【摘要】
介绍了如何使用集算器的组表进一步优化 JOIN 运算的方法。SPL 组表进一步优化 JOIN 性能
上一篇《优化 Join 运算的系列方法》介绍了如何使用集算器优化JOIN性能,其中数据存储使用的是集文件。如果想进一步提升性能,可以使用组表代替集文件。
1 组表特点
相对于集文件,组表有不少新特点:列存、分段、有序。充分利用好这些特点可以有效提升查询性能、节省存储空间。
2 组表使用
建立组表的操作可以参考相关的教程文档,下面看几个对组表访问的例子。
2.1 列式访问
组表通过游标来查询数据,下面以订单表和用户表为例,查询每一笔订单的用户名称、用户级别和下单时间。
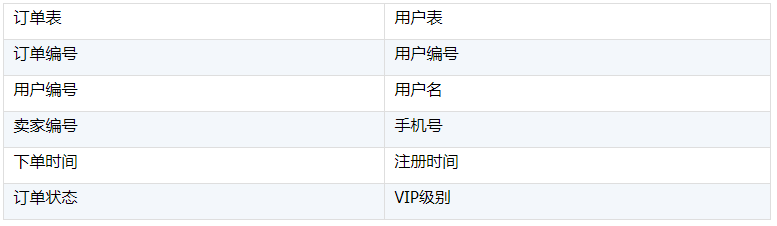
A1,创建订单表组表对象;
A2,创建用户表组表对象;
A3,创建订单表游标,只取出订单编号、用户编号、下单时间字段;
A4,得到用户表数据,只取出用户编号、用户名、VIP级别字段;
A5,关联,在A3订单表的用户编号字段上建立指向用户信息表记录的指针;
A6,外键指针化之后,将外键表字段用户名、VIP级别作为属性用户名、用户级别使用。
这里的计算过程就是“外键指针化”,这与使用集文件时无异,但是取出的数据并非整个表的数据,而是按需取出。取出的数据少了,性能自然就提升了,这里就利用到了组表列式存储的特点。经过测试,使用组表执行这个计算所使用的时间,能够比使用集文件少1/4。
2.2 条件过滤
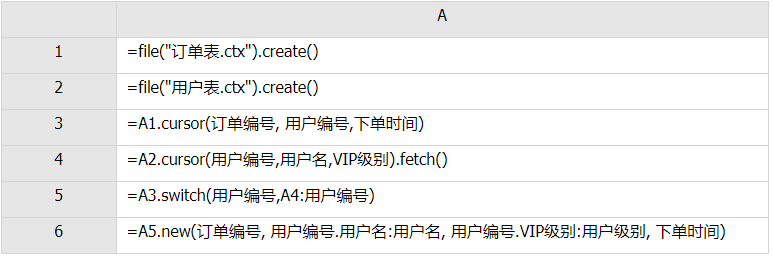
组表游标还可以使用查询条件,例如在上面的例子中增加一个查询条件,把查询结果限定为2015年以来的订单记录:
在上面代码的基础上,为A3加一个查询条件就实现了。组表里的数据是对维字段有序的,可以做到快速查询。不论是按照范围查询,还是等值查询,组表都做了最大程度优化。虽然集文件的游标也有条件查询的功能,但是在性能上比组表差很多。条件查询的结果越少,这个差距也就越明显,甚至可能会相差上百倍。
需要注意的是,这里可以优化的前提是条件字段必须是维字段。对于订单表,因为订单编号唯一,而且订单编号和下单时间都是递增的,所以可以把这两个字段设置为维字段。
2.3 有序归并
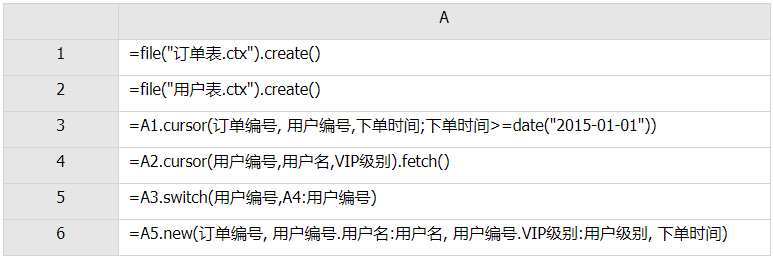
如果两个组表对于关联键都已经是有序的了,那么可以直接使用归并算法来处理关联。来看一个例子:
把两个组表按照订单编号字段进行关联,从而汇总每个卖家的销售额,当数据量不大的时候可以这样查询:

当数据很大无法导入内存时,则可以使用游标方式实现:

当关联字段不是有序时,就需要事先进行排序,这个处理跟上一篇对集文件的数据准备是一样的。
对比测试的结果,使用组表执行这个计算所使用的时间,仅仅是使用集文件所用时间的1/3。
2.4 并行计算
组表对数据分段存储的特点,能够使并行计算非常方便。来看一个例子:计算卖家销售总额:

A1得到订单表的多路游标,这里的路数是8,是根据实际情况选定的;
A2得到订单明细表的多路游标,这个游标是根据A1同步分段的;
A3使用joinx进行归并,得到游标;
A4对多路游标进行分组汇总。
两个组表进行同步分段很方便,而集文件的同步分段就要麻烦很多。
3 综合案例
上一篇使用过一个综合案例,外键表、同维表、主子表这几种关联类型一起出现,接下来看看如何使用组表实现这个计算。
3.1 表结构和查询目标
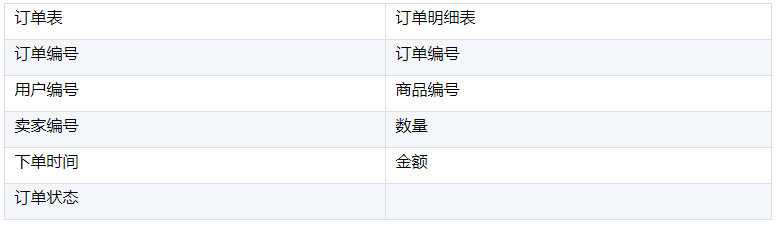
某电商平台中和订单编号这个字段相关的有6个表,主要表结构如下:
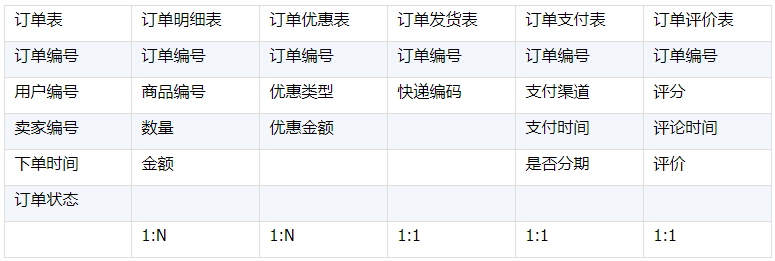
他们都靠订单编号字段进行关联,下面是订单表和另外5个表的对应关系:
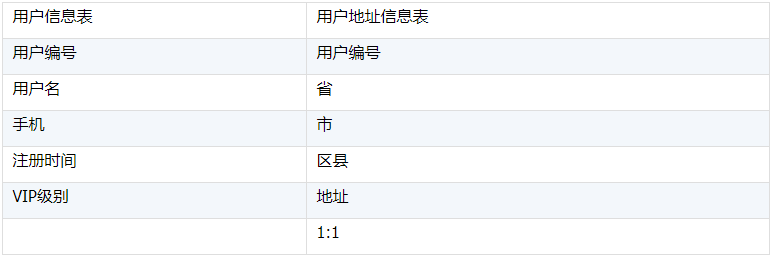
用户表和用户地址表,这两个表是按照用户编号字段1对1的关系,这是同维表情况。
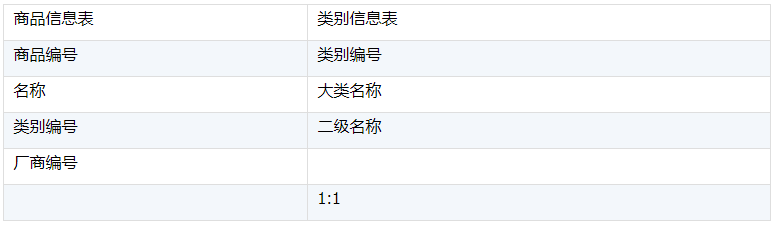
商品信息表和类别信息表是通过类别编码进行关联,这是外键表的情况。
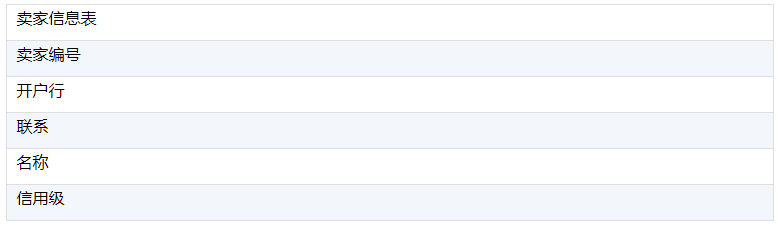
最后还有一个卖家信息表。这里一共有11个表,假设要做这样一个查询:现在想知道江浙沪三省的VIP用户在2018年内从5星级卖家那里购买的所有电脑类商品的详情,并且要求只统计那些优惠总金额大于100元、用户评分4分以上的使用邮政配送的订单,而且这些订单不能是分期付款的。
3.2 分析关联类型
计算的步骤跟上一篇几乎一样,首先对这个查询进行拆分,得到以下几个子步骤:
P1=对用户表、用户地址表关联,得到江浙沪三省VIP用户的用户编号,这是同维表情况;
P2=卖家信息表取游标,条件是信用级别=5,得到卖家编码;
P3=对订单优惠表按照订单编号分组,按条件(优惠总金额>=100元)过滤;
P4=订单发货表取游标,条件是快递编码=1(邮政快递编码);
P5=订单支付表取游标,条件是是否分期=false;
P6=订单评价表取游标,条件是评分>=4;
P7=商品信息表和类别信息表用类别编码做外键关联,用条件(大类=电脑)过滤;
P8=订单明细表通过商品编号字段对P7做外键关联;
P9=订单表依次对P1、P2做外键关联;
这时P3、P4、P5、P6、P8、P9这几个子查询都是同维或者主子表的关系,对它们通过订单编码字段做有序归并,就得到了需要查询的结果。
3.3 查询实现
用户信息表很大,但查询目标是VIP级别的用户,符合VIP这个条件的用户并不多,进行过滤后就可以装入内存,所以P1子查询可以全部装入内存;同样,用户地址信息表作为用户信息表的同维表也很大,但属于江浙沪三省的用户并不多,经过过滤后可以全部导入内存。把这两个同维表关联后,然后再完成订单表的关联计算,来看看这个子查询的写法:

