
作者:Ahab
个人公众号:Ahab杂货铺
前言
上次对租金预测比赛进行的是数据分析部分的处理机器学习实战--住房月租金预测(1),今天继续分享这次比赛的收获。本文会讲解对特征工程的处理。话不多说,我们开始吧!
特征工程
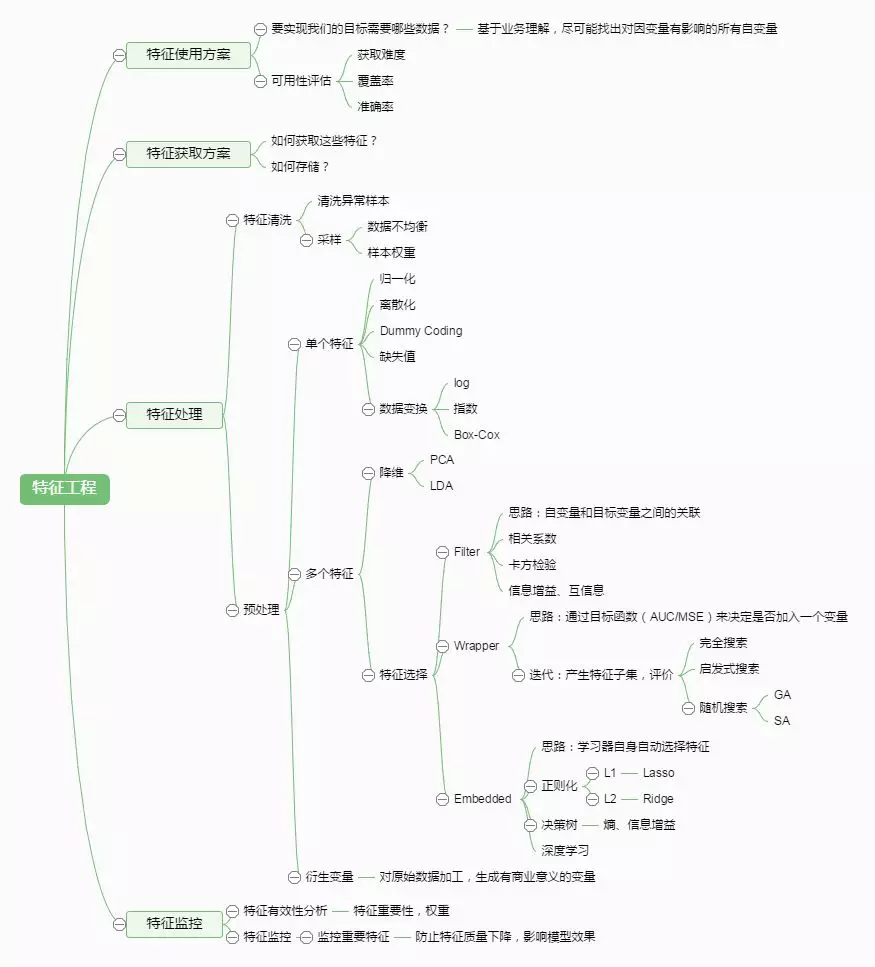
“数据决定了机器学习的上限,而算法只是尽可能逼近这个上限”,这里的数据指的就是经过特征工程得到的数据。特征工程指的是把原始数据转变为模型的训练数据的过程,它的目的就是获取更好的训练数据特征,使得机器学习模型逼近这个上限。特征工程能使得模型的性能得到提升,有时甚至在简单的模型上也能取得不错的效果。特征工程在机器学习中占有非常重要的作用,上面的思维导图包含了针对特征工程处理的所有方法。
缺失值处理
1print(all_data.isnull().sum())
使用上面的语句可以查看数据集中的缺失值

从上面的图中可以清楚的看到各数据的缺失值。
对于缺失值是任何一个数据集都不可避免的,在数据统计过程中可能是无意的信息被遗漏,比如由于工作人员的疏忽,忘记而缺失;或者由于数据采集器等故障等原因造成的缺失,或者是有意的有些数据集在特征描述中会规定将缺失值也作为一种特征值,再或者是不存在的,有些特征属性根本就是不存在的。
缺失值的处理,我们常用的方法有:删除记录:对于样本数据量较大且缺失值不多同时正相关性不大的情况下是有效。可以使用 pandas 的 dropna 来直接删除有缺失值的特征。数据填充:数据填充一般采用均值,中位数和中数,当然还有其他的方法比如热卡填补(Hot deck imputation),K最近距离邻法(K-means clustering)等。不作处理:因为一些模型本身就可以应对具有缺失值的数据,此时无需对数据进行处理,比如Xgboost,rfr等高级模型,所以我们可以暂时不作处理。
对于这次比赛缺失值的处理主要是数据的填充 。
1cols=["renovated", "living_status","subway_distance" , "subway_station", "subway_line"]
2for col in cols:
3 kc_train[col].fillna(0, inplace=True)
4 kc_test[col].fillna(0, inplace=True)
5
6kc_train["way_rent"].fillna(2, inplace=True)
7kc_test["way_rent"].fillna(2, inplace=True)
8kc_train["area"].fillna(8, inplace=True)
9kc_train = kc_train.fillna(kc_train.mean())
10kc_test["area"].fillna(8, inplace=True)
11kc_test = kc_test.fillna(kc_test.mean())
对于装修状态,居住状态,距离,地铁站点和线路均用0填充,区均用中位数8来填充,出租方式用2填充,同时做了一个判断
1kc_train['is_living_status'] = kc_train['living_status'].apply(lambda x: 1 if x > 0 else 0)
2kc_train['is_subway'] = kc_train['subway_distance'].apply(lambda x: 1 if x > 0 else 0)
3kc_train['is_renovated'] = kc_train['renovated'].apply(lambda x: 1 if x > 0 else 0)
4kc_train['is_rent'] = kc_train['way_rent'].apply(lambda x: 1 if x < 2 else 0)
5
6kc_test['is_living_status'] = kc_test['living_status'].apply(lambda x: 1 if x > 0 else 0)
7kc_test['is_subway'] = kc_test['subway_distance'].apply(lambda x: 1 if x > 0 else 0)
8kc_test['is_renovated'] = kc_test['renovated'].apply(lambda x: 1 if x > 0 else 0)
9kc_test['is_rent'] = kc_test['way_rent'].apply(lambda x: 1 if x < 2 else 0)
异常值处理
异常值是分析师和数据科学家常用的术语,因为它需要密切注意,否则可能导致错误的估计。 简单来说,异常值是一个观察值,远远超出了样本中的整体模式。
什么会引起异常值呢?
