

作者:李誉辉
四川大学在读研究生
简介:rvest是Hadley大神开发的包,使用非常简单,不需要懂得太多的HTML和CSS知识,
当然对于反爬虫的web,基本上就力不从心了,这种情况还是使用Python吧,毕竟术业有专攻。
首先安装 SelectorGadget
(https://chrome.google.com/webstore/detail/selectorgadget/mhjhnkcfbdhnjickkkdbjoemdmbfginb),这个插件很方便,可以获得网页中某些部分的相关tags。
如果不懂HTML和CSS,最好安装,如果懂,还是用Python吧。
常用函数:
read_html(), 读取html文档或链接,可以是url链接,也可以是本地的html文件,
甚至是包含html的字符串。html_nodes(), 选择提取文档中指定元素的部分。
支持css路径选择, 或xpath路径选择。
如果tags层数较多,必须使用selectorGadget复制准确的路径。
使用方式:开启SelectorGadget,然后鼠标选中位置,右击选择检查元素,光标移动到tags上。
然后选择copy,选择selector或xpath 选项。html_text(),提取tags内文本,html_table(), 提前tags内表格。html_form(),set_values(), 和submit_form()分别表示提取、修改和提交表单。
1.文本提取
我们以 boss直聘
https://www.zhipin.com/?ka=header-home-logo,网站为例进行演示。 首先在搜索框内输入“数据分析”进行搜索,范围选择全国, 可以打开如下页面:

