引子:通过上周的文章,大家应该已经对“数据挖掘”有了一个更清晰全面的认识。哪些在具体业务中,如何有效应用,快速落地一个项目应用实践呢?今天我们将以一个行业实际案例为主,依据“数据挖掘方法论”【详细可参阅历史文章《数据挖掘方法论》】为大家详细解析,如何快速完成一个项目应用实践,通过数据挖掘技术和方法,获取业务应用价值。
数据挖掘方法论为开展数据挖掘项目提供了一套完整的、高效的、质量可控的项目管理过程。CRISP-DM方法论将一个数据挖掘项目的生命周期分为六个阶段,其中包括业务理解(business understanding),数据理解 (data understanding),数据准备(data preparation),建立模型(modeling),评估模型(evaluation)和结果部署(deployment)。 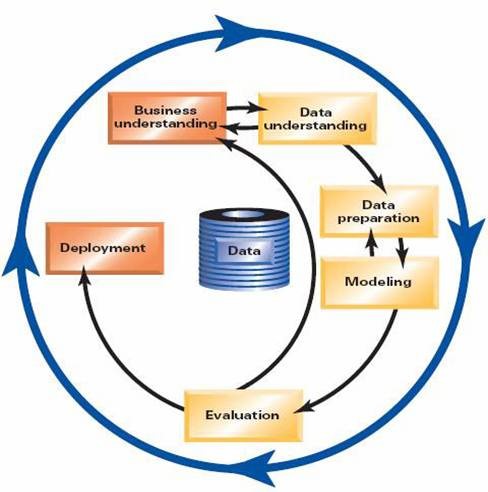
那么,在一个实际的数据挖掘工作中,如何落地实践这套挖掘方法论呢?下面我们将以“公募基金精准营销”为例,详细介绍数据挖掘项目开展流程和步骤【建模工具采用:TempoAI完成】。
阶段一:业务理解(business understanding)
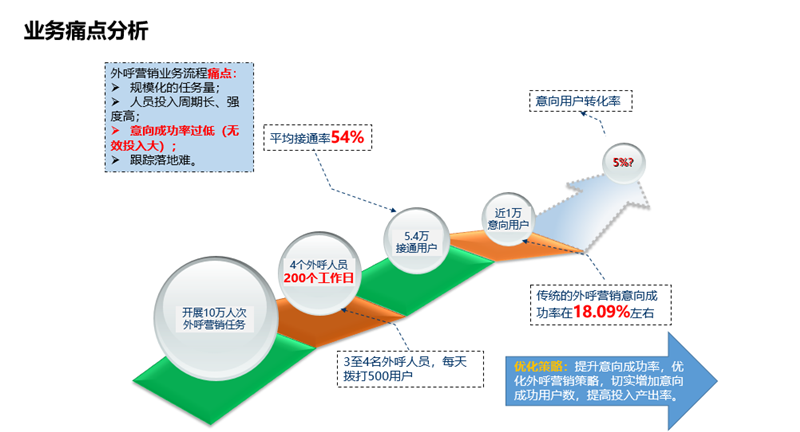
业务背景:券商发行的公募基金产品,传统的营销方式为外呼人员电话营销。传统电话营销方式存在的问题主要有两点:
- 工作量巨大,因为是用全量客户名单来打电话营销:开展10万人次外呼营销任务,要4个外呼人员1年的工作量;
