————————————————————禁止转载—————————————————————
#作者:面包君
#时间:2016-4-6
#知乎专栏:http://zhuanlan.zhihu.com/dataman
我们在应用到的机器学习中,推荐系统应该是应用到的最为广场的场景了。而在推荐环节算法也是最核心的部分,常用的算法也是无外乎几种,当然如果有好的算法也可以推荐下。之前在推荐系统简介中,我们给出了推荐系统的一般框架。很明显,推荐方法是整个推荐系统中最核心、最关键的部分,很大程度上决定了推荐系统性能的优劣。目前,主要的推荐方法包括:基于内容推荐、协同过滤推荐、基于关联规则推荐和组合推荐。
一、基于内容推荐
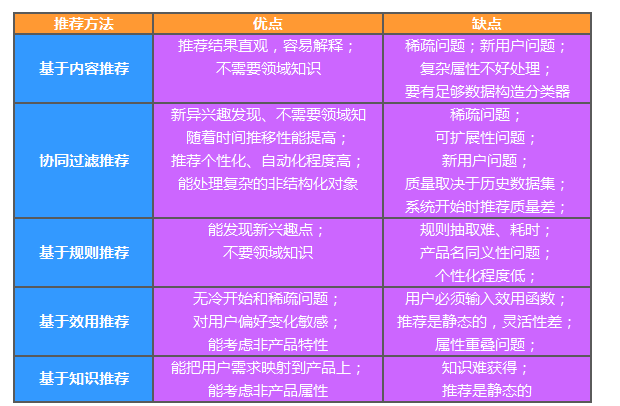
基于内容的推荐(Content-based Recommendation)是信息过滤技术的延续与发展,它是建立在项目的内容信息上作出推荐的,而不需要依据用户对项目的评价意见,更多地需要用机 器学习的方法从关于内容的特征描述的事例中得到用户的兴趣资料。在基于内容的推荐系统中,项目或对象是通过相关的特征的属性来定义,系统基于用户评价对象 的特征,学习用户的兴趣,考察用户资料与待预测项目的相匹配程度。用户的资料模型取决于所用学习方法,常用的有决策树、神经网络和基于向量的表示方法等。 基于内容的用户资料是需要有用户的历史数据,用户资料模型可能随着用户的偏好改变而发生变化。
基于内容的推荐,很大程度上是在进行文本挖掘。web应用提供的内容或者爬取的内容在推给用户之前可以做一些挖掘,比如资讯类的应用,将抓取到的资讯,通过文本分析那一套算法提取出每篇资讯的关键词,以及统计频次和逆向文档频率来聚类或者笨一点地话计算出资讯的相似度矩阵,即共同的key words越多,两篇资讯的相似度越高。当你的用户很少很少,你的显式反馈数据非常非常少的时候,你可以根据用户的浏览或者搜索等等各种行为,来给用户进行推荐。再猥琐一点的话,你可以在用户刚刚注册好你的应用的时候,给他一些提问,比如让他输入一些感兴趣的话题啊,或者对以前看过的电影打分什么的。(当然这些电影都是你从各个簇中随机选取的,要足够多样性)这个算法它好就好在,不需要拿到用户--项目的评分矩阵,只需要知道用户喜欢什么,就可以很快速地推荐给用户十分相关的item。这个算法需要每天都要根据你抓取的资讯,不断地计算item之间的相似性。这个算法有个好处在于可以从容应对上面的两个算法其实都很难应对的问题,就是如果你想推出一个新的item,因为没有一个人有对这个new item的评分,所以上述的两个算法不可能推荐新的东西给你,但你可以用基于内容的算法将新的item计算出它属于哪个类,然后时不时地推出你的新item,这点对于商城尤其重要。
二、协同过滤推荐
协同过滤推荐(Collaborative Filtering Recommendation)技术是推荐系统中应用最早和最为成功的技术之一。它一般采用最近邻技术,利用用户的历史喜好信息计算用户之间的距离,然后 利用目标用户的最近邻居用户对商品评价的加权评价值来预测目标用户对特定商品的喜好程度,系统从而根据这一喜好程度来对目标用户进行推荐。协同过滤最大优点是对推荐对象没有特殊的要求,能处理非结构化的复杂对象,如音乐、电影。
