一.环境准备
jdk、hadoop软件包、eclipse(linux版)
二.安装java
JDK、Tomcat、Oracle
CentOS-6.3安装配置JDK-7 http://www.flybi.net/blog/liangyong/12
CentOS-6.3安装配置Tomcat7.0 http://www.flybi.net/blog/liangyong/2
CentOS-6.3安装配置Oracle11g R2 http://www.flybi.net/blog/liangyong/34
三.安装hadoop(单机分布式)
3.1、创建hadoop用户
为hadoop创建一个专门的用户,具体如下:
groupadd hadoopGroup //创建hadoop用户组
useradd -g hadoopGroup hadoop //新增用户hadoop并将其加入hadoopGroup群组
passwd hadoop //建立hadoop用户的新密码,密码也是hadoop
3.2安装hadoop
用ftp工具将hadoop安装包上传到linux系统中,解压
tar -zxvf hadoop-1.2.1.tar.gz
3.3配置ssh
Hadoop需要通过SSH(安全外壳协议,可以保护共享访问的安全性)来启动Slave列表中各台主机的守护进程。但是由于SSH需要用户密码登陆,所以为了在系统运行时,节点之间免密码登录和访问,就需要把SSH配置免密码方式。具体如下:
ssh-keygen -t rsa //生成密钥对,ras加密
一直按enter,就会按照默认的选项将生成的密钥对保存到.ssh/id_rsa
cd .ssh/
cp id_rsa.pub authorized_keys //进入.ssh,把id_rsa.pub文件追加到授权(authorized_keys)里面
ssh localhost //测试无密码登录本机
3.4配置hadoop环境
切换到hadoop的安装路径找到conf/hadoop-env.sh文件,vi编辑,在文件最后添加如下语句:
同时将hadoop安装目录的bin目录配置到系统path变量中,不然如果无法使用hadoop命令(当然也可以每次都到hadoop安装文件夹下的bin里面去执行./hadoop)
Hadoop-1.2.1的配置文件主要有三个,从名字上很容易辨认和理解:conf/core-site.xml(全局配置文件)、conf/hdfs-site.xml(HDFS配置文件)和conf/mapred-site.xml(MapReduce的配置文件)。下面是我的配置,name都是固定的,也很容易理解。value注意根据自己的路径来配
conf/core-site.xml
conf/mapred-site.xml
hdfs-site.xml
3.5格式化HDFS文件系统
修改完上述文件之后,进入hadoop安装目录
在首次安装和使用Hadoop之前,需要格式化分布式文件系统HDFS,所以执行如下命令:
3.6启动hadoop环境
启动守护进程
成功后,至少将在本机上启动5个新进程:NameNode、DataNode、JobTracke、TaskTracker、SecondaryNameNode
查看hadoop启动情况
Jps
NameNode
oc4j.jar
JobTracker
Bootstrap
TaskTracker
DataNode
SecondaryNameNode
如果现实类似于上述的信息,则表示Hadoop已经正常启动了,恭喜你!既然Hadoop安装好了,那就该用用了。
四、Hadoop下eclipse开发环境准备
4.1、安装eclipse,并编译插件
eclipse插件编译及使用详见 http://www.cnblogs.com/alex-blog/p/3160619.html
4.2配置Map/Reduce Locations
重启eclipse,配置hadoop installation directory,如图
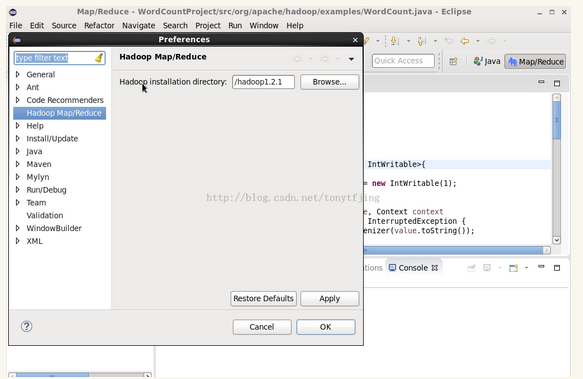
如果安装插件成功,打开Window-->Preferens,你会发现Hadoop Map/Reduce选项,在这个选项里配置Hadoop installation directory。进入Map/Reduce视角,如下图,
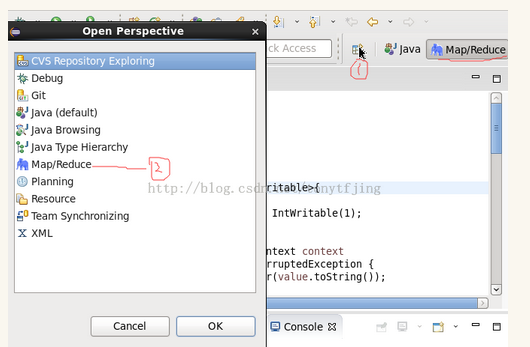
新建location

配置如下,

这里面的Host、Port分别是我前面在core-site.xml、mapred-site.xml中配置的地址及端口。配置完后退出。一层层打开DFS Locations,如果能显示文件夹(1)说明配置正确,如果显示"拒绝连接",请检查配置。
4.3第一个Map/Reduce Project
新建一个Map/Reduce Project项目,将example里的WordCount.java复制到新建的项目下面。先编写个数据输入文件,如下:

通过hadoop的命令在HDFS上创建/tmp/workcount目录,命令如下:
通过copyFromLocal命令把新建的word.txt复制到HDFS上,命令如下:
这个时候我们回到eclipse里面,在Map/Reduce Locations上reconnect看看,发现多出来了文件,如下所示,

4.4运行第一个Map/Reduce Project
在WordCount.java,右键-->Run As-->Run Configurations ,配置如下,

两个配置参数很容易理解,就是输入文件和输出文件。点击Run,运行程序,等运行结束后,查看运行结果,同样在Map/Reduce Locations上reconnect看看(也可以用命令hadoop fs -ls /tmp/wordcount/out)会发现又多出一个文件夹,下面含有两个文件。
使用命令查看part-r-00000文件,hadoop fs -cat /tmp/wordcount/out/part-r-00000可以查看运行结果。

好了,现在搭建好了基本的开发环境了,可以开发!

