
作者:陈老师 个人公众号:接地气学堂
陈老师新课:商业分析全攻略 https://edu.hellobi.com/course/308 用数据分析方法解决商业问题,目前已经100+学员加入!5星好评。分析思维双剑合璧,四大板块:概念篇、行业篇、思维篇、套路篇
一、前言
看pandas之前我建议先看我的numpy总结,效果更佳。
【Data Mining】机器学习三剑客之Numpy常用用法总结
可以大概理解为numpy主要是用来生成数据,并且进行数据运算的工具
而pandas主要是用来整个数据的管理,也就是整个数据的摆放或是一些行列的操作等等。当然也不完全是这个样子。
二、下载、安装、导入
用anaconda安装是十分方便的,如果你已经安装了tf,keras之类的,其实已经直接把numpy安装了,一般来说安装就是pip命令。
1pip install pandas #py2
2pip3 install pandas #py3
用法则是
1import pandas as pd # 一般as为pd来操作
三、常用用法总结
1.Series
1# -*- coding: utf-8 -*-
2import pandas as pd
3import numpy as np
4
5df1 = pd.DataFrame(np.arange(12).reshape((3, 4)))
6print df1
7"""
8 0 1 2 3
90 0 1 2 3
101 4 5 6 7
112 8 9 10 11
12"""
13s = pd.Series([1, 1, 44, 22]) #创建一个series
14s_type_int_float = pd.Series([1, 1, 44, 22], dtype=np.float32) #更改type
15s_type = pd.Series([1, np.nan, 44, 22]) #np.nan就是就是Nan缺省值
16 #更改index
17s_index = pd.Series([1, np.nan, 44, 22], index=["c", "h", "e", "hongshu"])
18print("s:")
19print(s)
20print("s_type_int_float:")
21print(s_type_int_float)
22print("s_type:")
23print(s_type)
24print("s_index:")
25print(s_index)
26"""
27s:
280 1
291 1
302 44
313 22
32dtype: int64
33
34s_type_int_float:
350 1.0
361 1.0
372 44.0
383 22.0
39dtype: float32
40
41s_type:
420 1.0
431 NaN
442 44.0
453 22.0
46dtype: float64
47
48s_index:
49c 1.0
50h NaN
51e 44.0
52hongshu 22.0
53dtype: float64
54"""
一些说明:
series相当于dataframe的一个元素,pandas的主体数据类型为dataframe,一个series单位相当于dataframe的一行,当然是连带这整个dataframe的column和元素dtype的信息的。(ps:这里可以先记着,后面慢慢才能全都懂,先记住这么个关系,后面讲)
生成series的左面一列其实就是dataframe的每一列的index,例如上述s左面为[0, 1, 2, 3]其实就是和我上面写的那个dataframe的最上面的单独的一行对应,代表每一列的名字,有点像excel表格中的每一列的name。
上述采用list生成的series,理论上用array-like的形式都可以生成,当然numpy毋庸置疑可以后面会有展示,如果生成的series的list中的每个元素为整型,则dtype默认推理为int64,如果元素中海包括nan缺省值则按浮点数处理,所以默认为float64,可知如果都为浮点数则默认为float64。
如果要是自定义dtype和往常一样自然转换,整数化或者浮点化。
1# -*- coding: utf-8 -*-
2import pandas as pd
3import numpy as np
4
5s_np1 = pd.Series(np.arange(6)) #利用numpy生成series的方法
6
7data_numpy = np.array([1, 2, 3, 45], dtype=np.float32)
8s_np2 = pd.Series(data_numpy)
9
10data_numpy1 = np.array([1, 2, 3, 45], dtype=np.int8)
11s_np3 = pd.Series(data_numpy1)
12
13data_numpy2 = np.array([1, 2, 3, 45])
14s_np4 = pd.Series(data_numpy2)
15
16print(s_np1)
17print(s_np2)
18print(s_np3)
19print(s_np4)
20"""
210 0
221 1
232 2
243 3
254 4
265 5
27dtype: int64
280 1.0
291 2.0
302 3.0
313 45.0
32dtype: float32
330 1
341 2
352 3
363 45
37dtype: int8
380 1
391 2
402 3
413 45
42dtype: int64
43"""
上面这个主要看dtype,可知规律为通过numpy生成series时dtype跟随numpy的类型。
2、 DataFrame
①、df的index和colomns操作
1# -*- coding: utf-8 -*-
2import pandas as pd
3import numpy as np
4
5
6# 通过numpy生成随机0-10的shape为(3, 4)的dataframe