A1,得到用户信息表的游标,并按条件过滤;
A2,得到用户地址信息表的游标,并按条件过滤;
A3,对A1、A2按照用户编号字段进行有序归并,返回的结果只取用户编号;
A4,得到订单表的游标,并按条件过滤;
A5,把A4和A3做外键关联;
A6,返回结果只取订单编号、卖家编号和用户编号字段;
A7,返回执行结果;
把这个脚本保存为P9.dfx。
接下来实现商品信息表和类别信息表的关联。类别信息表是商品信息表的外键,这个表很大无法装入内存。但是大类是电脑的类别信息就不多了,所以用大类等于电脑这个条件先过滤一下后就可以装入内存。下面是个子查询,把大类是电脑的所有商品的编码全部导入内存:

A1,得到类别信息表的数据,并按条件过滤后取出;
A2,得到商品信息表游标,并按条件过滤;
A3,把A2的商品编号字段替换为A1的对应记录;
A4,结果只取商品编号字段;
A5,返回执行结果;
这个脚本保存为P7.dfx。
上面是两个子查询的处理,整个查询的实现是这样:
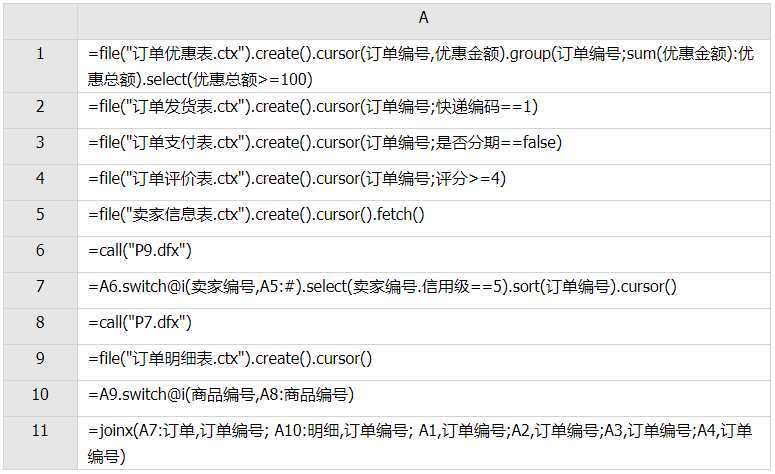
A1,得到订单优惠表游标;
A2,得到订单发货表游标;
A3,得到订单支付表游标;
A4,得到订单评价表游标;
A5,得到卖家信息表数据(这里认为卖家信息表的数据可以导入内存);
A6,调用P9.dfx;
A7,把A6的结果的卖家编号替换成卖家信息表里的对应记录,按条件(信用级=5)进行过滤,并排序;
A8,调用P7.dfx,得到大类是电脑的所有商品的编码;
A9,得到订单明细表游标;
A10,把订单明细表的商品编号替换成A8结果里的对应记录;
A11,对A7、A10、A1、A2、A3、A4进行有序归并;
3.4 查询技巧
技巧一:使用组表游标时只取出用到的字段,用不到的一律不取出。这样的做的好处是可以充分利用组表的列式存储特点,减少从硬盘读取的数据量。
技巧二:对于维字段的查询条件,尽量使用组表游标来完成条件过滤。组表对维字段的过滤效率很高,这一点对性能的提升往往会起到关键作用。
总结
组表对性能的提升,很多时候都是无形的,即使是一个最简单的查询,使用组表也要比集文件要快很多,而且不仅提高了性能,使用起来也很方便。
