本系列文包含HDFS,YARN,MapReduce,HIVE,Spark的安装和使用,不出意外的话每周更新一篇;配置都是基于官方文档,所以大家多阅读理解官网 好处多多; 单机环境很适合初学者开发学习。环境是CentOS7 ;hadoop-2.6.0-cdh5.7.0.tar.gz ; jdk-7u51-linux-x64.tar.gz
https://hadoop.apache.org/
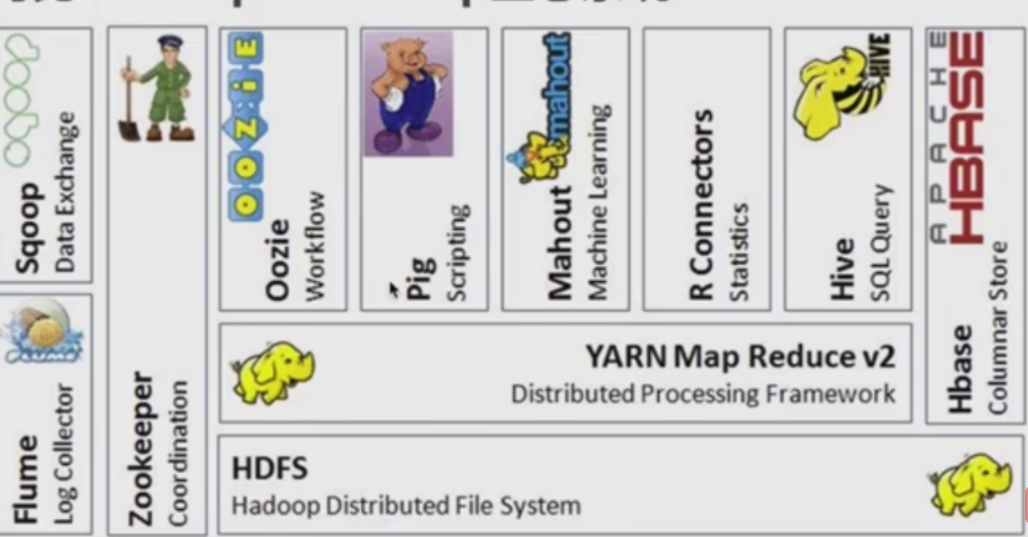
Hadoop三大核心件: HDFS,YARN和MapReduce

简单的说: HDFS让企业能可靠,廉价的,存储海量数据; MapReduce 以较低的门槛(分布式计算那一块封装了)对大数据进行计算; YARN 统一的资源(应用需要内存,cpu等)调度,维护大数据平台的必须;
其他组件(Spark作为和Hadoop互补的生态系统,底层也要依赖HDFS做存储)都是围绕着这个三大件展开
官方安装指导
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html#Required_Software
1. 准备安装
1)新建用户及目录
useradd -m hadoop
passwd hadoop
#用hadoop用户创建相关目录
#software 安装文件目录, app 解压后的目录,data 数据文件夹,source 源代码文件夹,
# shell 脚本文件夹
mkdir software
...