- 意向成功率过低,平均接通率54%,意向成功率18.09%左右。
涉及部门:信息技术部、营销部、客服部(外呼中心)
业务目标:提升意向成功率,优化外呼营销策略,切实增加意向成功用户数,提高投入产出率。
分析方案:
- 分类预测:构建潜客预测模型,预测高概率购买公募基金的潜在客户,为券商提供精准营销客户名单。
- 分析成果验证:将分析产生的预测会够买的人员名单,提供给外呼中心,进行外呼推荐公募基金产品,最终将推荐名单外呼和传统的外呼效果进行比对,对比外呼成功率,从而判断分析成果是否显著。
阶段二:数据理解 (data understanding)
收集的数据表信息包括:
•借记卡用户基本信息表
•信用卡用户基本信息表、用户状态标识代码表
•信用卡卡片信息表、信用卡卡片代码表、卡片状态标识代码表
•信用卡交易流水信息表
•用户的业务信息表
•公共信息表:商户代码MCC码表、用户职业代码表等
•历史外呼反馈信息表
•信用卡违约状态及未还款的历史数据
•设备信息
针对收集到的数据信息,进行数据理解:
用户特征探索:待营销用户群体的分布形态,营业部分布,性别分布,风险等级分布及业务开通情况。 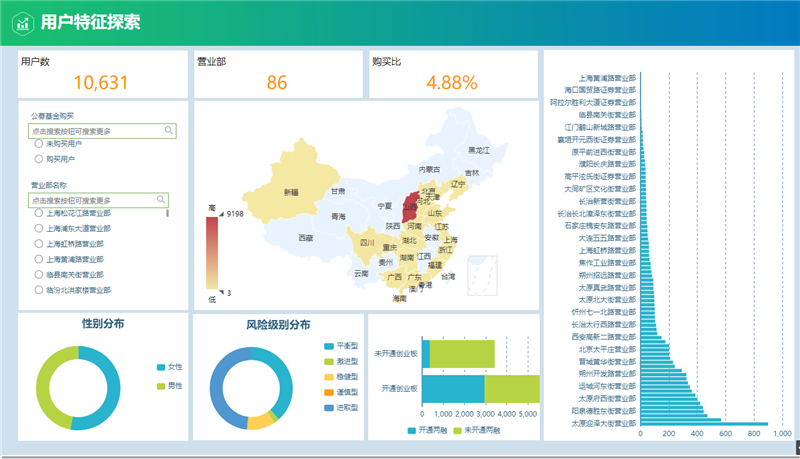
阶段三:数据准备(data preparation)
数据准备工作包括为建模工作准备数据的选择、转换、清洗、构造、整合及格式化等多种数据预处理工作。这里主要进行了数据指标体系设计、建模所需字段的生成、缺失值处理等。