然后我们单击Selector Gadget插件按钮以开启该功能,再次点击可关闭。
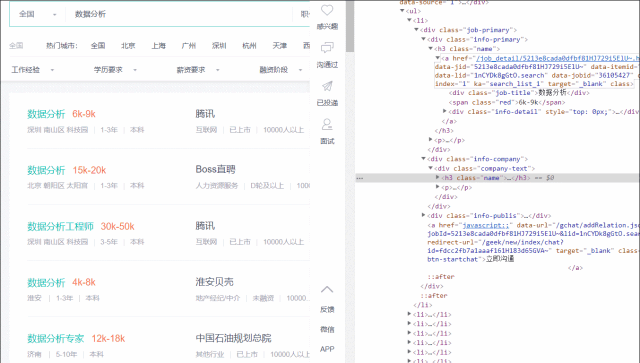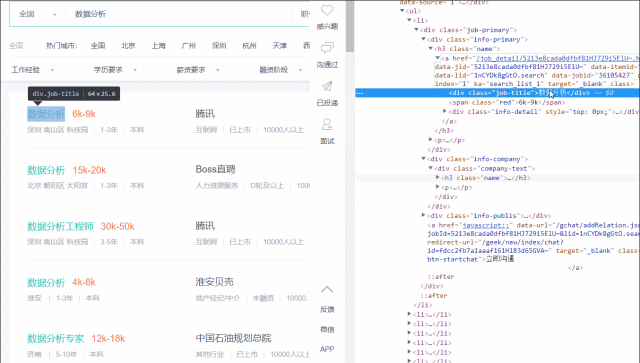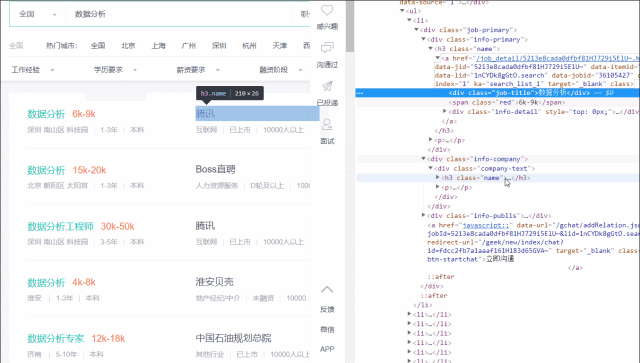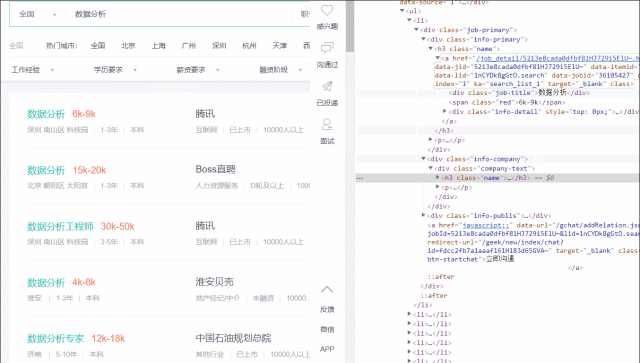
单击后,鼠标指针悬浮于web上任意的tags元素,都会出现黄色的高亮框。如下图所示:
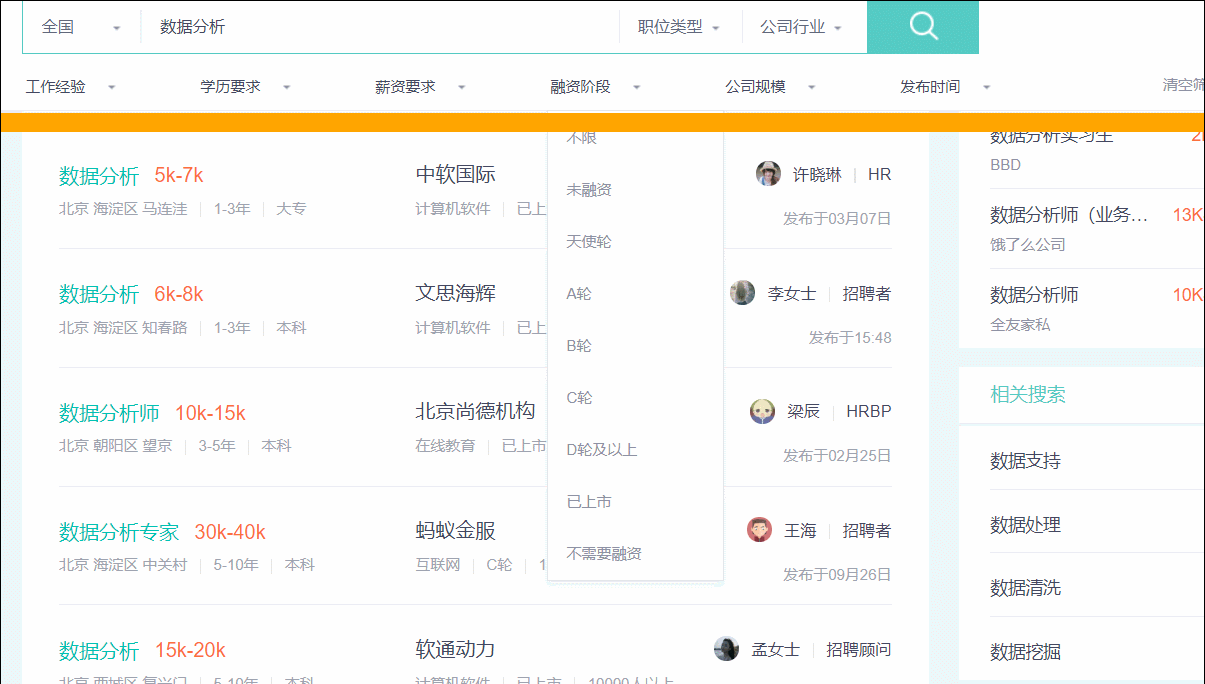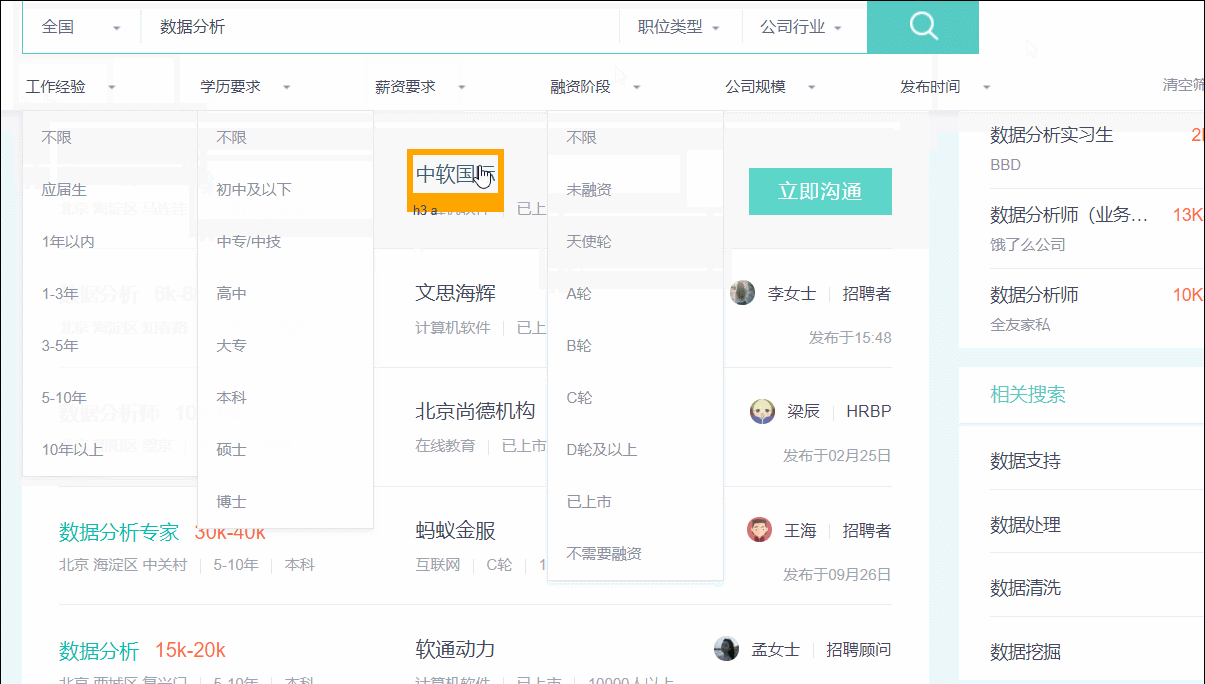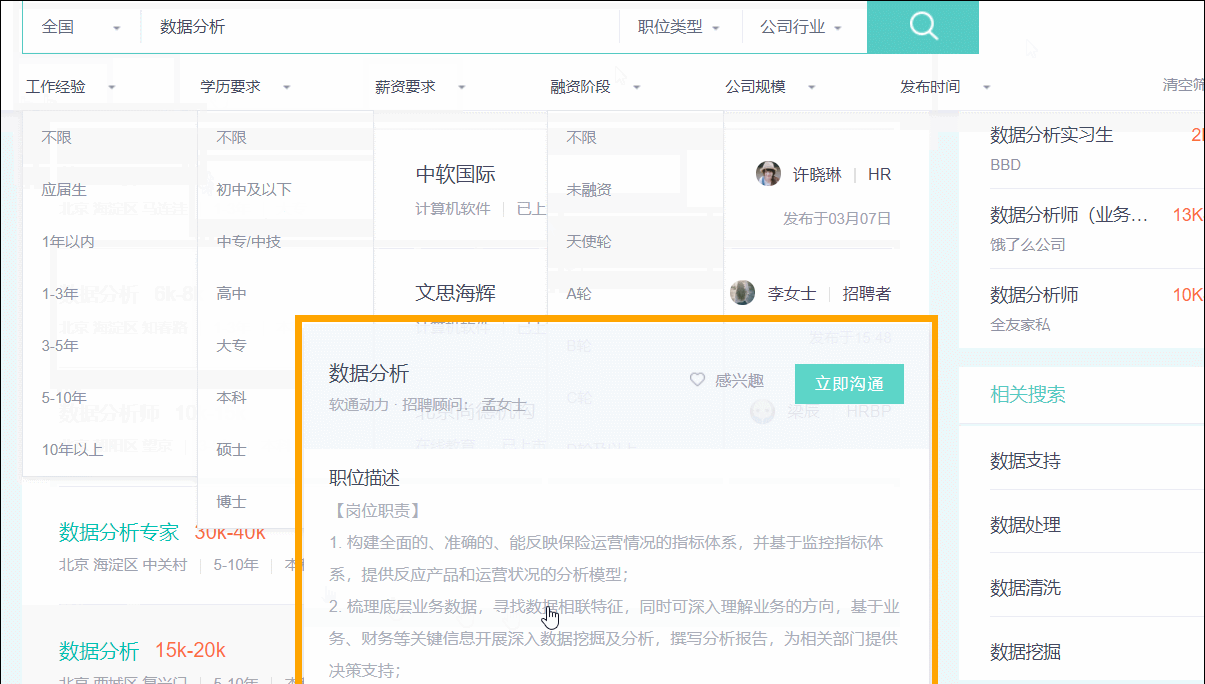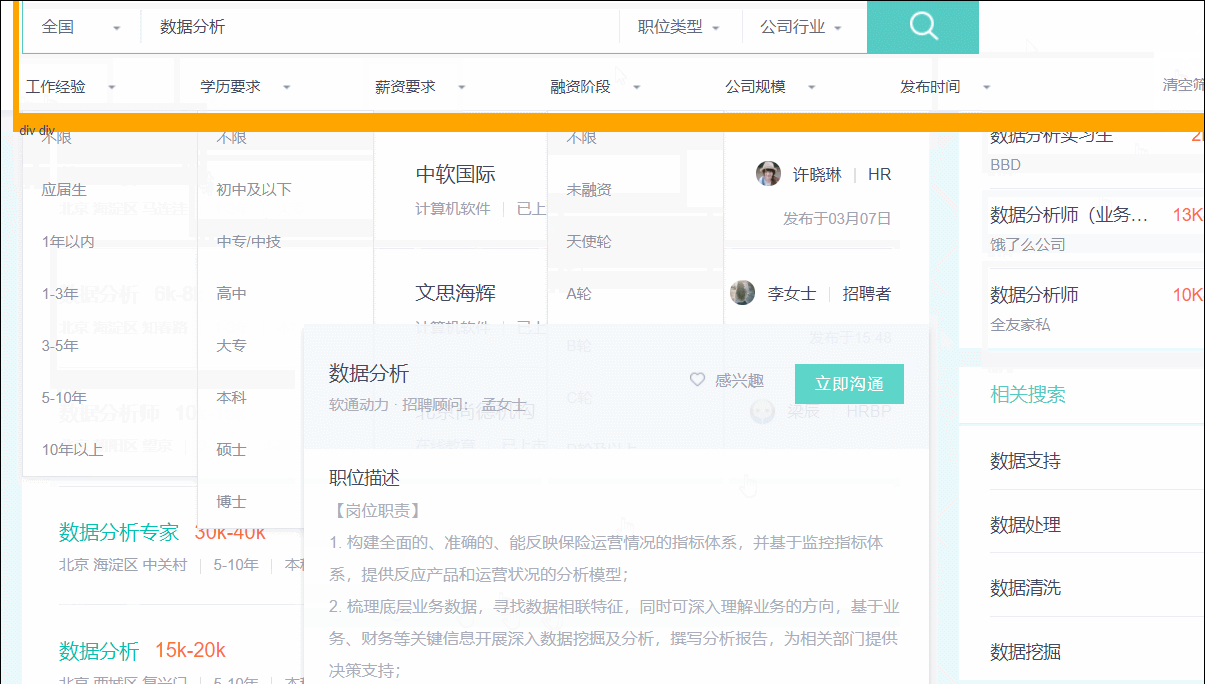
选中需要的元素后,右击,然后“检查”就能打开源代码并定位到该元素,如下图:
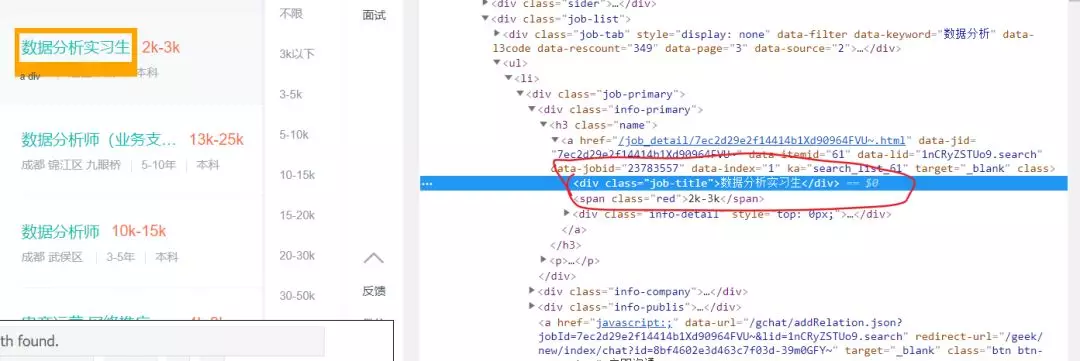
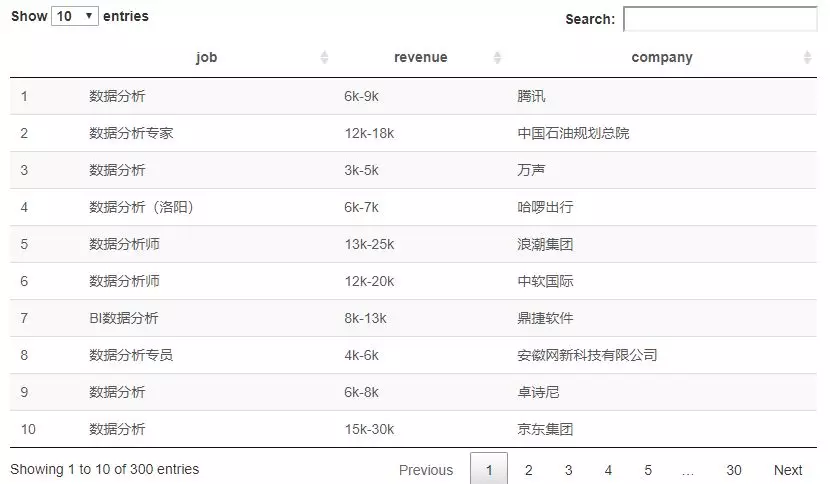
通过浏览器,发现左侧的岗位tags为.info-primary .name,公司名称为.info-company .name。
其中的句点.表示类对象,多级类对象用空格隔开。
然后用read_html()打开该web。
1library(rvest)
