推荐文章
https://blog.csdn.net/bingdianone/article/details/84105561#Spark_1
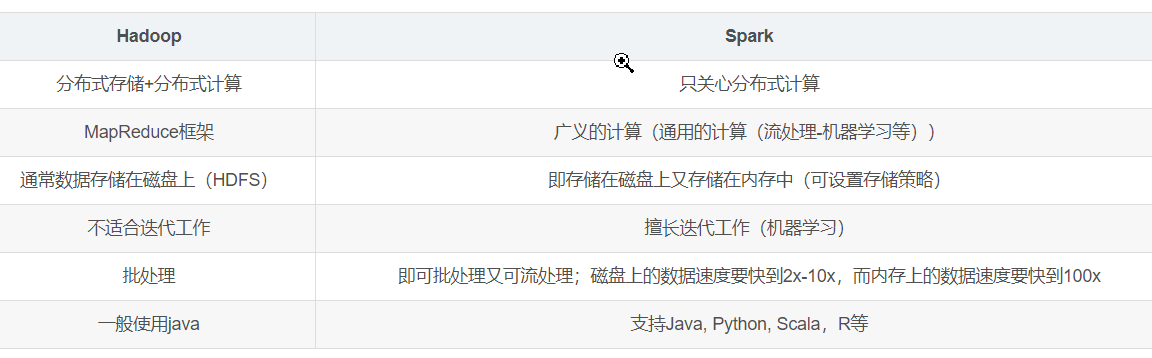
hadoop的生态圈
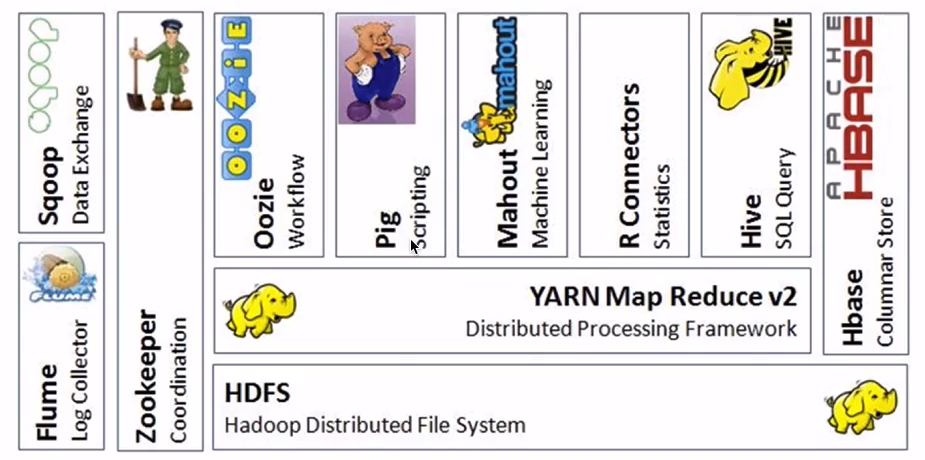
Hive构建在HDFS上, 原理是将sql转mapreduce
Mahout,R语言机器学习; Pig 类似Hive 讲pig语言转 MapReduce
Oozie工作流引擎,类似OA请假流程
Zookeeper分布式协调引擎,挂了重启
Flume日志收集引擎
Sqoop ETL工具, 关系数据库数据抽到Haoop,Hadoop结果表抽到
Hbase 列存储数据库 row key
Spark生态圈(伯克利数据分析栈) https://yq.aliyun.com/articles/371357
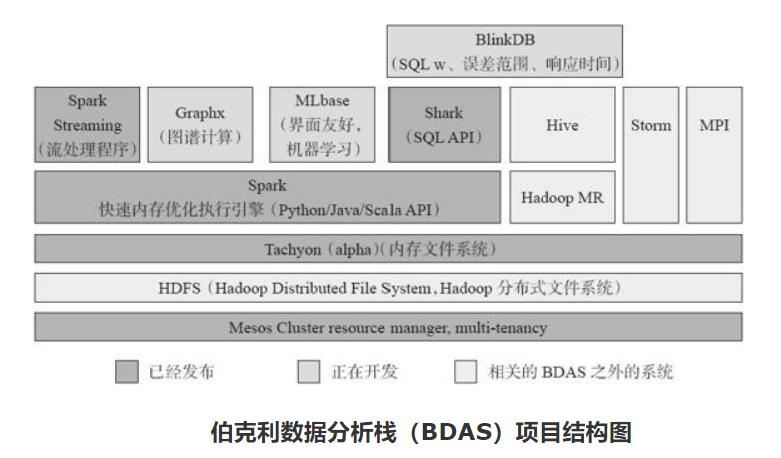
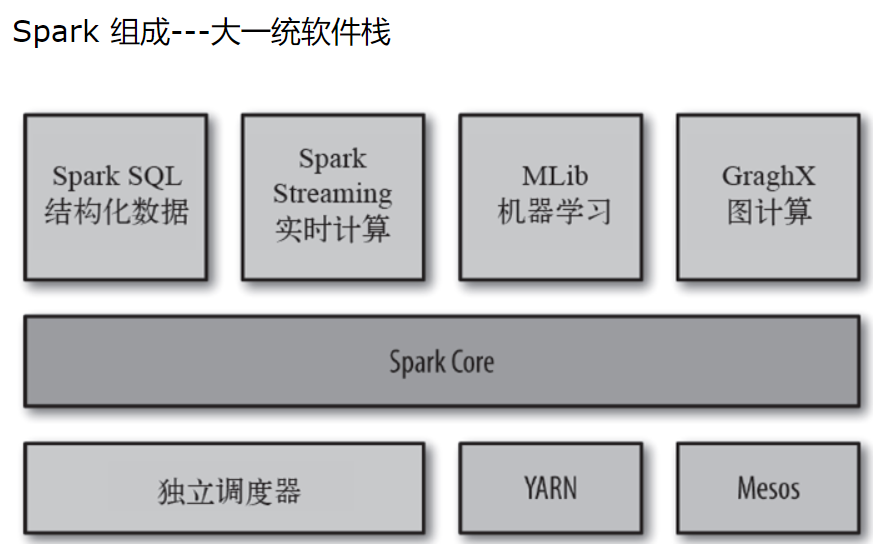
Spark和Hadoop是两个相互补充的生态圈,各自有自己的优缺点, 两者相互配合才是合理的解决方案
要点:
http://spark.apache.org/
● 速度快: 基于内存;DAG执行引擎; 作业线程模型,hadoop是进程模型
● 容易上手,Hadoop里只有map和reduce,而Spark有80+个操作; 像书写单机程序一样书写分布式程序
● 通用的, 一站式解决多个不同业务场景:sql,流式处理,机器学习等。 通过External Data Source可以实现没有ETL的前提下跨平台进行数据分析
● 能运行在多种平台 包括hadoop,可以访问HDFS,HBASE等数据。 大大减少了多个框架带来的学习成本
