SPL的特征之一是数据有序,适当地利用位置,可以显著提高性能。让我们先从一个典型场景开始,逐步掌握利用位置的各种技巧。
快速查询
对排序后的数据进行二分查找,可以获得较高的性能,但有些算法需用到原始顺序,看上去似乎不该再排序。比如下面的案例:
PerformanceRanking.txt有三个字段,分别是empID(销售员编号)、dep(部门名称)、amount(销售额)。该文件记录着各部门各销售员本季度的业绩排名,已按销售额逆序存放,现在需根据指定的销售员ID,计算出:他应当再增加多少销售额,才能提高业绩排名。如果该员工已经是第1名,则无需增加销售额。
本算法需要用排名高一位的销售员的销售额,减去该销售员的销售额,即对原始数据做相对位置计算。既然要用到原始顺序,似乎就不该再排序,否则两者难以互转,而且其他算法可能用到原始数据。这种思路下会把脚本写成这样:

上述脚本没有对数据排序,所以不能进行二分查找,性能不高。
事实上,我们可以在保留原始数据的前提下,利用位置进行排序,从而提高查询性能。脚本如下:

A5:函数psort只获得排序后记录在原数据中的位置,并不会对原数据真正排序。
A6:利用oPos制造一份排序后的数据。注意,此时原数据不受影响,而且oPos可以作为排序后数据index和原始数据之间互转的桥梁。
A7:对排序后的数据做二分查找,并转回原始数据中对应的记录序号。
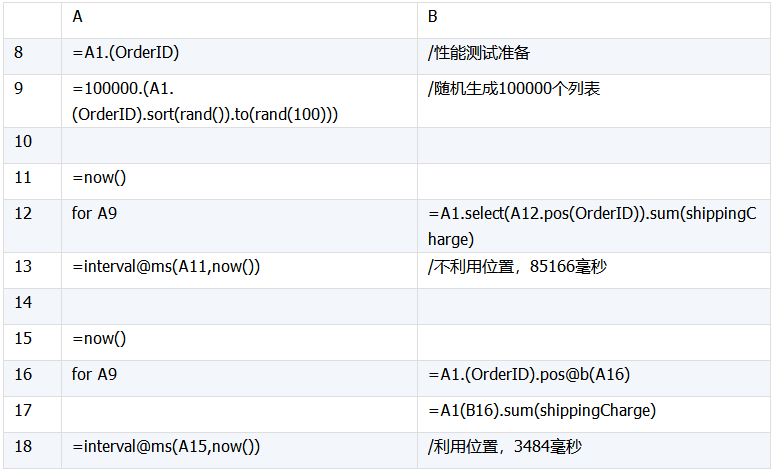
为了验证利用位置之前、之后两种算法的性能差别,可以随机取出销售员编号做参数,用循环模拟大量访问,并分别执行两种算法。如下:

可以看到,利用位置后性能提高几十倍。例子中数据量较少,随着数据量的增加,性能差距会急剧拉大,这是因为遍历查找的时间复杂度为线性,而二分查找为对数。
快速对齐
函数align可将数据按序列对齐,比如输入条件:=pOrderList= [10250,10247,10248,10249,10251],将订单明细按该列表对齐,求每个订单的金额小计。代码如下:

但上述写法没有利用位置,性能因此不高。要想提高性能,可以将序列排序(手工建立索引表),再用二分法对齐,最后恢复为原顺序,代码如下:

A2-A3:手工建立索引表。
A4:将订单明细表与订单列表对齐,求出金额小计。由于索引表有序,因此可用二分法对齐,即@b选项。
A5:将A4按原位置调整,与pOrderList的顺序保持一致。函数inv可按指定位置调整成员,这里按原位置调整成员,相当于恢复成原位置。
对利用位置前后的两种算法,模拟大访问量测试,可以看到性能提升显著:

有序数据批量查询
有时要对有序数据进行批量查询,比如pOrderList=[10877,10588,10611,11037,10685],请统计符合该列表的订单的运货费合计,代码可以这样写:
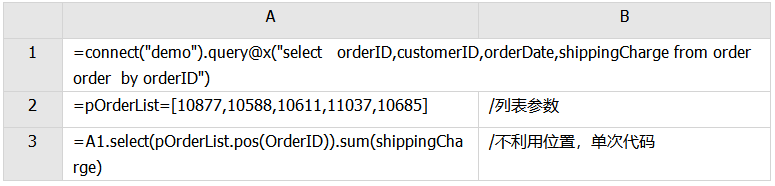
解释:函数pos和select配合,可实现批量查询。其中函数pos可返回某个值在序列中的位置,如该值不在序列中,则返回null。函数select用于查询,当条件非null且非false时,可返回当前记录。
但上述代码没有利用位置,所以性能不高。
应当注意到,订单记录是有序的,所以可以用二分法取得符合条件的订单位置,再用位置取记录并计算。具体代码如下:

A1.(orderID)可取得orderID列,pos@b可针对有序数据,用二分法快速取得成员位置。A6按位置取数据。
对利用位置前后的两种算法,模拟大访问量测试,可以看到性能提升显著: