文章发布于公号【数智物语】 (ID:decision_engine),关注公号不错过每一篇干货。
作者:Alexandre Gonfalonieri
编译:ronghuaiyang
导读
当你把一个模型投入生产,它就开始退化,那这个时候,我们该怎么办呢。

由于意外的机器学习模型退化导致了几个机器学习项目的失败,我想分享一下我在机器学习模型退化方面的经验。实际上,有很多关于模型创建和开发阶段的宣传,而不是模型维护。
假设机器学习解决方案一旦投入生产,无需维护就能完美运行,这是一个错误的假设,是企业将其首款人工智能(AI)产品推向市场时最常见的错误。
当你把一个模型投入生产,它就开始退化
01为什么机器学习模型会随着时间退化?
你可能已经知道,数据是成功的ML系统中最重要的组成部分。有一个相关的数据集为你提供准确的预测是一个很好的开始,但是这些数据提供准确的预测能持续多久呢?
在所有ML项目中,预测数据将如何随时间变化是关键。在一些项目中,我们低估了这一步,并且很难交付高精确度。在我看来,一旦你在PoC阶段之后对你的项目有信心,就应该制定一个计划来保持模型的更新。
事实上,在开始使用它之前,你的模型的准确性将处于最佳状态。这一现象被称为概念漂移,尽管在过去的20年里学术界对其进行了大量的研究,但在行业最佳实践中它仍然经常被忽略。
概念漂移: 表示模型试图预测的目标变量的统计特性随着时间以不可预见的方式发生变化。这导致了一些问题,因为随着时间的推移,预测的准确性会降低。
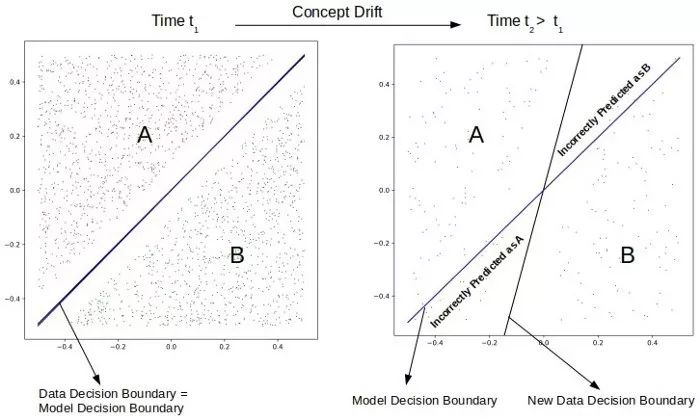
关键是,与计算器相比,ML系统确实与现实世界交互。如果你使用ML来预测你的商店的需求和价格,你最好考虑一下本周的天气、日历和你的竞争对手在做什么。
在概念漂移的情况下,我们对数据的解释随时间而变化,而数据的一般分布则没有变化。这导致最终用户将模型预测解释为随着时间的推移,对相同/相似数据的预测已经恶化。数据和概念都可能同时漂移,使问题更加棘手。
我注意到,依赖于人类行为的模型可能特别容易退化。显然,风险可以根据项目的性质进行预测。在大多数情况下,必须制定定期的模型评审和再训练计划。
此外,大多数模型只能捕获反映它们所看到的训练数据的模式。一个好的模型捕获了这些数据的基本部分,而忽略了不重要的部分。这创建了泛化的性能,但是任何模型都有一定程度的局限性。
泛化: 指的是你的模型能够适当地适应新的、以前未见过的数据,这些数据来自于用于创建模型的相同分布。这与过拟合的概念密切相关。如果你的模型过拟合,那么它就不能很好地泛化。