Spark安装配置
为了更好的进行小版本控制,选择编译源码的方式进行安装
spark 老版本下载 https://archive.apache.org/dist/spark/
编译文档 http://spark.apache.org/docs/latest/building-spark.html#building-apache-spark
下载源码后执行
./dev/make-distribution.sh --name 2.6.0-cdh5.7.0 --tgz -Pyarn -Phadoop-2.6 -Phive -Phive-thriftserver -Dhadoop.version=2.6.0-cdh5.7.0
编译后得到xx.tgz的包,解压,配置环境变量

三种提交模式
1)本地模式
Spark不一定非要跑在hadoop集群,可以在本地,起多个线程的方式来指定。将Spark应用以多线程的方式直接运行在本地,一般都是为了方便调试,本地模式分三类
· local:只启动一个executor
· local[k]:启动k个executor
2)standalone模式
分布式部署集群, 自带完整的服务,资源管理和任务监控是Spark自己监控,这个模式也是其他模式的基础,
3)Spark on yarn模式
分布式部署集群,资源和任务监控交给yarn管理,但是目前仅支持粗粒度资源分配方式,包含cluster和client运行模式,cluster适合生产,driver运行在集群子节点,具有容错功能,client适合调试,dirver运行在客户端
-------------local 模式(在一台机器上运行,可以指定线程数)
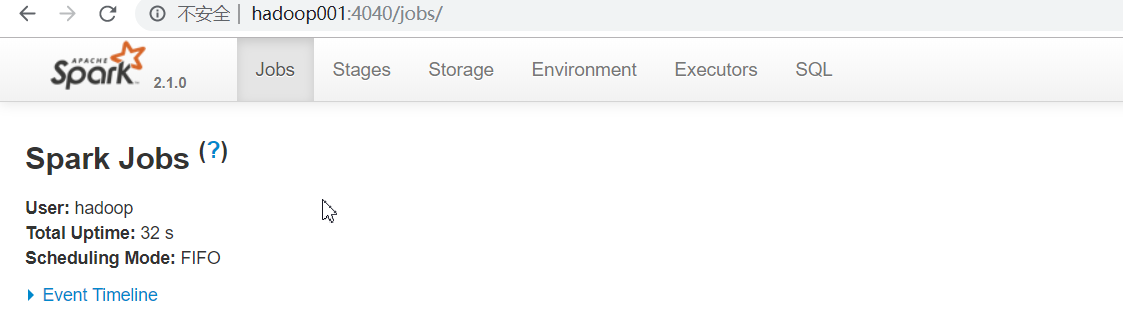
进入bin目录启动spark :
spark-shell --master local[2]