2library(magrittr)
3
4# 打开网页
5site_1 <- "https://www.zhipin.com/job_detail/?query=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90&scity=100010000&industry=&position="
6web_1 <- read_html(x = site_1)
7
8tag_job <- ".info-primary .name .job-title" # 岗位名字
9tag_rev <- ".info-primary .name .red" # 薪水
10tag_com <- ".info-company .company-text .name" # 公司名字
11
12# 开始抓取
13job_1 <- html_nodes(x = web_1, css = tag_job)
14rev_1 <- html_nodes(x = web_1, css = tag_rev)
15com_1 <- html_nodes(x = web_1, css = tag_com)
16
17# 从tags中提取文本内容
18job_1 %<>% html_text()
19rev_1 %<>% html_text()
20com_1 %<>% html_text()
21
22# 合并向量为数据框
23job_com <- data.frame(job = job_1,
24 revenue = rev_1,
25 company = com_1,
26 stringsAsFactors = FALSE)
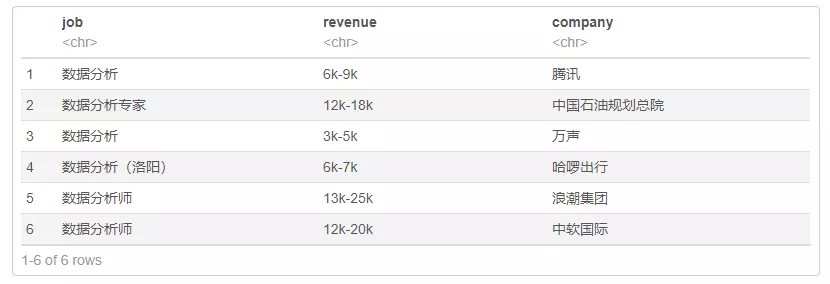
27head(job_com)
28rm(site_1, web_1, job_1, com_1)
提取web中的文本,就采用这种方法,很多时候,文本内容复制,
无法直接用html_text()将文本提取出来,
这时候就需要用正则表达式和stringr包。
2.多重页面
很多时候,一个web项目中,有多重页面,即下一页。
这就需要找到每一页的url规律,找到规律后,增加循环就能搞定了。
这里我们发现第2页开始,url就出现变化了,从第2页到最后一页(最后1页还没找到), 每一页都只改变url末尾的page=n。事实上,大多数网页都有这个page=n。
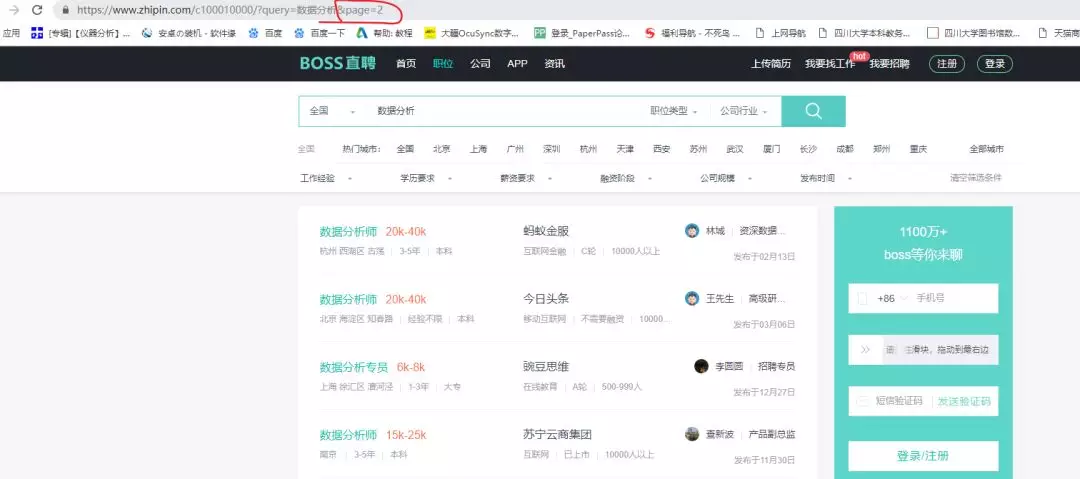
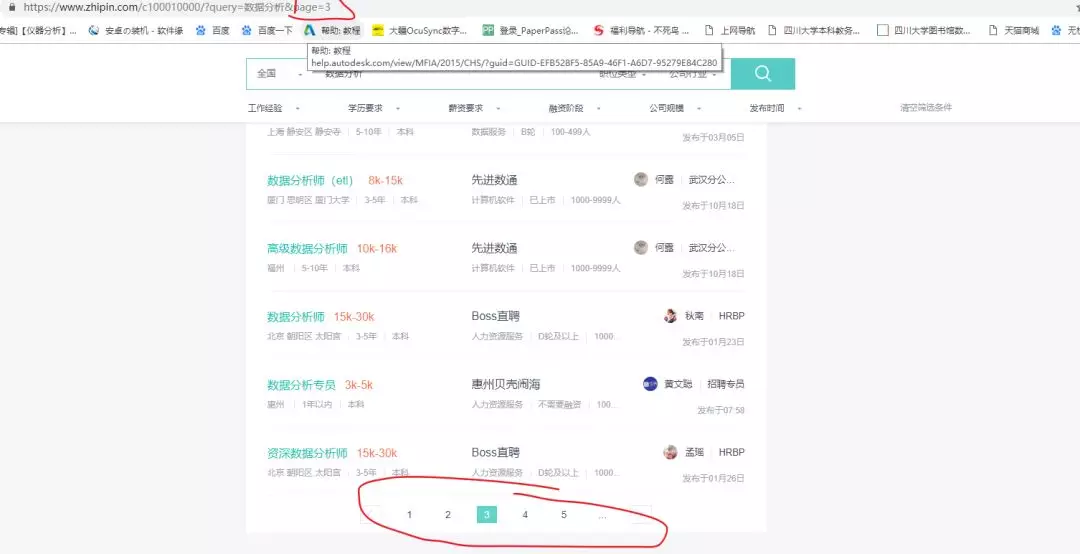
通过不断点击下一页,发现最后一页是第10页,

接下来我们爬取第2页到第10页
1library(rvest)
2library(magrittr)
3
4url_begin <- "https://www.zhipin.com/c100010000/?query=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90&page="
5
6
7for (n in 2:10) {
8 myurl <- paste0(url_begin, n)
9 page_n <- read_html(x = myurl)
10
11 # 开始抓取
12 job_n <- html_nodes(x = page_n, css = tag_job) %>% html_text()
13 rev_n <- html_nodes(x = page_n, css = tag_rev) %>% html_text()
14 com_n <- html_nodes(x = page_n, css = tag_com) %>% html_text()
15
16 # 合并向量为数据框
17 job_com_n <- data.frame(job = job_n,
18 revenue = rev_n,
19 company = com_n,
20 stringsAsFactors = FALSE)
21
22
23 job_com <- rbind(job_com, job_com_n) # 添加到job_com内
24}
25
26rm(job_n, rev_n, com_n, job_com_n)
27str(job_com)
28DT::datatable(job_com) # 交互式表格输出
1## 'data.frame': 300 obs. of 3 variables:
2## $ job : chr "数据分析" "数据分析专家" "数据分析" "数据分析(洛阳)" ...
3## $ revenue: chr "6k-9k" "12k-18k" "3k-5k" "6k-7k" ...
4## $ company: chr "腾讯" "中国石油规划总院" "万声" "哈啰出行" ...