7df_np = pd.DataFrame(np.random.randint(low=0, high=10, size=(3, 4)))
8print(df_np)
9
10# 生成随机-1-1的dataframe
11# 更改index
12df_index = pd.DataFrame(np.random.randn(3, 4), index=['f', 's', 't'])
13print(df_index)
14
15# 更改column
16df_colums = pd.DataFrame(np.arange(12).reshape((3, 4)), columns=['che', 'hong', 'shu', '24'])
17print(df_colums)
18
19"""
20 0 1 2 3
210 2 3 0 3
221 7 0 5 8
232 0 5 2 7
24
25 0 1 2 3
26f -2.216776 -1.506733 0.870351 1.361973
27s 1.104645 -1.538397 -0.616963 -2.101459
28t -1.423237 -0.378047 -0.294814 -0.200800
29
30 che hong shu 24
310 0 1 2 3
321 4 5 6 7
332 8 9 10 11
34"""
35
36#use dict to create dataframe
37dates_value = pd.date_range('20181222', periods=3)
38#dict的key对应于df的colomn
39df_dict = pd.DataFrame({'che': 22.22,
40 'hong': pd.Series(np.array([1, 2, 3], dtype=np.float32)),
41 'shu': dates_value})
42print(df_dict)
43"""
44 che hong shu
450 22.22 1.0 2018-12-22
461 22.22 2.0 2018-12-23
472 22.22 3.0 2018-12-24
48
这里需要注意的一点:dataframe中的colomn参数其实就是series中的index。
总结一下:
dataframe可以通过dict和numpy生成
主要设置参数为index和colomns, index为每行的名称,colomns为每列的,对应于每一行的series的index。
利用dict生成dataframe时,dict的keys对应于dataframe的colomns
②、df的各种属性
1import pandas as pd
2import numpy as np
3# pandas.Categorical
4#https://blog.csdn.net/weixin_38656890/article/details/81348539
5
6
7df2 = pd.DataFrame({'A': 1.,
8 'B': pd.Timestamp('20130102'),
9 'C': pd.Series(1, index=list(range(4)), dtype='float32'),
10 'D': np.array([3, 6, 9, 12], dtype=np.int32),
11 'E': pd.Categorical(["test", "train", "test", "train"]),
12 'F': 'che'})
13print(df2)
14print(df2.dtypes) #return the data type of each column.
15"""
16 A B C D E F
170 1.0 2013-01-02 1.0 3 test che
181 1.0 2013-01-02 1.0 6 train che
192 1.0 2013-01-02 1.0 9 test che
203 1.0 2013-01-02 1.0 12 train che
21A float64
22B datetime64[ns]
23C float32
24D int32
25E category
26F object
27"""
28print(df2.index)
29print(df2.columns)
30"""
31Int64Index([0, 1, 2, 3], dtype='int64')
32Index([u'A', u'B', u'C', u'D', u'E', u'F'], dtype='object')
33"""
34print(df2.values)
35# 返回数据类型为numpy可知取出元素其中一个方法是变成list之后取出即可
36# 当然这个方法速度慢,有更好的内置取值的方法
37print(type(df2.values))
38"""
39[[1.0 Timestamp('2013-01-02 00:00:00') 1.0 3 'test' 'che']
40 [1.0 Timestamp('2013-01-02 00:00:00') 1.0 6 'train' 'che']
41 [1.0 Timestamp('2013-01-02 00:00:00') 1.0 9 'test' 'che']
42 [1.0 Timestamp('2013-01-02 00:00:00') 1.0 12 'train' 'che']]
43<type 'numpy.ndarray'>
44"""
45# 数字类data的各种数学计算结果
46# 数量、平均、标准差、最小等
47print(df2.describe())
48"""
49 A C D
50count 4.0 4.0 4.000000
51mean 1.0 1.0 7.500000
52std 0.0 0.0 3.872983
53min 1.0 1.0 3.000000
5425% 1.0 1.0 5.250000
5550% 1.0 1.0 7.500000
5675% 1.0 1.0 9.750000
