


文章发布于公号【数智物语】 (ID:decision_engine),关注公号不错过每一篇干货。
作者 | 梁云1991
转载自Python与算法之美(ID:Python_Ai_Road)
01Spark优势特点
作为大数据计算框架 MapReduce 的继任者,Spark 具备以下优势特性。
01高效性
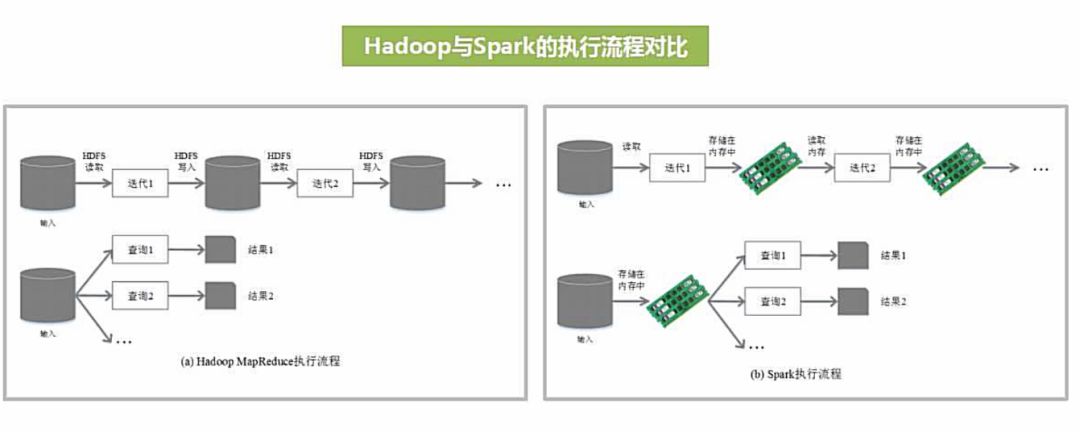
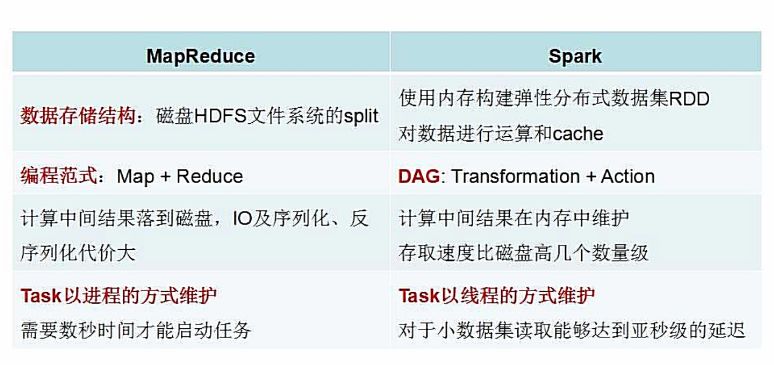
不同于 MapReduce 将中间计算结果放入磁盘中,Spark 采用内存存储中间计算结果,减少了迭代运算的磁盘 IO,并通过并行计算 DAG 图的优化,减少了不同任务之间的依赖,降低了延迟等待时间。内存计算下,Spark 比 MapReduce 快 100 倍。
02易用性
不同于 MapReduce 仅支持 Map 和 Reduce 两种编程算子,Spark 提供了超过 80 种不同的 Transformation 和 Action 算子,如map, reduce, filter, groupByKey, sortByKey, foreach 等,并且采用函数式编程风格,实现相同的功能需要的代码量极大缩小。
03通用性
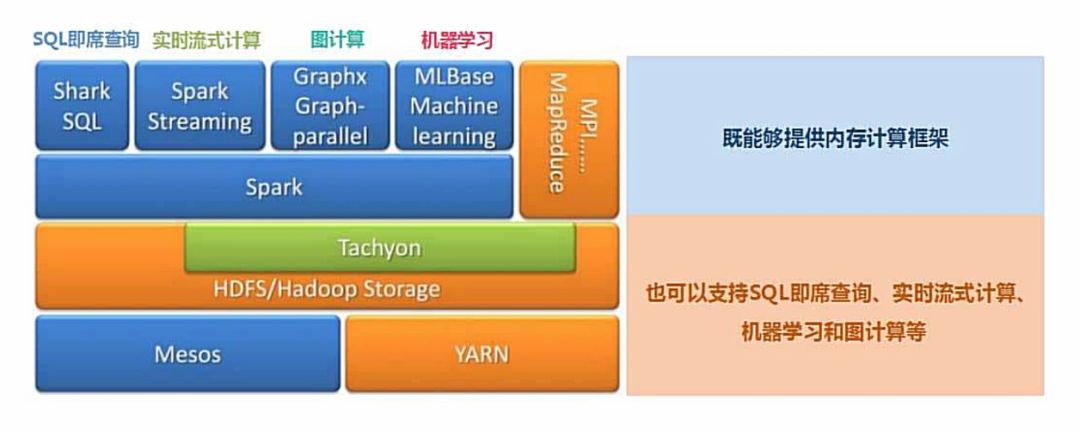
Spark 提供了统一的解决方案。Spark 可以用于批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)。
这些不同类型的处理都可以在同一个应用中无缝使用。这对于企业应用来说,就可使用一个平台来进行不同的工程实现,减少了人力开发和平台部署成本。
04兼容性
Spark 能够跟很多开源工程兼容使用。如 Spark 可以使用 Hadoop 的 YARN 和 Apache Mesos 作为它的资源管理和调度器,并且 Spark 可以读取多种数据源,如 HDFS、HBase、MySQL 等。
02Spark基本概念