3.表格提取
这里我们以 pm2.5 in(http://www.pm25.in/)网站上的空气污染为例,进行表格提取。
首先打开该网站,然后我们选择一个城市,如选择“成都”,寻找url变化规律。
发现新增url后缀:chengdu。使用SelectorGadget审查元素,发现表格的类为“table”。
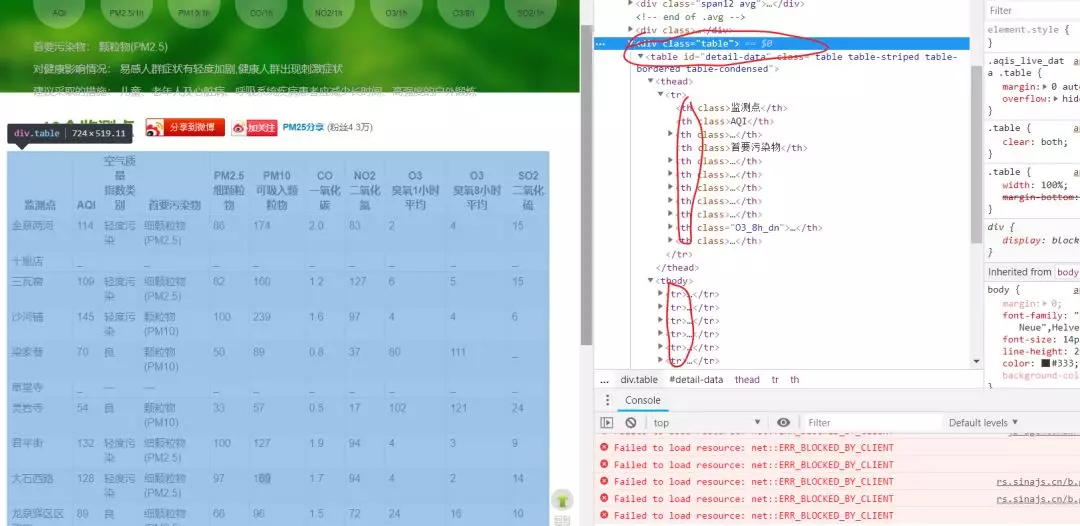
下面我们同时提取10个大城市的表格。
1library(rvest)
2library(magrittr)
3
4city_name <- c("beijing", "shanghai", "guangzhou", "shenzhen", "hangzhou",
5 "tianjin", "chengdu", "nanjing", "xian", "wuhan")
6url_cites <- paste0("http://www.pm25.in/", city_name)
7
8for (n in 1:length(city_name)) {
9
10 # 提取表格
11 pm_city <- read_html(x = url_cites[n]) %>%
12 html_nodes(css = ".aqis_live_data .container .table") %>%
13 .[[2]] %>% # 注意这里的点
14 html_table()
15
16 # 批量生成变量
17 assign(x = paste0("pm_", city_name[n]), value = pm_city)
18
19}
20rm(url_cites, pm_city)
21
22DT::datatable(pm_chengdu)
23DT::datatable(pm_beijing)

(截屏预览不全)
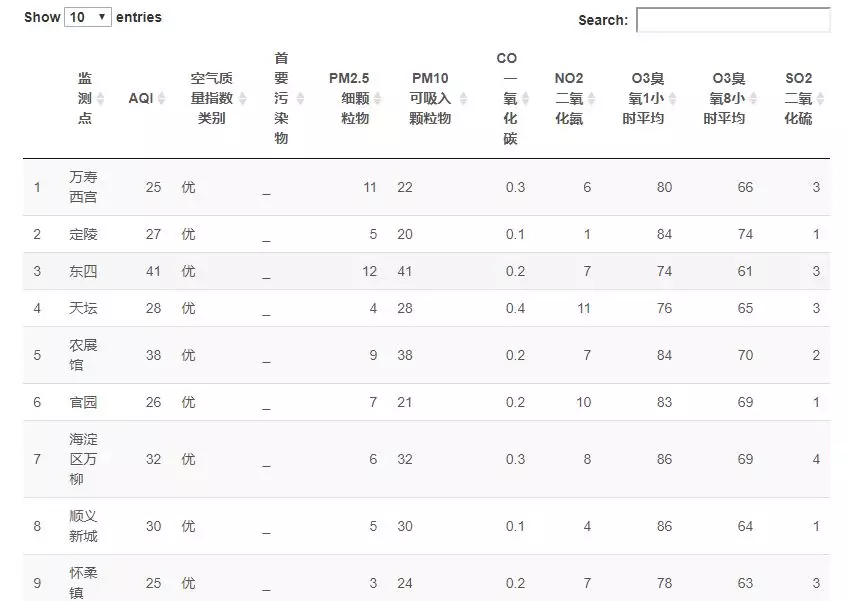
(截屏预览不全)
4.图片提取
这里我们打开 觅元素
(http://www.51yuansu.com/),在搜索框中输入“花”,在分类中选择“动植物元素”。
可以发现url跳转到
http://www.51yuansu.com/search/hua-40-0-0-0-1/。
同样使用SelectorGadget审查元素,发现图片都有类:.img-wrap .lazy。
我们点击一张图片,发现跳转到另一个url,将这个url复制,在审查元素中搜索,
可以发现该url类为img-wrap或i-title-wrap。
1rm(list = ls()); gc() # 清空内存
2library(rvest)
3library(stringr)
4
5# 提取nodes
6url_first <- "http://www.51yuansu.com/search/hua-40-0-0-0-1/"
7flower_nodes <- read_html(x = url_first) %>%
8 html_nodes(css = ".img-wrap")
9
10# 查看字符串,以使用正则表达式
11flower_nodes[[1]]
1## used (Mb) gc trigger (Mb) max used (Mb)
2## Ncells 717036 38.3 1197920 64 1197920 64
3## Vcells 1356245 10.4 8388608 64 2616152 20
4## {xml_node}
5## <a class="img-wrap" href="http://www.51yuansu.com/sc/cvctvrhmhh.html" target="_blank">
6## [1] <img class="lazy" src="https://icon.51yuansu.com/component/base/img/ ...
