关联规则挖掘是数据挖掘中最活跃的研究方法之一,最早是针对购物篮分析问题提出的,其目的是为了发现交易数据库中不同商品之间的联系规则,这些规则刻画了顾客购买行为模式,可以用来指导商家科学地安排进货,库存以及货架设计等。而Apriori算法是第一个关联规则挖掘算法,也是最经典的算法。
以如下的场景为例,使用Python快速实现Apriori算法:
1.场景与需求
一家超市的业务数据库中有销售订单表如下:
id为订单号,name为商品名称
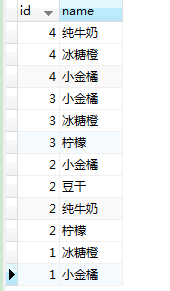
由此我们展开关联规则的挖掘分析
2.环境准备
安装包:
pip install apyori
测试一下:
from apyori import apriori
3.数据准备与处理
由于目前数据库中以行列的形式存放数据,即:订单号-商品名称,若要使用apriori算法,无论使用SPSS还是Python都需要将数据处理成如下的数据结构:
[[订单1商品集],[订单2商品集],[订单3商品集],[订单4商品集]]。
由此展开如下处理步骤:
(1)数据准备

(2)数据处理
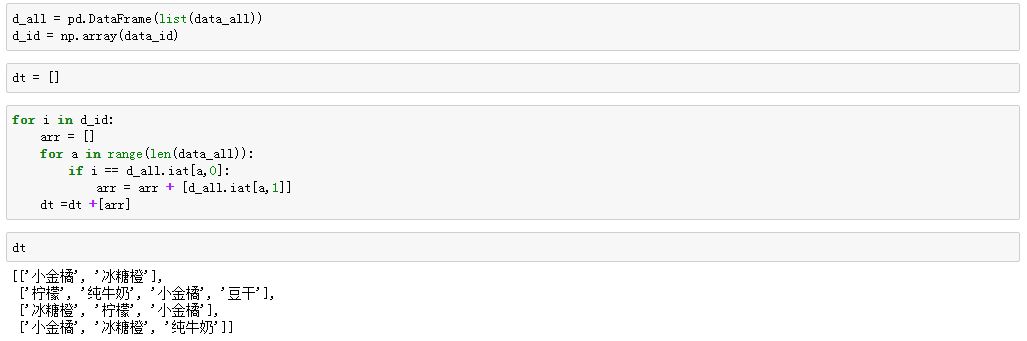
4.关联规则挖掘与说明
代码如下:


结果表如下:

在这里使用apriori算法库时,要了解它到一些参数如下:
Support(支持度):表示同时包含 A 和 B 的事务占所有事务的比例。如果用 P(A) 表示包含 A 的事务的比例,那么 Support = P(A & B);
Confidence(可信度):表示包含 A 的事务中同时包含 B 的事务的比例,即同时包含 A 和 B 的事务占包含 A 的事务的比例。公式表达:Confidence = P(A & B)/ P(A);
Lift(提升度):表示“包含 A 的事务中同时包含 B 的事务的比例”与“包含 B 的事务的比例”的比值。公式表达:Lift = ( P(A & B)/ P(A) ) / P(B) = P(A & B)/ P(A) / P(B)。提升度反映了关联规则中的 A 与 B 的相关性,提升度 > 1 且越高表明正相关性越高,提升度 < 1 且越低表明负相关性越高,提升度 = 1 表明没有相关性。
因此,在apriori算法中我们可以传入如下参数,来筛选项集:
min_support -- The minimum support of relations (float).最小支持度
min_confidence -- The minimum confidence of relations (float).最小可信度
min_lift -- The minimum lift of relations (float).最小提升度
max_length -- The maximum length of the relation (integer).序列最小长度
传入如下参数:

/*原创,转载请联系!*/