2) java环境,参考hadoop官网,注意版本要求
tar -zxvf jdk-7u51-linux-x64.tar.gz -C ~/app/
#配置java环境
vi ~/.bash_profile
#添加以下内容
# java 1.7 path
export JAVA_HOME=/home/hadoop/app/jdk1.7.0_51
export PATH=$JAVA_HOME/bin:$PATH
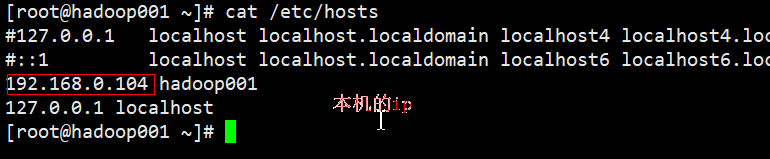
3)机器名称及hosts文件
vi /etc/hostname
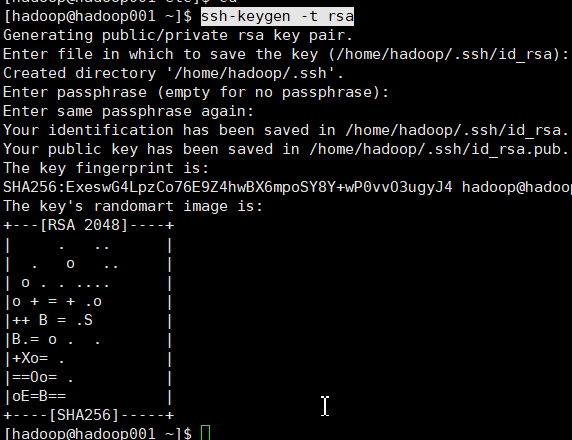
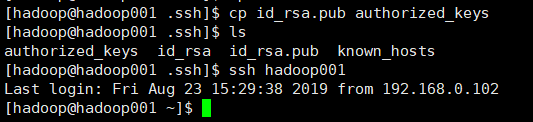
4)免密登录
ssh-keygen -t rsa
一直回车就行
拷贝重命名,并测试
2. 安装HDFS
准确的描述是配置HDFS, 因为HDFS,MapReduce和YARN都在HADOOP的安装包里,经过配置就能使用
官方指导
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html#Configuration
1) 下载并配置环境
#解压安装包到app目录
tar -zxvf hadoop-2.6.0-cdh5.7.0.tar.gz -C ~/app/
进入解压后的文件夹 /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop
2) 修改配置文件
● hadoop-env.sh hadoop 的运行环境配置

修改:

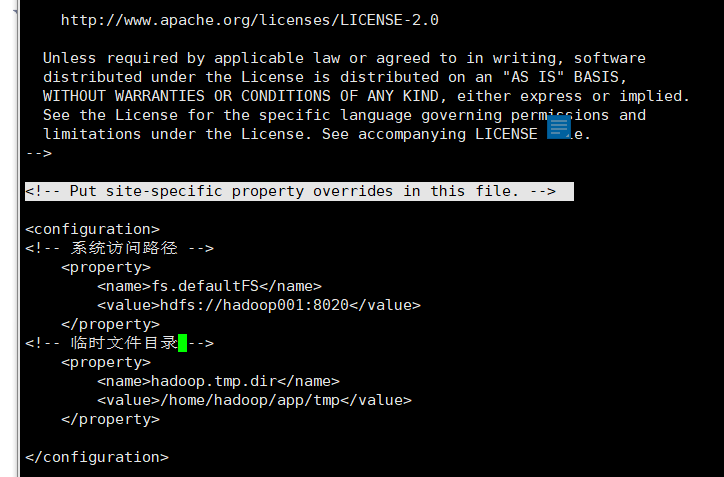
● core-site.xml
hadoop2.x 9000改为8020