TempoAI数据处理: 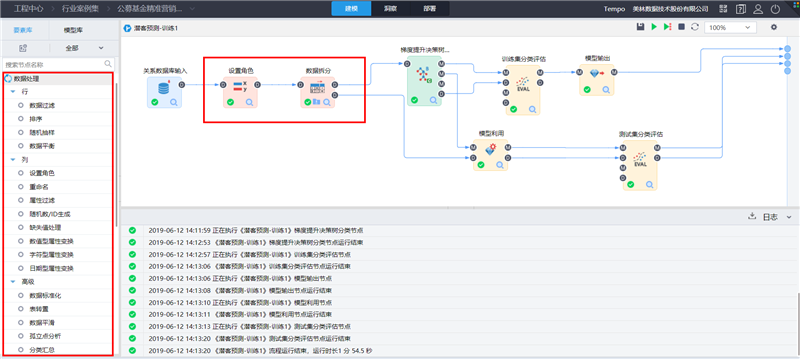
阶段四:建立模型(modeling)
基于用户基本信息如风险等级、开户年限、年龄等,资产信息如总资产、近一年最大资产、近半年日均资产等,产品交易信息如股票交易次数、近两年最后买公墓基金天数、近半年理财持有比例,构建用户公募基金潜客预测模型,基于该模型,可以预测高概率购买公募基金的潜在客户,为券商提供精准营销客户名单。在TempoAI中构建的建模流程如下: 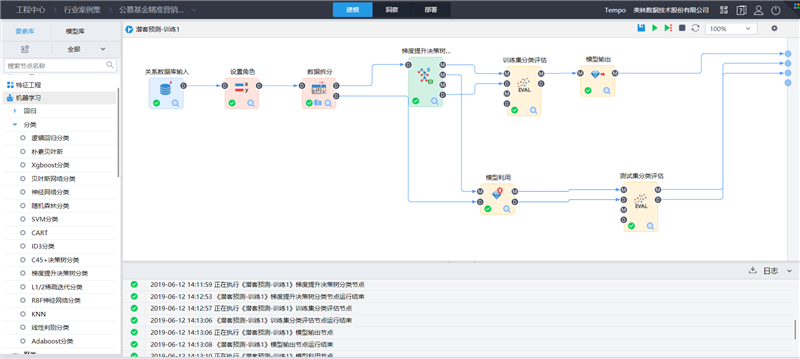
建模步骤说明:
(1)读取数据
拖入关系数据库输入节点,选择数据源,选择购买公募基金用户的历史数据集,完成数据读取。
(2)设置角色
在设置角色节点,选择参与模型训练的变量设置自变量(影响因素)和因变量(预测变量)。
自变量为:用户基本信息/资产信息及产品交易信息等字段;
因变量为:flag(是否购买公募基金,1代表购买,0代表不够买)。
(3)数据拆分
为了保证模型的可靠性,我们一般将原始数据集拆分成两个或三个数据集,这里我们拆分为两部分:一部分用于训练模型,另外一部分用于测试模型的泛化能力(预测能力)。如下图所示,70%的数据作为训练集 30%的数据作为测试集。
(4)梯度提升决策树
选择一个分类算法,构建分类模型,这里我们选择梯度提升决策树算法,将数据拆分后的训练集接入算法,参数设置如下: 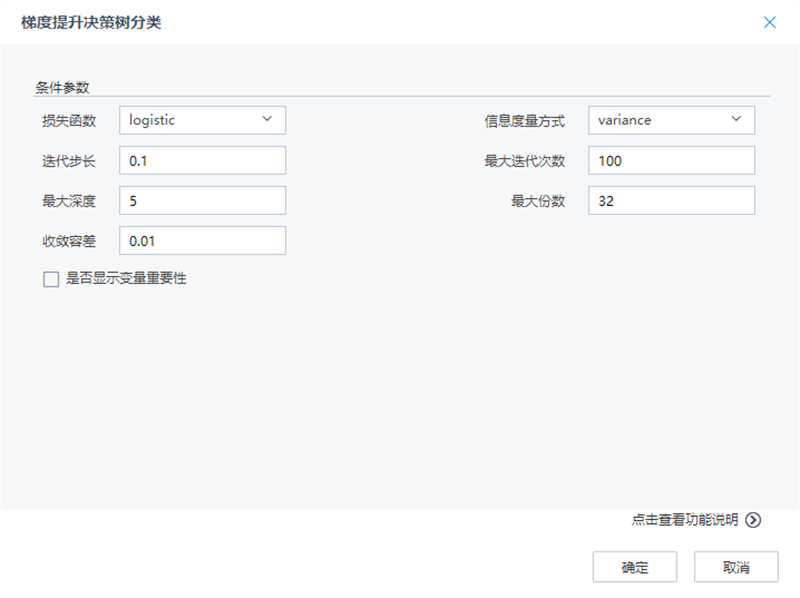
