctrl+v。

至此,关于Scrapy爬虫框架中的items.py文件的介绍至此先告一段落,目前我们已经完成了所有item的定义,定义完成之后,接下来我们便可以去爬虫主体文件中对具体的item值分别进行填充了。
看完本文有收获?请转发分享给更多的人
IT共享之家
入群请在微信后台回复【入群】