泛化性能的最佳测试是查看模型在很长一段时间内对真实数据的执行情况。这个过程至少有两个主要元素。
02如何防止模型退化?
这听起来可能很明显,但是在部署之后监视ML性能非常重要。如果监视所有特征听起来像一项耗时的任务,那么我们可以监视一些关键特征,这些特征的数据分布变化可能会严重影响模型结果。我强烈建议你在投入生产之前为这个过程创建一个策略(通过识别正确的元素)。
模型监控是一个持续的过程
如果你观察到模型性能下降,那么是时候重新构造模型设计了。棘手的部分不是刷新模型和创建一个重新训练的模型,而是考虑额外的特征,这些特征可能会提高模型的性能,使其更加可靠和准确。
完成上述步骤之后,就可以使用新的或修改过的一组特征和模型参数重新创建模型了。在这一点上,我们的目标是确定一个最优的模型,该模型能够提供最佳的精度,这很好地概括了一些数据漂移。
我注意到,在某些情况下,模型的重新创建并不能提高模型的性能。在这些情况下,分析模型出错的例子并寻找当前特征集之外的趋势可以帮助识别新特征。基于这些知识创建新特征可以给模型提供新的学习经验。
03手工学习
我们经常使用新数据来维护模型的一个解决方案是,使用我们最初用于构建模型的相同流程来训练和部署我们的模型。我们称之为手工学习。你可以想象这个过程会很耗时。我们多久对模型进行一次再训练?每周?每天吗?答案取决于你的ML应用。
当我们手工对模型进行再训练时,我们可能会发现一种新的算法或一组不同的特征,可以提高精确度。事实上,定期回顾你的处理过程可能是个好主意。正如我前面提到的,你可能会找到一种不同的算法或一组新的特征来改进你的预测,而这并不是连续学习系统所擅长的。
也许你可以每个月或者每年用之前收集的数据来更新模型。
这还可能涉及对模型进行反向测试,以便在重新拟合静态模型时选择适当数量的历史数据。
04给数据加权重
另一个解决方案可能是给数据加权重。事实上,有些算法允许你权衡输入数据的重要性。
使用与数据年龄成反比的加权系统可能会很有趣,这样会更多地关注最近的数据(权重更高),而较少关注最近的数据(权重更小)。
05持续学习
我最喜欢的方法是拥有一个能够持续评估和重新训练模型的自动化系统。持续学习系统的好处是它可以完全自动化。

一般来说,合理的模型监控与周密的模型检查计划相结合,对于保持生产模型的准确性是至关重要的。对关键变量进行优先级检查,并为发生更改时设置警告,这将确保你不会对环境的更改感到意外,而环境的更改会破坏你的模型的有效性。
对于数据点具有高度独立性的输入变量,可以使用统计过程控制中使用的控制图来检测过程的变化。
06处理模型漂移
我坚持这一点,但你的ML成功也取决于你计划如何维护你训练有素的模型。在几个项目中,我意识到缺乏模型工作经验的商业领袖可能无法预料到这种需求。
一个产品化的模型包括监视和维护
应该定期评估新数据集上的模型性能。应该定期对这些性能跟踪进行可视化和比较,以便您可以确定何时进行干预。有几个度量ML性能的指标。

模型退化的原因可以被明确地发现和建模。可以研究、理解和利用周期性时间效应。一旦模型收集了足够的性能指标,数据科学团队就可以处理这个项目。假设你一直在跟踪他们。
定期考虑性能指标并触发重新训练或重建模型的过程也是必要的,因为没有它,你将能够看到性能损失,但没有适当的系统来解决它。
07投入&团队
除了技术方面,我强烈建议你在项目投入生产后,将最好的数据科学家和工程师留在项目中。与经典的软件项目不同,在部署之后,你的操作团队处理它,工程师继续构建下一个大项目,ML和AI系统中的许多技术挑战是保持它们的准确性。
你还需要投入资源,以保持你的客户使用的机器学习产品和服务的准确性。这意味着与传统软件相比,ML产品的运营边际成本更高。
08维护成本
为了维护高质量的模型,应该在每次数据交付时对算法进行再训练。另一方面,为了优化成本,应该尽可能少地去做。
显然,某些机器学习开发实践需要更多的技术债,因此需要比其他实践更多的未来维护。特定于机器学习的发展债风险因素是多种多样的。它们包括无数的概率变量、数据依赖、递归反馈循环、管道流程、配置设置,以及加剧机器学习算法性能不可预测性的其他因素。
这些复杂性越多,就越难以进行有效维护所需的根源分析。
你无法完全自动化地解决维护负担。在任何情况下,倾向于机器学习模型都需要仔细检查、批判性思维和手工工作,而这些只有受过高度训练的数据科学家才能提供。


星标我,每天多一点智慧