推荐文章 https://blog.csdn.net/bingdianone/article/details/84134868
大数据中的sql之前使用范围最广的是hadoop体系的中的hive sql
hive sql 原理是将sql转换为MapReduce任务,所有效率不高,后面做了改进可以运行在spark(hive on spark),tez(hive on tez)上。 hive on spark是shark(2014年已经停止更新,了解即可)的一个分支,另外一个分支就是大名鼎鼎的Spark SQL
HDFS之所以称为大数据的基石,是因为当前主流的sql框架(Spark,HIVE,Impala,Presto,Drill)都是基于它构建的
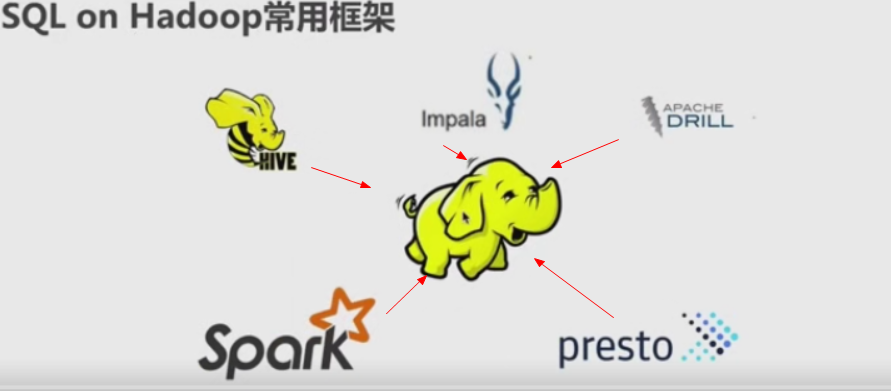
hive 提供metastore 元数据管理; 如果spark或者Impala使用相同的元数据表可以共用,就很容易平滑过渡。
--------------------------------------------------Spark SQL
http://spark.apache.org/sql/
Spark SQL is Apache Spark's module for working with structured data. Spark SQL是spark中处理结构化数据的模块
1)综合,完整的
除了sql外,通过DataFrame API能直接使用java,scala,python和R等语言