(5)训练集分类评估
将算法的M端口和D端口连接一个分类评估节点,评估训练集的预测效果。分类评估节点参数设置如下: 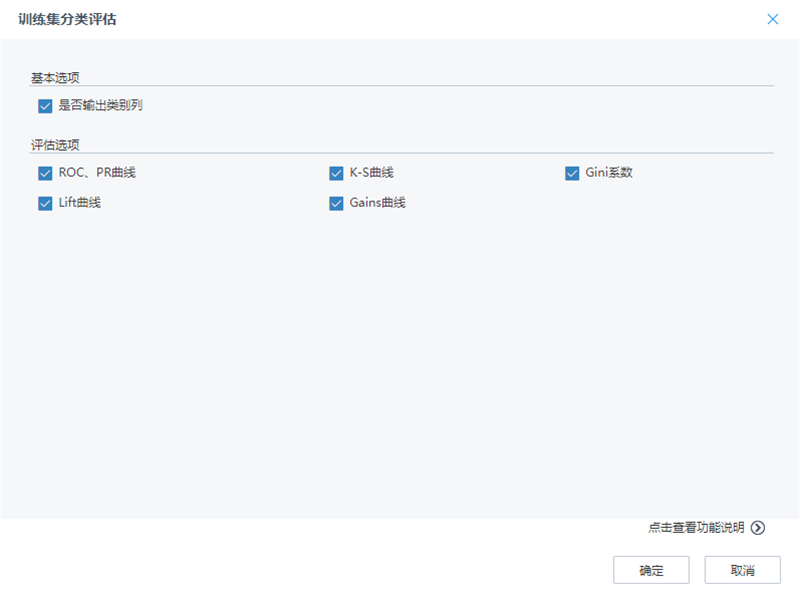
(6)模型利用
将算法输出的M端口连接模型利用节点,同时将数据拆分后的测试集D端口接入模型利用,这里将利用梯度提升决策树产生的模型对测试数据集进行预测。
(7)测试集分类评估
将模型利用输出的M端口和D端口连接一个分类评估节点,评估测试集的预测效果。
(8)模型输出
将训练好的模型输出到模型库。
(9)连接END端点,完成流程构建,点击执行。
阶段五:评估模型(evaluation)
评估模型,指在此阶段,需要从技术层面判断模型效果以及从业务层面判断模型在实际商业环境当中的实用性。
流程执行成功后,可在洞察页面,查看流程执行的结果: 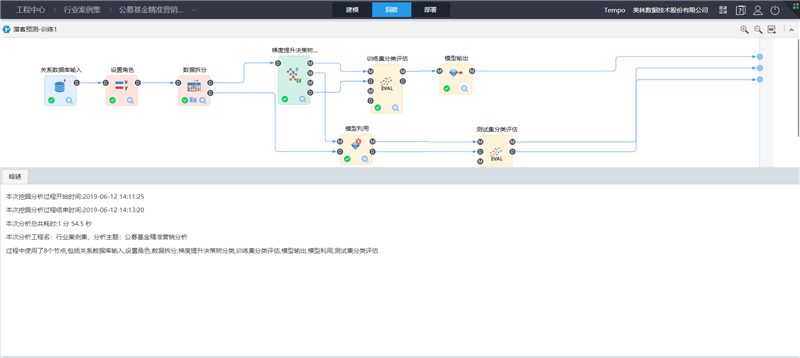
这里我们主要看分类模型评估结果及分类模型预测结果。
点击“梯度提升决策树节点”查看分类模型内容及预测结果数据集:
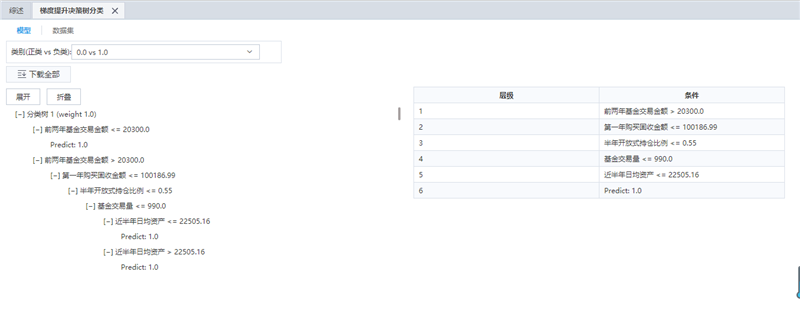
下图为模型内容:决策树及层级说明信息
下图为预测结果数据集信息:可从业务角度评估预测结果的合理性。 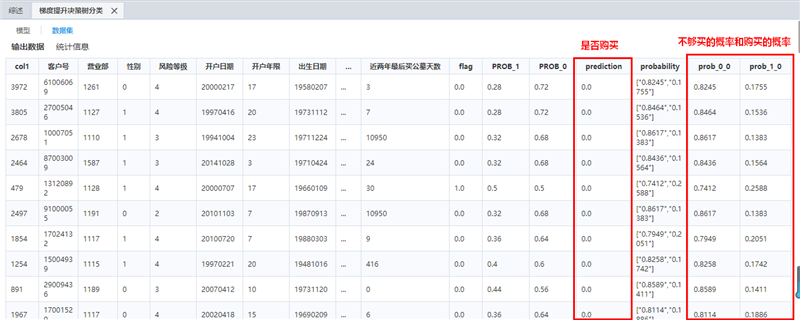
