https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/YARN.html
YARN资源调度管理平台...对于那些上来就讲一堆理论的,理论+实践才是硬道理;想了解理论知识的可以去研究官方文档
![6G}2MD24}X8LFLRD2J]C]GW.jpg](https://ask.hellobi.com/uploads/article/20190824/ceb0652ee160f5b68b42b2f40afbf4e8.jpg)
1. 配置YARN
安装指导 https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html
进入: /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop 按官网添加

●mapred-site.xml
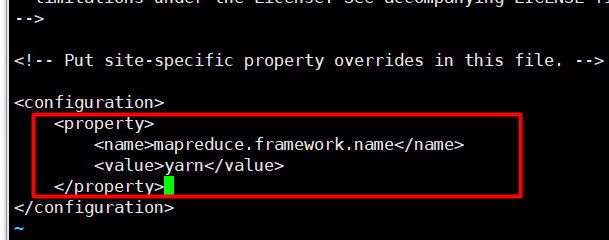
● yarn-site.xml
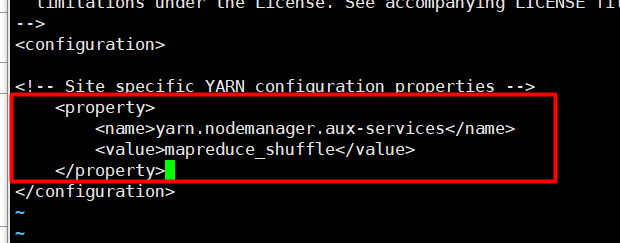
-- 启动/停止 ./stop-yarn.sh

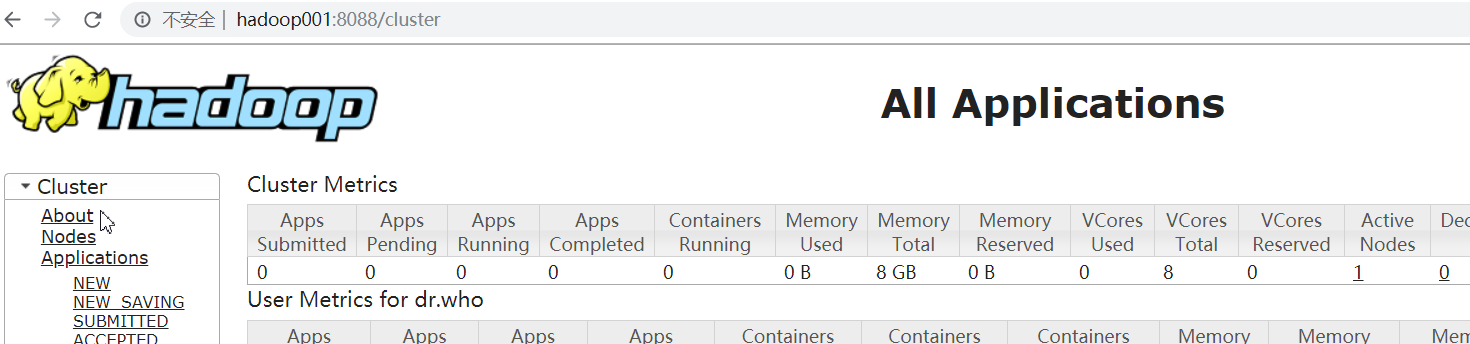
查看:
2. 演示
演示“word count” 计算词频这个例子就像程序开发里的“hello world”;大家要时刻记得我们是分布式大数据平台上完成的word count。
HDFS上建文件夹,放文件,查看
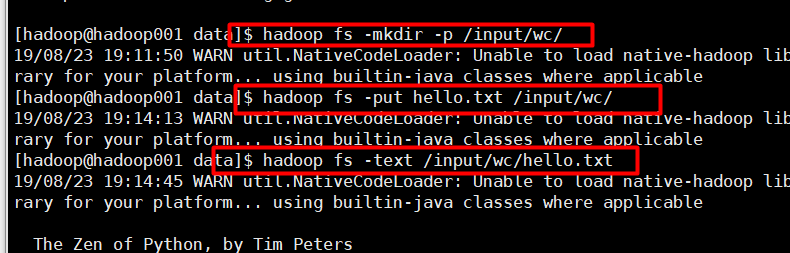
HDFS上查看
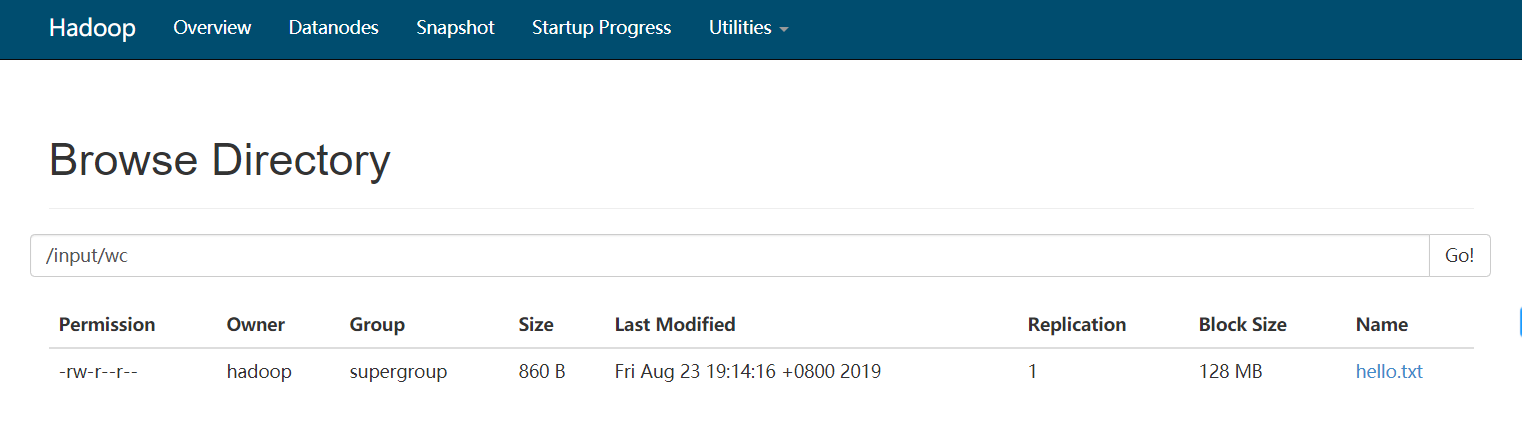
官方提供的打包好的MapReduce 应用,打开源码可以发现这个应用的代码量大,复杂度高(MapReduce只提供了map和reduce两个组件),学习成本太高尤其是我们这些之前做数据开发,报表开发的。 而且因为是磁盘上计算,速度....这些隐患都讲在Spark上解决,后面再和大家分享
运行及查看结果:
#调用脚本