常见的CF会基于用户和商品本身来做,基于商品的CF对于商城网站(以Amazon为代表,当然也包括京东那种具有搞笑特色的推荐系统在内),影视类推荐,图书类推荐,音乐类推荐系统来说,item的增长速度远不如user的增长速度,而且item之间的相似性远不如user之间的相似性那么敏感,所以可以在离线系统中将item的相似度矩阵计算好,以供线上可以近乎即时地进行推荐。因为这种方法靠的是item之间的相关性进行推荐,所以推荐的item一般都和喜欢的item内容或者特性高度相似,很难推荐出用户潜在喜欢的item,多样性也比较差。
而基于用户的CF它的主要特色是可以发现和用户具有同样taste的人,有句俗话叫做观其友知其人,大概也是这个道理吧。找到用户的相似用户,通过相似用户喜欢的item推荐给该用户。因为用户的相似用户群还是比较敏感的,所以要频繁地计算出用户的相似用户矩阵,这样的话运算量会非常大。而且这个算法往往推荐出来的item很多都是大家都喜欢的比较hot的item,有的时候它提供的结果并不是个性化,反而成了大众化的推荐了。用这种算法的web应用一般都是item更新频繁,比如提供资讯类服务的应用(以“指阅”为代表的),或者笑话类推荐(以“冷笑话精选”为代表的)。当然这种算法的一个中间产物-----用户相似度矩阵是一个很有用的东西,社交类的网站可以利用这个中间产物来为用户提供相同品位的好友推荐。
三、基于关联规则推荐
基于关联规则的推荐(Association Rule-based Recommendation)是以关联规则为基础,把已购商品作为规则头,规则体为推荐对象。关联规则挖掘可以发现不同商品在销售过程中的相关性,在零 售业中已经得到了成功的应用。管理规则就是在一个交易数据库中统计购买了商品集X的交易中有多大比例的交易同时购买了商品集Y,其直观的意义就是用户在购 买某些商品的时候有多大倾向去购买另外一些商品。比如购买牛奶的同时很多人会同时购买面包。
四、组合推荐
由于各种推荐方法都有优缺点,所以在实际中,组合推荐(Hybrid Recommendation)经常被采用。研究和应用最多的是内容推荐和协同过滤推荐的组合。最简单的做法就是分别用基于内容的方法和协同过滤推荐方法 去产生一个推荐预测结果,然后用某方法组合其结果。尽管从理论上有很多种推荐组合方法,但在某一具体问题中并不见得都有效,组合推荐一个最重要原则就是通 过组合后要能避免或弥补各自推荐技术的弱点。
任何一个算法都有它独特的优势和固有的缺陷,因此单用一个算法的web应用很少,往往是将各种算法组合起来用。
一种方式是:将多种算法计算出来的结果,加权之后排序推荐给用户。
一种方式是:将多种算法计算出来的结果,各取前几个推荐给用户,这样做的好处是结果很丰富多彩。
一种方式是:用svd算法填充后的矩阵作为输入,用普通cf做计算来输出,然后排序推荐。这种叫做层次推荐,可以得到两种方法的好处。
一种方式是:对新用户做基于内容的推荐,因为新用户没有任何评分数据,对老用户用cf来做。
写在最后,推荐系统并不等于算法,而是一系列算法的结果,其中穿插了分类预测排序。很多时间推荐系统也要结合产品一起来做,对于用户关心的人和话题应该是最高的权重,这块希望微信朋友圈也能优化上,而对于热点和用户评价点赞较多的内容相应的加重,而对于那些垃圾信息也需要提供相应的反作弊机制,这块Facebook、weibo、知乎、Twitter等等都可以多研究研究。
——完