local[2] 大于1多线程 启动命令指导 http://spark.apache.org/docs/2.1.0/programming-guide.html#using-the-shell

Web 页面 http://hadoop001:4040/jobs/
--------------Spark Standalone模式 环境配置
和Hadoop和YARN的Standalone模式一样:1 master+ n worker
进入conf目录,将spark-env.sh.template另存为spark-env.sh
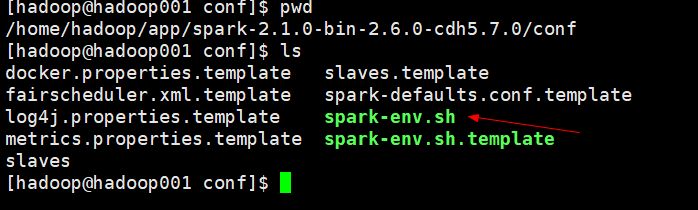
在spark-env.sh 添加
SPARK_MASTER_HOST=hadoop001
SPARK_WORKER_CORES=2
SPARK_DAEMON_MEMORY=2g
SPARK_WORKER_INSTANCES=1
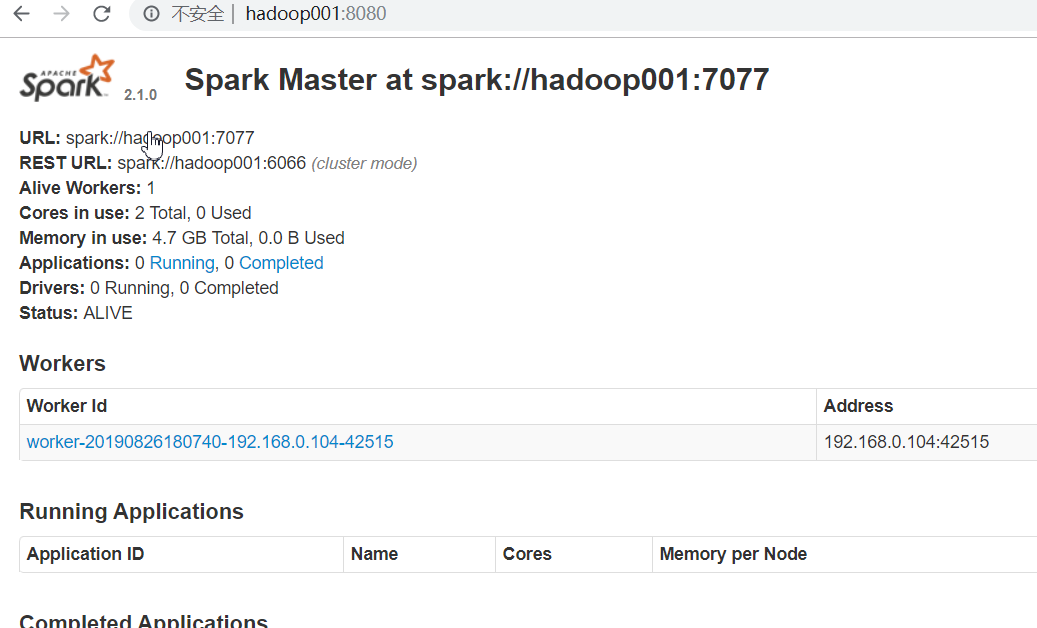
standalone模式启动

访问 http://hadoop001:8080/ 和local模式访问的地址不一样
---------- 多节点配置
和hadoop的slaves文件类似

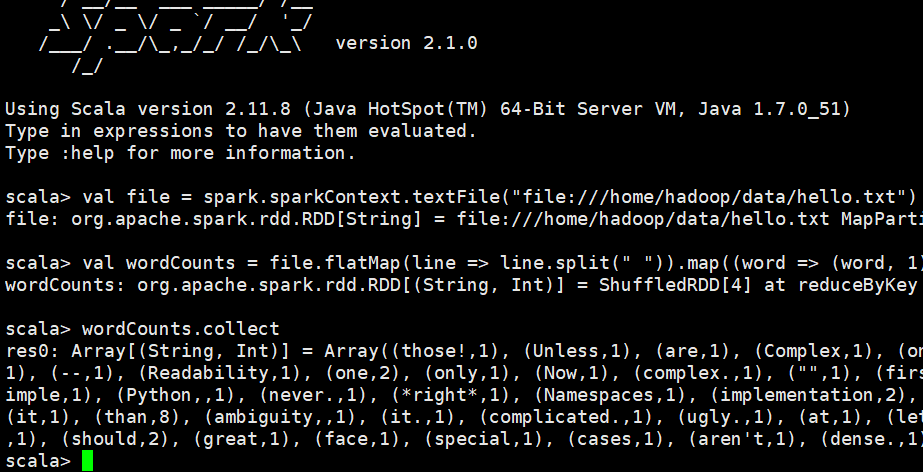
演示wordcount,在local模式的命令行执行
val file = spark.sparkContext.textFile("file:///home/hadoop/data/hello.txt")
val wordCounts = file.flatMap(line => line.split(" ")).map((word => (word, 1))).reduceByKey(_+_)
wordCounts.collect
结果