2) 统一的数据访问接口

3)Hive集成

4)标准连接支持

spark sql的设计目标:写更少的代码,读更少的数据,让框架去完成艰难复杂的工作
这样小白也能处理复杂的业务场景,而不必担心sql写得不好导致效率太低
小结:
1)Spark SQL的应用并不局限于SQL;
2)访问hive、json、parquet等文件的数据;
3)SQL只是Spark SQL的一个功能而已;===> Spark SQL这个名字起的并不恰当
4)Spark SQL提供了SQL的api、DataFrame和Dataset的API;
----------------------- Spark SQL 架构
sql框架(包括hive,presot等)都差多:sql--> 解析-->执行 ,必然涉及到查询优化器+执行器
spark sql的查询优化器 Catalyst架构如下:
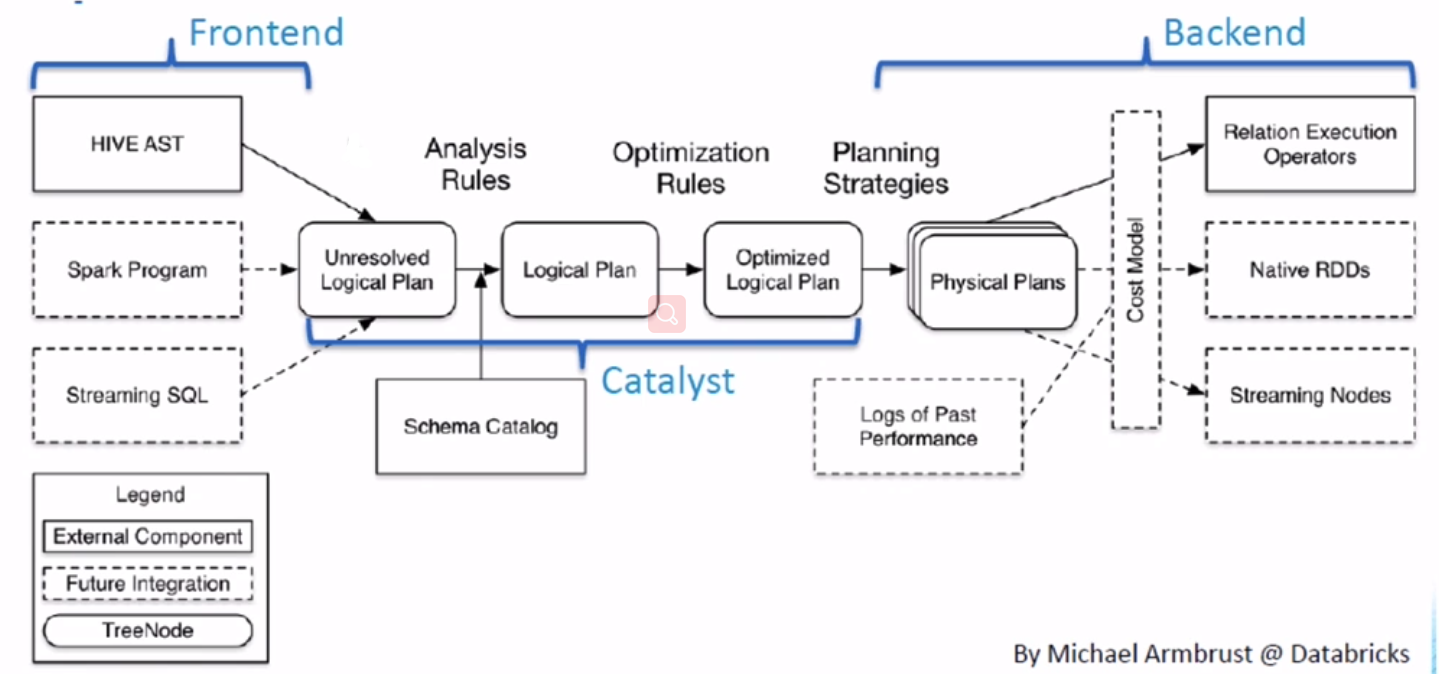
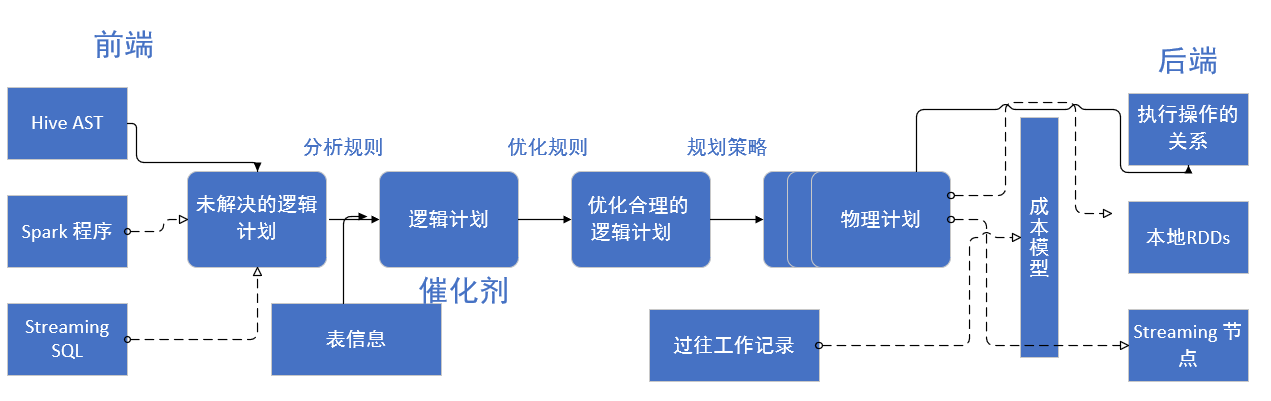
查询优化器 Catalyst是由Scala编写,所以有很强的扩展性; 传统的DB将查询转换为Physical Plans(物理查询计划)后就开始执行查询,但spark sql还会将其转换了DAG(有向无环图)再执行。
Spark SQL的执行引擎就是Spark,始终记得它是在分布式环境中执行。