RDD:是弹性分布式数据集(Resilient Distributed Dataset)的简称,是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型。
DAG:是 Directed Acyclic Graph(有向无环图)的简称,反映 RDD 之间的依赖关系。
Driver Program:控制程序,负责为 Application 构建 DAG 图。
Cluster Manager:集群资源管理中心,负责分配计算资源。
Worker Node:工作节点,负责完成具体计算。
Executor:是运行在工作节点(Worker Node)上的一个进程,负责运行 Task,并为应用程序存储数据。
Application:用户编写的 Spark 应用程序,一个 Application 包含多个 Job。
Job:作业,一个 Job 包含多个 RDD 及作用于相应 RDD 上的各种操作。
Stage:阶段,是作业的基本调度单位,一个作业会分为多组任务,每组任务被称为“阶段”。
Task:任务,运行在 Executor 上的工作单元,是 Executor 中的一个线程。
总结:Application 由多个 Job 组成,Job 由多个 Stage 组成,Stage 由多个 Task 组成。Stage 是作业调度的基本单位。
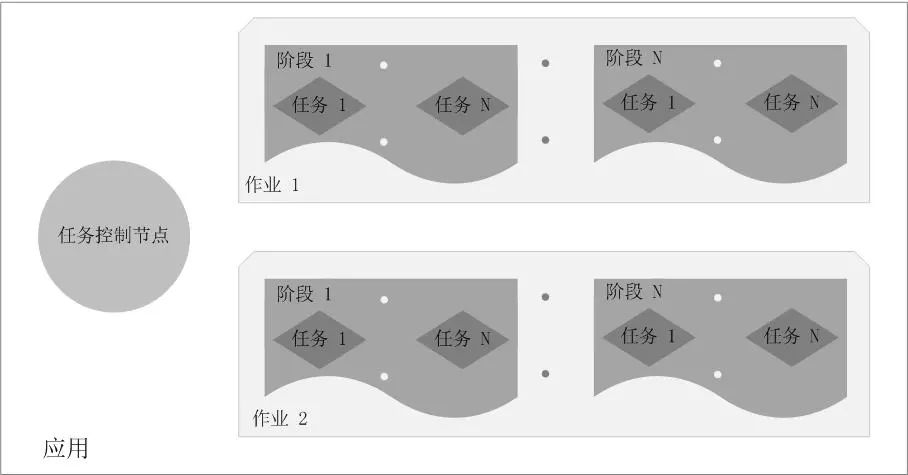
03Spark架构设计
Spark 集群由 Driver, Cluster Manager(Standalone, Yarn 或 Mesos),以及 Worker Node 组成。对于每个 Spark 应用程序,Worker Node 上存在一个 Executor 进程,Executor 进程中包括多个 Task 线程。
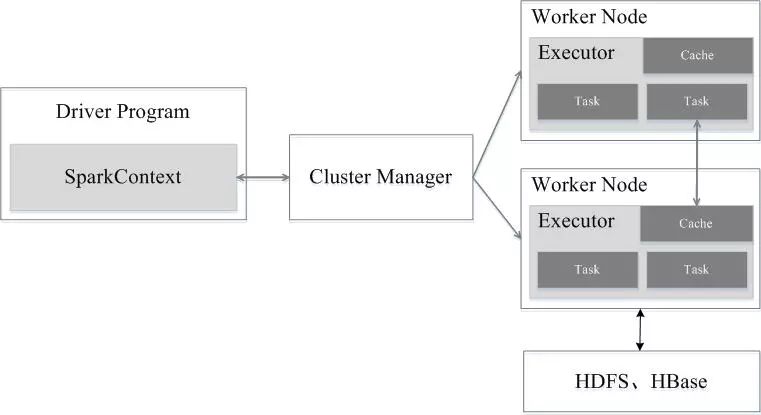
04Spark运行流程
1,Application 首先被 Driver 构建 DAG 图并分解成 Stage。
2,然后 Driver 向 Cluster Manager 申请资源。