正则表达式匹配,^(http) (.html)$这种形式只能在一行内匹配,不能匹配多行字符串。
1library(rvest)
2library(stringr)
3library(magrittr)
4library(rlist)
5
6flower_nodes %<>%
7 str_extract_all(pattern = "http.*\\.html") %>% # .*表示任何字符串,以http开头,.html结束
8 unlist()
9
10flower_nodes[1]
1## [1] "http://www.51yuansu.com/sc/cvctvrhmhh.html"
提取图片的url链接
1library(rvest)
2library(stringr)
3
4image_url <- vector() # 生成空向量
5
6for (n in 1:length(flower_nodes)) {
7 image_url[n] <- read_html(x = flower_nodes[n]) %>%
8 html_nodes(css = ".img-wrap .show-image") %>%
9 str_extract_all(pattern = "http.*\\.jpg") %>%
10 unlist()
11
12}
13
14image_url[1]
1## [1] "http://pic.51yuansu.com/pic3/cover/02/00/29/5984a5c877c73_610.jpg"
读取url图片并保存
1library(magick)
2
3file_path <- "E:/R_input_output/images_output/scrapt_collection/"
4
5for (n in 1:length(image_url)) {
6 image_read(path = image_url[n]) %>% # 读取url图片
7 image_write(path = paste0(file_path, n, ".jpg")) # 保存图片
8}
9
10# 动画展示保存到文件夹中的图片
11image_animate(image =
12 image_read(path = paste0(file_path, as.character(1:length(image_url)), ".jpg")))

(原为动图)
5.模拟对话
函数:
html_session(),jump_to(),follow_link(),back(),forward(),submit_form(),
可以用来模拟网上浏览行为,这里我们使用豆瓣网来模拟。
使用html_session()来创建会话。
1rm(list = ls()); gc() # 清空内存
2library(rvest)
3library(magrittr)
4
5u <- "https://movie.douban.com/"
6session <- html_session(u) # 创建会话
什么是表单? HTML 中的表单被用来搜集用户的不同类型的输入。
例如,登录表单、搜索框表单等。
HTML 表单包含表单元素,表单元素是指不同类型的 input元素、复选框(box)、
单选(radio)、提交按钮(submit)等。
穿越表单分为以下3步:
提取出你所需要的表单:
html_form()填写你的表单:
set_values(form, name1=value1, name2=value2)提交表单,发送给服务器:
submit_form(session, form)
1library(rvest)
2
3forms <- session %>% html_form()
4forms

1library(rvest)
2form <- forms[[1]] # forms 中的第一个列表是我们的目标列表
3form

在上面的结果中,只有 ‘search_text’ :的冒号后为空,
这表明 ‘search_text’ 还没有填充任何值,而我们的填充任务就是把它填上。
比如说我要搜索“流浪地球”,
那么我就在set_values() 中指定一个 search_text参数,令它的值为“流浪地球”。
那么,现在我们的表单已经填充好了,只需要把它提交给服务器了。
1library(rvest)
2
3filled_form <- set_values(form, search_text = "流浪地球") # 填写表单
4session2 <- submit_form(session, form = filled_form) # 提交表单
5
6session2$url # 查看提交表单后,返回的新会话 session2 的 url
7iconv(URLdecode(session2$url), "UTF8") # 重新编码

6.项目
这里我们准备爬流浪地球豆瓣评论,然后分词并绘制词云图。
6.1
爬流浪地球豆瓣评论
首先打开 流浪地球评论web,
https://movie.douban.com/subject/26266893/comments?sort=new_score&status=P
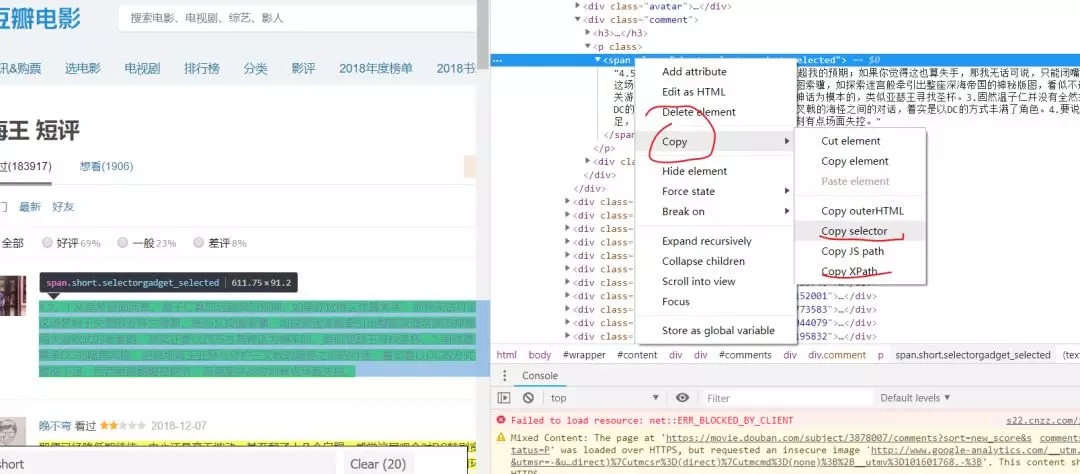
因为豆瓣网页元素层数比较多,所以必须使用SelecorGadget, 审查元素后,右击进行复制,
通常可以选择selector或xpath,如图所示:
1rm(list = ls()); gc() # 清空内存
2library(rvest)
3
4url_movie <- "https://movie.douban.com/subject/26266893/comments?sort=new_score&status=P"
5
6path_comments <- paste0("#comments > div:nth-child(",
7 as.character(1:20),
8 ") > div.comment > p > span")
9
10text_comments <- vector() # 创建空向量
11# 爬取第一页的评论
12for (n in 1:20) { # 1页20个评论