要创建个hadoop系统临时文件夹,避免系统每次重启自动清空
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/core-default.xml
最终
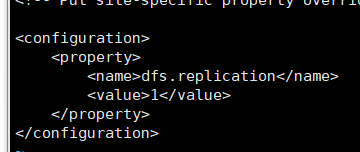
● hdfs-site.xml 文件系统的副本系数
由于是单机环境,设置为1
3. 启动HDFS
格式化只在第一次启动时执行;bin 下是客户端相关的脚本
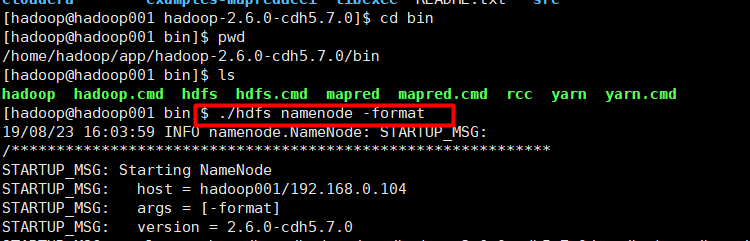
启动后,发现已经有些文件生成了
sbin是服务端相关的,启动hdfs
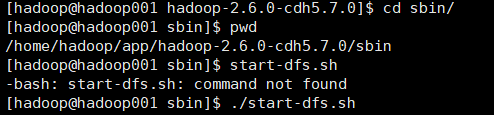
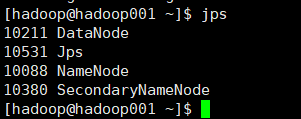
JPS查看进程
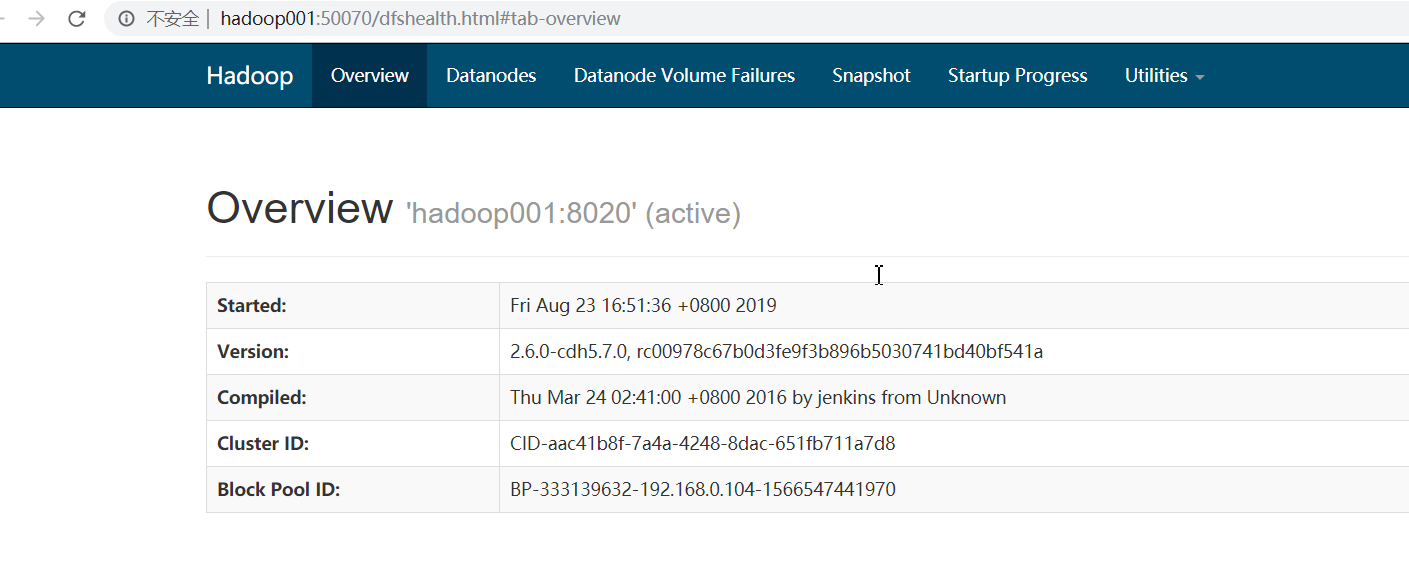
浏览器地址查看,记得修改自己机器的hosts文件
http://hadoop001:50070/dfshealth.html#tab-overview
停止

4. HDFS 脚本
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HDFSCommands.html
基本命令 ls, mkdir, put,get,rm等linux脚本几乎一样;需要配置hadoop的环境变量
总结:
HDFS可以说是大数据生态的基石
优点:
可以用很多廉价机器扩展 成本低;
高容错; 批处理适合大数据情景;
缺点(有缺点是很正常的,没有一种技术能解决全部的场景,正是有这些缺点,所以才有Spark体系的诞生):
对数据时效要求高的报表合适,比如近实时报表;不适合小文件存储(文件不管大小都要分块,分布式存储;集群上的小文件都要定期合并成大文件)