3,Cluster Manager 向某些 Work Node 发送征召信号。
4,被征召的 Work Node 启动 Executor 进程响应征召,并向 Driver 申请任务。
5,Driver 分配 Task 给 Work Node。
6,Executor 以 Stage 为单位执行 Task,期间 Driver 进行监控。
7,Driver 收到 Executor 任务完成的信号后向 Cluster Manager 发送注销信号。
8,Cluster Manager 向 Work Node 发送释放资源信号。
9,Work Node 对应 Executor 停止运行。


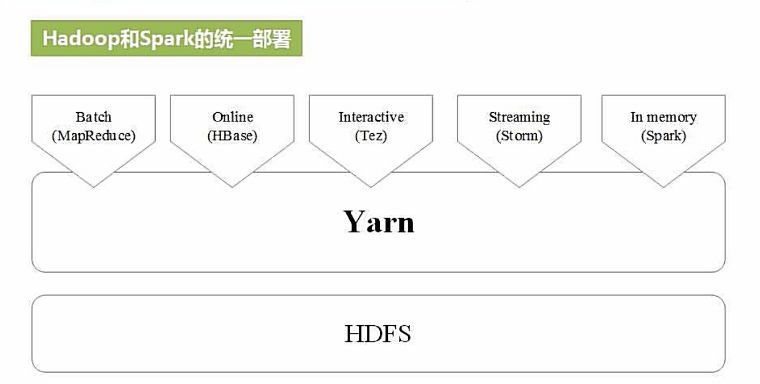
05Spark部署模式
Local:本地运行模式,非分布式。
Standalone:使用 Spark 自带集群管理器,部署后只能运行 Spark 任务。
Yarn:Haoop 集群管理器,部署后可以同时运行 MapReduce,Spark,Storm,Hbase 等各种任务。
Mesos:与 Yarn 最大的不同是 Mesos 的资源分配是二次的,Mesos 负责分配一次,计算框架可以选择接受或者拒绝。
06RDD数据结构
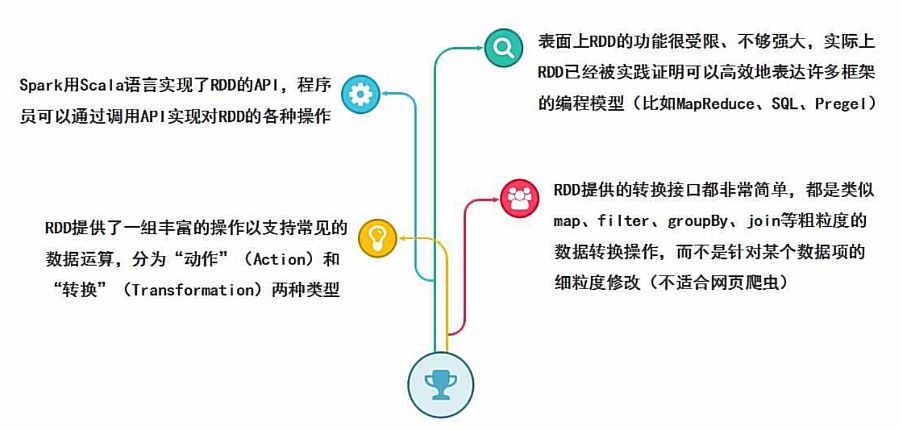
RDD 全称 Resilient Distributed Dataset,弹性分布式数据集,它是记录的只读分区集合,是 Spark 的基本数据结构。
RDD 代表一个不可变、可分区、里面的元素可并行计算的集合。
一般有两种方式可以创建 RDD,第一种是读取文件中的数据生成 RDD,第二种则是通过将内存中的对象并行化得到 RDD。
val rdd = sc.textFile("hdfs://hans/data_warehouse/test/data")
val num = Array(1,2,3,4,5)
val rdd = sc.parallelize(num)
创建 RDD 之后,可以使用各种操作对 RDD 进行编程。