13 comments_n <- read_html(x = url_movie) %>%
14 html_nodes(css = path_comments[n]) %>%
15 html_text() %>%
16 unlist()
17
18 text_comments[n] <- comments_n
19}
20
21print(text_comments[1])

爬取所有页,
通过手动点击下一页,发现页面url的规律,那就是start=n, n步长为20,初始值为20。
通过二分法找到最后一个页面,发现未登陆时仅可访问前220条评论。
下面是爬取第20条到第220条评论。
1library(rvest)
2url_pages <- paste0("https://movie.douban.com/subject/26266893/comments?start=",
3 as.character(seq(from = 20, to = 200, by = 20)),
4 "&limit=20&sort=new_score&status=P&percent_type=")
5for (m in 1:length(url_pages)) {
6
7 for (n in 1:20) { # 1页20个评论
8 comments_mn <- read_html(x = url_pages[m]) %>%
9 html_nodes(css = path_comments[n]) %>%
10 html_text() %>%
11 unlist()
12
13 text_comments[m*20 + n] <- comments_mn
14 }
15 Sys.sleep(20) # 延迟时间20秒,避免豆瓣IP异常
16 }
17
18
19# 保存为txt文件
20write.table(x = text_comments,
21 file = "E:/R_input_output/data_output/流浪地球-豆瓣评论.txt",
22 quote = FALSE, sep = "\n", row.names = TRUE,
23 qmethod = "double", fileEncoding = "UTF-8")
爬其它电影评论也是一样的,只需要改id号,和保存文件名。
6.2
分词并计算词频
中文分词采用专门的包jiebaR,更详细的资料可以看文末的参考来源。
1rm(list = ls()); gc() # 清空内存
2library(jiebaR)
3library(dplyr)
4library(readr)
5library(magrittr)
6
7# 读取要分词的文本
8text_comments <- readLines(con = "E:/R_input_output/data_output/流浪地球-豆瓣评论.txt",
9 encoding = "UTF-8")
10
11# 分词
12## 导入停止词
13setwd("E:/R_input_output/data_input/jiebaR_documents")
14wk <- worker(stop_word = "sea.txt")
15split_1 <- segment(text_comments, wk)
16split_combined <- sapply(split_1, function(x) {paste(x, collapse = " ")}) # 空格分割
17
18# 计算词频
19comments_freq <- freq(split_combined)
20## 去除数字
21comments_freq <- comments_freq[!grepl(pattern = "^\\d$", comments_freq$char),] # 逻辑索引
22## 排序并取前300个
23comments_freq %<>% arrange(desc(freq)) %>% .[1:300, ]
6.3
词云图
安装方式:
devtools::install_github("lchiffon/wordcloud2")。
目前wordcloud2()绘制的图自动保存比较困难,还是截图吧。
1library(wordcloud2)
2
3letterCloud(comments_freq, word = "6", wordSize = 4, color="red")

1wordcloud2(comments_freq,
2 color = "random-light", size = 1, shape='star')

下面是用同样的方式,爬海王豆瓣评论的词云图:


参
考来源
rvest易上手爬虫
https://cran.r-project.org/web/packages/httr/vignettes/api-packages.html
datacamp rvest爬虫教程
https://www.datacamp.com/community/tutorials/r-web-scraping-rvest
R爬虫小白实例教程 - 基于rvest包
R语言:rvest包学习爬虫–笔记
github地址
rvest穿越表单
rvest爬虫教程
正则表达式
http://yphuang.github.io/blog/2016/03/15/regular-expression-and-strings-processing-in-R/
rvest抓取图片
jump_to()与follow_link()
follow_link的使用
批量生成变量
xpath语法
Sys.sleep
推迟时间
Wordcloud2 introduction
https://cran.r-project.org/web/packages/wordcloud2/vignettes/wordcloud.html
R语言中文分词包jiebaR
R学习整理笔记(五)——用jiebaR包进行中文分词
分词 | jiebaR 常用函数
jiebaR 中文分词文档
jiebaR github
——————————————
往期精彩:
 天善智能每日一道算法题,打卡学习
天善智能每日一道算法题,打卡学习 小程序
小程序