57max 1.0 1.0 12.000000
58"""
59
60"""
61原dataframe 方便对比观看
62 A B C D E F
630 1.0 2013-01-02 1.0 3 test che
641 1.0 2013-01-02 1.0 6 train che
652 1.0 2013-01-02 1.0 9 test che
663 1.0 2013-01-02 1.0 12 train che
67"""
68print(df2.T) #转置
69""" 0 ... 3
70A 1 ... 1
71B 2013-01-02 00:00:00 ... 2013-01-02 00:00:00
72C 1 ... 1
73D 3 ... 12
74E test ... train
75F che ... che
76"""
77print(df2.sort_index(axis=1, ascending=False)) # axis=1 相当于colomn元素排序
78print(df2.sort_index(axis=0, ascending=False)) # axis=0 相当于index排序
79# 其他value顺着index或者colomns排序即可
80"""
81 F E D C B A
820 che test 3 1.0 2013-01-02 1.0
831 che train 6 1.0 2013-01-02 1.0
842 che test 9 1.0 2013-01-02 1.0
853 che train 12 1.0 2013-01-02 1.0
86 A B C D E F
873 1.0 2013-01-02 1.0 12 train che
882 1.0 2013-01-02 1.0 9 test che
891 1.0 2013-01-02 1.0 6 train che
900 1.0 2013-01-02 1.0 3 test che
91"""
92print(df2.sort_values(by='E')) #通过colomn为E的单位的value来排序(如果是数字则按数字大小排列,字母按字母大小)
93"""
94 A B C D E F
950 1.0 2013-01-02 1.0 3 test che
962 1.0 2013-01-02 1.0 9 test che
971 1.0 2013-01-02 1.0 6 train che
983 1.0 2013-01-02 1.0 12 train che
99"""
3、select
1# -*- coding: utf-8 -*-
2import pandas as pd
3import numpy as np
4
5dates = pd.date_range('20121222', periods=6)
6df = pd.DataFrame(np.arange(24).reshape((6, 4)), index=dates, columns=['A', 'B', 'C', 'D'])
7#easy selection
8print(df)
9"""
10 A B C D
112012-12-22 0 1 2 3
122012-12-23 4 5 6 7
132012-12-24 8 9 10 11
142012-12-25 12 13 14 15
152012-12-26 16 17 18 19
162012-12-27 20 21 22 23
17"""
18# select 'A' colomn
19print(df['A'])
20print(df.A)
21"""
222012-12-22 0
232012-12-23 4
242012-12-24 8
252012-12-25 12
262012-12-26 16
272012-12-27 20
28Freq: D, Name: A, dtype: int64
292012-12-22 0
302012-12-23 4
312012-12-24 8
322012-12-25 12
332012-12-26 16
342012-12-27 20
35Freq: D, Name: A, dtype: int64
36"""
37# select 0-3 rows
38print(df[0: 3])
39print(df['2012-12-22':'2012-12-24'])
40"""
41 A B C D
422012-12-22 0 1 2 3
432012-12-23 4 5 6 7
442012-12-24 8 9 10 11
45 A B C D
462012-12-22 0 1 2 3
472012-12-23 4 5 6 7
482012-12-24 8 9 10 11
49"""
50
51
52
53"""
54原dataframe, 适宜对比观看
55 A B C D
562012-12-22 0 1 2 3
572012-12-23 4 5 6 7
582012-12-24 8 9 10 11
592012-12-25 12 13 14 15
602012-12-26 16 17 18 19
612012-12-27 20 21 22 23
62"""
63# select by label= loc
64# 这里的label其实就是我之前说dataframe对应的colomn和index
65# 和平时的二维的numpy选取相似,只是把index转换为对应的label name
66
67print(df.loc['20121224']) #loc[]内单个一个label name时为行的index name
68print(df.loc[:, 'A':'C']) # : 代表所有的行都要 逗号后面为colomns的label name
69"""
70A 8
71B 9
72C 10
73D 11
74Name: 2012-12-24 00:00:00, dtype: int64
75 A B C
762012-12-22 0 1 2
772012-12-23 4 5 6
782012-12-24 8 9 10