RDD 的操作有两种类型,即 Transformation 操作和 Action 操作。转换操作是从已经存在的 RDD 创建一个新的 RDD,而行动操作是在 RDD 上进行计算后返回结果到 Driver。
Transformation 操作都具有 Lazy 特性,即 Spark 不会立刻进行实际的计算,只会记录执行的轨迹,只有触发 Action 操作的时候,它才会根据 DAG 图真正执行。
操作确定了 RDD 之间的依赖关系。
RDD 之间的依赖关系有两种类型,即窄依赖和宽依赖。窄依赖时,父 RDD 的分区和子 RDD 的分区的关系是一对一或者多对一的关系。而宽依赖时,父 RDD 的分区和子 RDD 的分区是一对多或者多对多的关系。
宽依赖关系相关的操作一般具有 shuffle 过程,即通过一个 Patitioner 函数将父 RDD 中每个分区上 key 不同的记录分发到不同的子 RDD 分区。
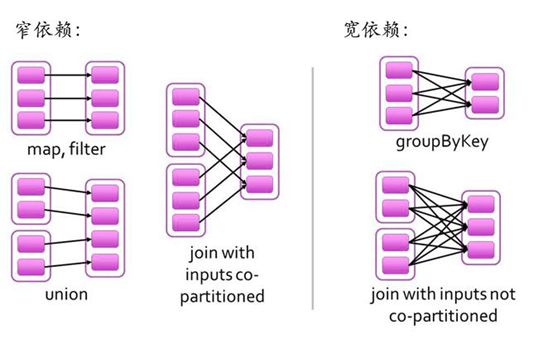
依赖关系确定了 DAG 切分成 Stage 的方式。
切割规则:从后往前,遇到宽依赖就切割 Stage。
RDD 之间的依赖关系形成一个 DAG 有向无环图,DAG 会提交给 DAGScheduler,DAGScheduler 会把 DAG 划分成相互依赖的多个 stage,划分 stage 的依据就是 RDD 之间的宽窄依赖。遇到宽依赖就划分 stage,每个 stage 包含一个或多个 task 任务。然后将这些 task 以 taskSet 的形式提交给 TaskScheduler 运行。

07WordCount范例
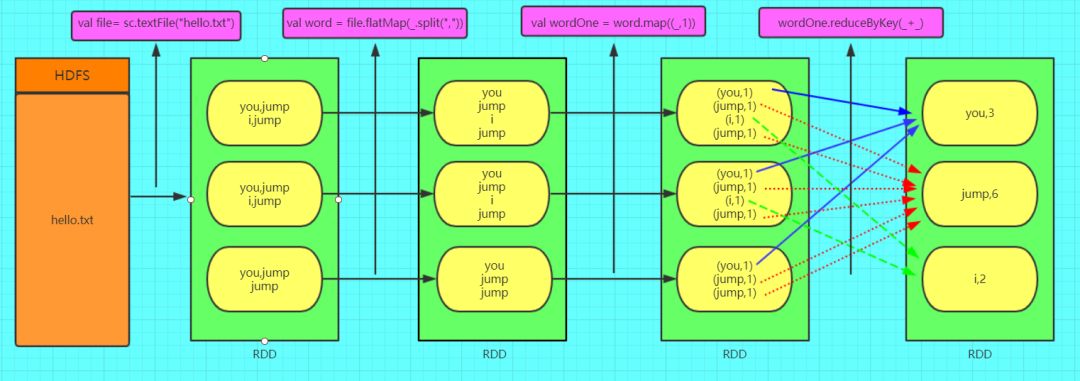
只需要四行代码就可以完成 WordCount 词频统计。
val file = sc.textFile("hello.txt")
val word = file.flatMap(_.split(","))
val wordOne = word.map((_,1))
wordOne.reduceByKey(_+_)


星标我,每天多一点智慧