点击“分类评估节点”查看分类评估结果(包括训练集评估和测试集评估)
训练集评估结果:包括模型的准确率、混淆矩阵、ROC/PR、Lift曲线、Gains曲线、基尼系数 、K-S曲线。综合各评估指标及曲线,模型评估效果较好。 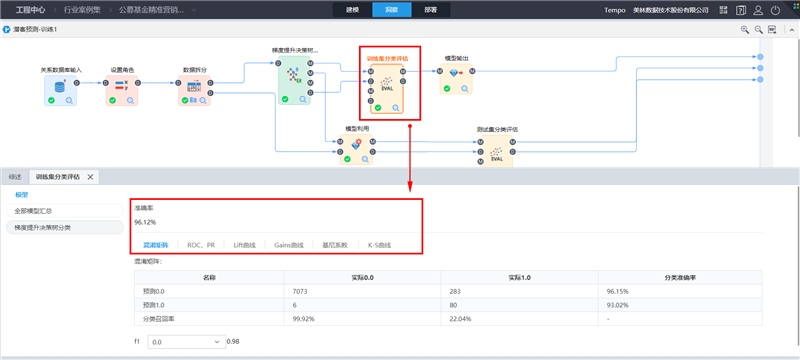
测试集评估结果:如下图 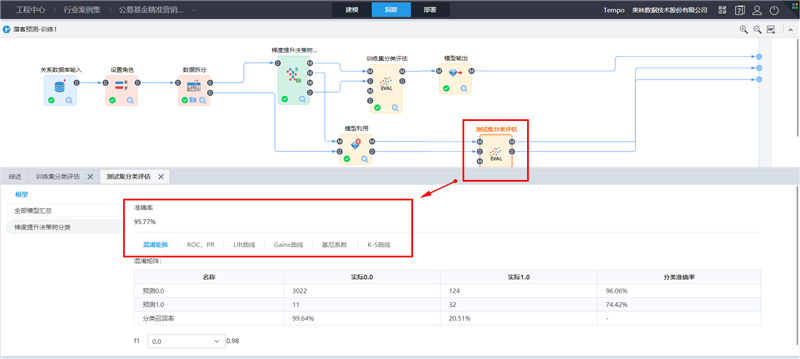
阶段六:结果部署(deployment)
经过模型训练和模型测试,得到了比较理想的预测模型。需要将模型的成果书面化,结合前几个阶段进行总结,形成数据“分析报告”。如果涉及到工程化应用,还需要将模型发布成不同方式(调度、同步/异步服务API、实时服务等),供其它业务系统进行整合,形成最终的决策应用系统,需要“部署应用”。
分析报告
TempoAI洞察页面,支持直接导出Word格式的完整挖掘流程建模分析报告。如下图所示: 
部署应用
构建一个预测流程,利用训练好的模型,然后把预测流程发布,并部署为应用。
(1)构建预测流程
将要预测的数据作为数据源,读取并利用已输出的分类预测模型,构建预测流程。如下所示: 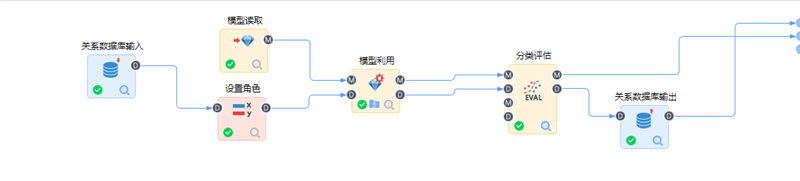
(2)发布预测流程
进入“部署”“-“发布”,将预测流程发布。
(3)构建调度
在“部署”-“应用”,将已发布的预测流程构建调度任务。平台提供任务调度器,可配置调度任务,将的一个或多个流程在指定的日期范围内按一定的频率定期执行,完成预测任务。如下所示: 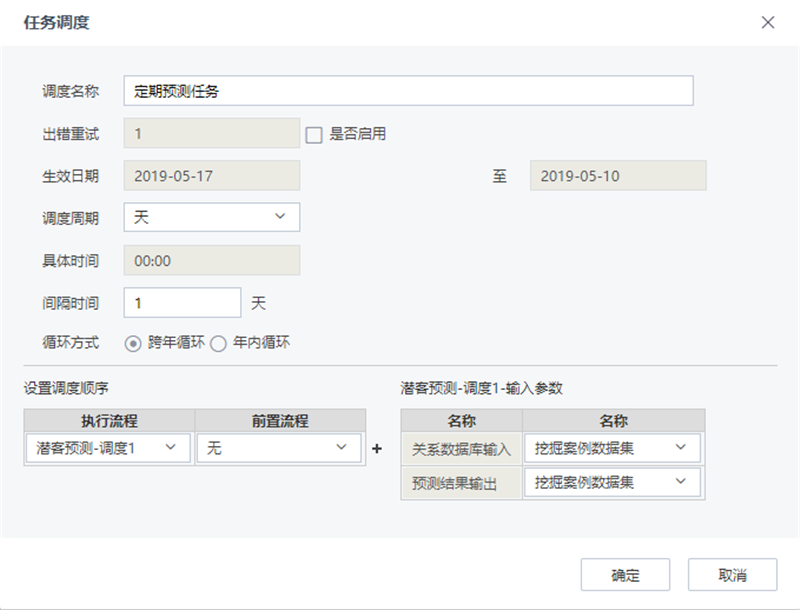