主要有两个原因:人为错误和自然错误
如何判别异常值?
正态分布图,箱装图或者离散图。以正态分布图为例:符合正态分布时,根据正态分布的定义可知,距离平均值3δ之外的概率为 P(|x-μ|>3δ) <= 0.003 ,这属于极小概率事件,在默认情况下我们可以认定,距离超过平均值3δ的样本是不存在的。 因此,当样本距离平均值大于3δ,则认定该样本为异常值。当数据不服从正态分布:当数据不服从正态分布,可以通过远离平均距离多少倍的标准差来判定,多少倍的取值需要根据经验和实际情况来决定。
异常值的处理方法常用有四种:
1.删除含有异常值的记录
2.将异常值视为缺失值,交给缺失值处理方法来处理
3.用平均值来修正
4.不处理
1all_data = pd.concat([train, test], axis = 0, ignore_index= True)
2all_data.drop(labels = ["price"],axis = 1, inplace = True)
3fig = plt.figure(figsize=(12,5))
4ax1 = fig.add_subplot(121)
5ax2 = fig.add_subplot(122)
6g1 = sns.distplot(train['price'],hist = True,label='skewness:{:.2f}'.format(train['price'].skew()),ax = ax1)
7g1.legend()
8g1.set(xlabel = 'Price')
9g2 = sns.distplot(np.log1p(train['price']),hist = True,label='skewness:{:.2f}'.format(np.log1p(train['price']).skew()),ax=ax2)
10g2.legend()
11g2.set(xlabel = 'log(Price+1)')
12plt.show()
查看训练集的房价分布,左图是原始房价分布,右图是将房价对数化之后的。
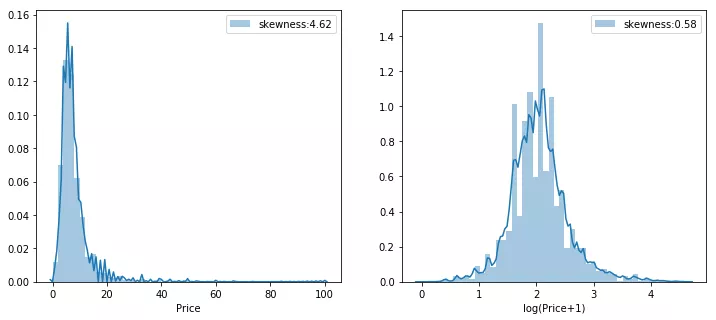
由于房价是有偏度的,将房价对数化并且将有偏的数值特征对数化
1train['price'] = np.log1p(train['price'])
2
3# 将有偏的数值特征对数化
4num_features_list = list(all_data.dtypes[all_data.dtypes != "object"].index)
5
6for i in num_features_list:
7 if all_data[i].dropna().skew() > 0.75:
8 all_data[i] = np.log1p(all_data[i])
根据上一篇我们筛选出的十个最相关的特征值,画出离散图,并且对离散点做处理,这里只取房屋面积举个栗子。
1var = 'sqft_living'
2data = pd.concat([train['price'], train[var]], axis=1)
3data.plot.scatter(x=var, y='price', ylim=(0,150));
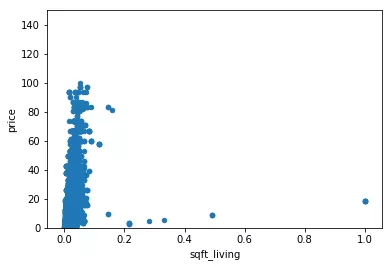
1train.drop(train[(train["sqft_living"]>0.125)&(train["price"]<20)].index,inplace=True)
这里将面积大于0.125且价格小于20的点全部删除。
对于特征工程的处理这是在自己代码中最重要的两步--缺失值和异常值的处理,将类别数值转化为虚拟变量和归一化的处理效果不是特别好所以没有贴上,数据集中的房屋朝向可以采用独热编码,感兴趣的可以试一下,我一直没搞懂看了同学的处理他的代码量太大,效果也不是特别明显,自己索性没去研究。下一次更新将针对这个问题进行模型选择。

推荐阅读:
由椰树椰汁广告想到,关于美女营销
【3分钟速读】运营到底是干啥的?
TensorFlow 2.0 Alpha 版发布啦!快来尝鲜!
公众号后台回复关键词学习
回复 免费 获取免费课程
回复 直播 获取系列直播课
回复 Python 1小时破冰入门Python
回复 人工智能 从零入门人工智能
回复 深度学习 手把手教你用Python深度学习
回复 机器学习 小白学数据挖掘与机器学习
回复 贝叶斯算法 贝叶斯与新闻分类实战
回复 数据分析师 数据分析师八大能力培养
回复 自然语言处理 自然语言处理之AI深度学习