hadoop jar /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar wordcount /input/wc/hello.txt /out/wc/
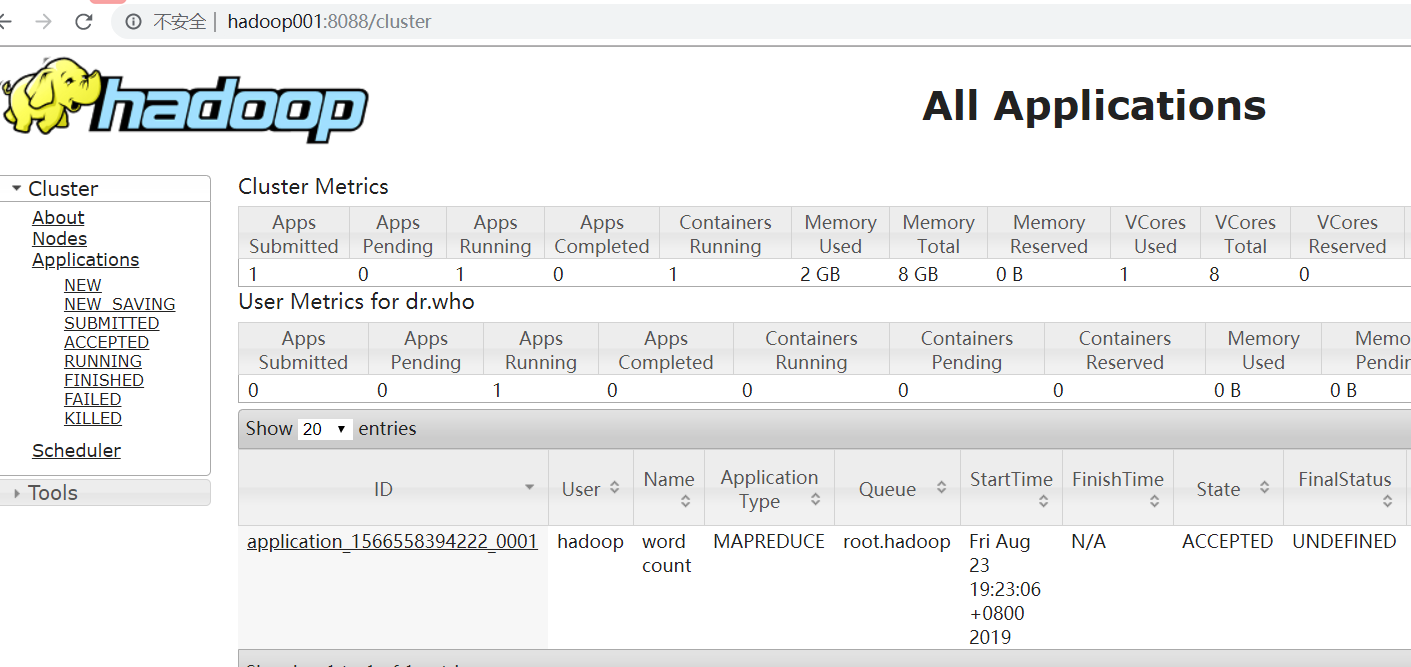
运行时在yarn可以看到有job在执行
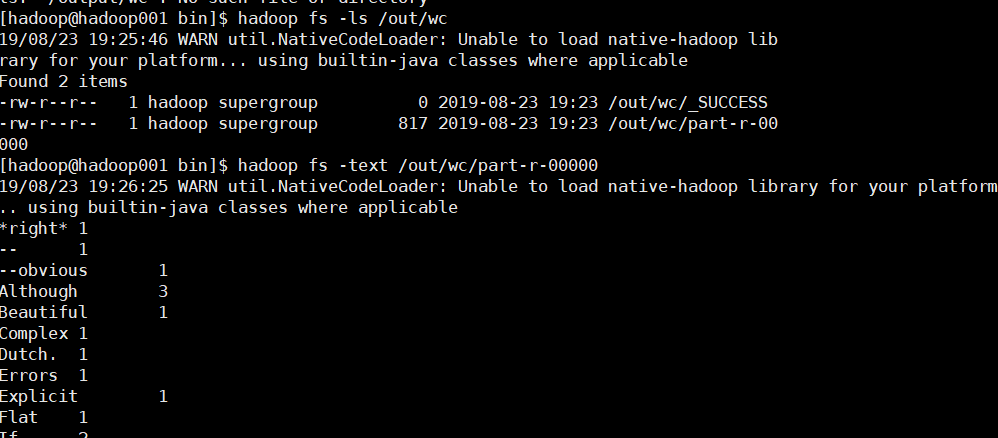
上面的脚本引用了“hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar”是一个打包好的MapReduce应用,源码在
https://hadoop.apache.org/docs/stable/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapReduceTutorial.html#Example:_WordCount_v1.0
可以看到还是比较繁琐。
至此hadoop的核心三大件: HDFS, MapReduce和YARN就都已经安装验证完成;