(4)构建服务
在“部署”-“应用”,用户可将已发布流程构建一个服务,根据流程数据源的不同,分为同步服务、异步服务和流服务。同步服务:支持第三方系统通过Thrift/Rest调用流程,实时返回预测结果。异步服务:支持第三方系统通过Rest调用流程,按照指定频率定期执行,完成模型构建或数据预测,预测结果输入到指定数据库。流服务:开启服务,当Kafka的队列中有消息时,即可执行流程,完成对于流式数据的实时处理。
(5)服务调用
第三方系统可调用相应的API,通过在第三方系统输入参数,调用服务,并返回服务的执行状态。
调用方式:打开该服务的测试页面,“下载示例代码”、“下载SDK”。将下载的示例代码文件中的代码段复制粘贴,即可通过运行代码调用该异步服务。调用接口可供营销业务系统进行整合,形成最终的决策应用系统,给营销外呼中心提供营销名单,指导实际业务的开展。
(6)部署结果验证
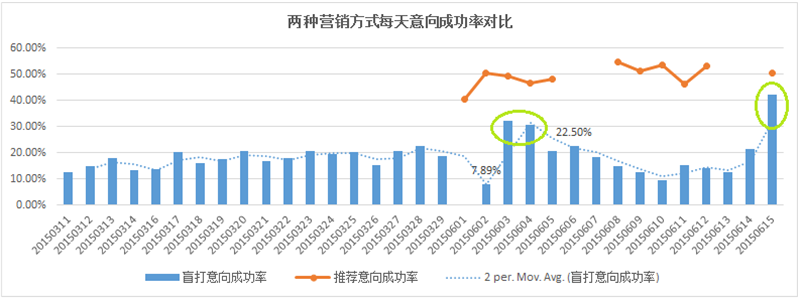
将预测分析产生的预测够买人员名单,提供给外呼中心,进行外呼推荐公募基金产品,最终将推荐名单外呼和传统的外呼效果进行比对,对比结果如下:推荐外呼11天,拨打5877通电话(占传统外呼36.01%),得到意向客户数1664个,是传统外呼开展32天的整体意向客户数的1.08倍。结合营销活动的成本和成果两个方面考虑,综合效果提升3.14倍。