792012-12-25 12 13 14
802012-12-26 16 17 18
812012-12-27 20 21 22
82"""
83print(df.loc[:, ['A', 'C']])
84print(df.loc['20121223', ['A', 'C']])
85"""
86 A C
872012-12-22 0 2
882012-12-23 4 6
892012-12-24 8 10
902012-12-25 12 14
912012-12-26 16 18
922012-12-27 20 22
93A 4
94C 6
95Name: 2012-12-23 00:00:00, dtype: int64
96"""
97
98"""
99原dataframe, 适宜对比观看
100 A B C D
1012012-12-22 0 1 2 3
1022012-12-23 4 5 6 7
1032012-12-24 8 9 10 11
1042012-12-25 12 13 14 15
1052012-12-26 16 17 18 19
1062012-12-27 20 21 22 23
107"""
108# select by position(index)= iloc
109# 这里的selection index其实就是完全和numpy相似
110# (row index, colomn index)
111# 利用行的索引和列的索引来取值
112print(df.iloc[3])
113print(df.iloc[3:5, 1:3])
114print(df.iloc[[1, 3], 1:3])
115"""
116A 12
117B 13
118C 14
119D 15
120Name: 2012-12-25 00:00:00, dtype: int64
121 B C
1222012-12-25 13 14
1232012-12-26 17 18
124 B C
1252012-12-23 5 6
1262012-12-25 13 14
127"""
128
129# mixed selection = ix
130# label + position selection
131print(df.ix[1, ['A', 'D']])
132"""
133A 4
134D 7
135Name: 2012-12-23 00:00:00, dtype: int64
136"""
137# Boolean indexing
138# use bool to select
139print(df[df.B > 9])
140"""
141 A B C D
1422012-12-25 12 13 14 15
1432012-12-26 16 17 18 19
1442012-12-27 20 21 22 23
145"""
一些总结:
一种选择数据有五种:简单直接选取,label选取(loc),index选取(iloc),混合选取(ix),真假选取
其实第二种到第四种选取,有规律可言,其实都是[row,colomn]的组合而已,只是一个是用label name,一个是index name,混合是label or index
第一种其实就是label或者index的单列或者行选取,但是也有特殊表达比如df.A
最后一种主要用于删选数据的。
4、读取文件,输出文件
在使用中主要针对于excel文件和csv文件,个人推荐csv文件,因为在很多比赛和项目中都采用此类型,主要是兼容性好一些,我在linux下使用excel问题很多,当然对于pandas两样的使用很相似。
首先我们采用常用的机器学习数据集:iris数据集,链接如下

数据集简单介绍:鸢尾花的特征作为数据来源,数据集包含150个数据集,分为3类,每类50个数据,每个数据包含4个属性,数据集iris.csv截图如下。
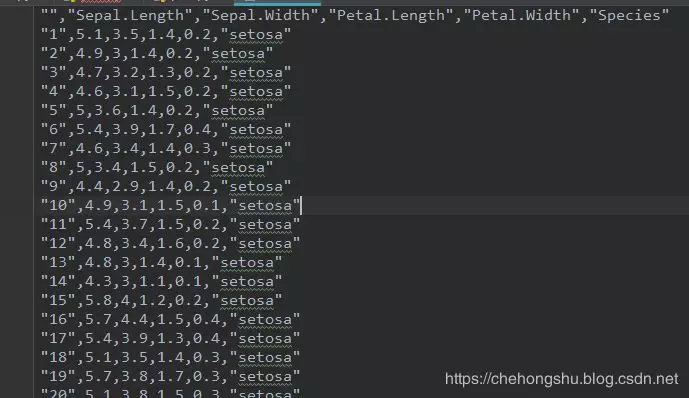
数据集内容
此处进行简单读入,并按照算法输入进行简单处理,并输出
1import pandas as pd
2import numpy as np
3# 读csv文件
4Iris_dataset = pd.read_csv("./Iris_dataset/iris.csv")
5# 给每列一个column label
6Iris_dataset.columns = ['data_index', 'sepal_len', 'sepal_width', 'petal_len', 'petal_width', 'class']
7# drop掉第一列(无用的列,表示数据index)
8Iris_dataset.drop(columns='data_index', axis=1, inplace=True)
9# 判断是否存在nan
10if np.any(Iris_dataset.isnull()) == True:
11 print("有空缺值")
12 Iris_dataset.dropna()
13else:
14 print("无空缺值")
15# 进行把string label name转换为int型
16def fun(x):
17 if x == 'setosa':
18 return 0
19 elif x == 'versicolor':
20 return 1
21 elif x == 'virginica':
22 return 2
23Iris_dataset['class'] = Iris_dataset['class'].apply(lambda x: fun(x))
24# 前五条数据
25print(Iris_dataset.head())
26# 输出.csv文件
27Iris_dataset.to_csv('iris_handle_data')
输出文件如下:
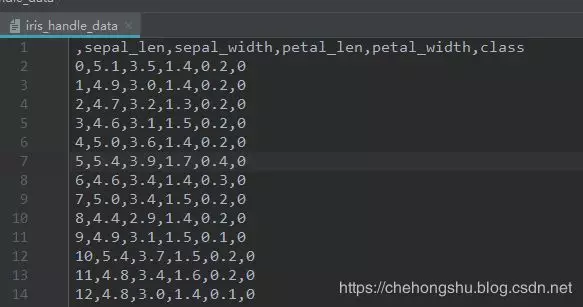 输出结果
输出结果
主要输出输入,我建议使用.csv数据,若使用excel文件函数如下
1p = pd.read_excel()
2p.to_excel()