【摘要】
排序计算是一个非常消耗资源的操作,特别是对于大数据排序,如果内存无法装下数据,常规的做法就需要借助外存,不过因此也会增加对数据的读写操作,而读写操作通常又会比排序操作更消耗资源。
让我们一起去乾学院看个究竟吧:SPL 排序优化技巧
本文介绍的SPL排序优化技巧,除了提供常规的排序算法外,还根据不同场景下的数据特性提供了排序的替代算法,从而减少比较次数和IO量,提升运算性能。
1.内存排序
当数据可以轻松装入内存时,可以使用SPL的内存排序函数,如A.sort()。SPL默认的排序算法是基于merge sort的多线程排序算法,也就是说,此时的优化方式主要是通过增加线程数量实现的。实际采用的线程数由集算器配置中的[最大并行数]指定。示例代码如下:
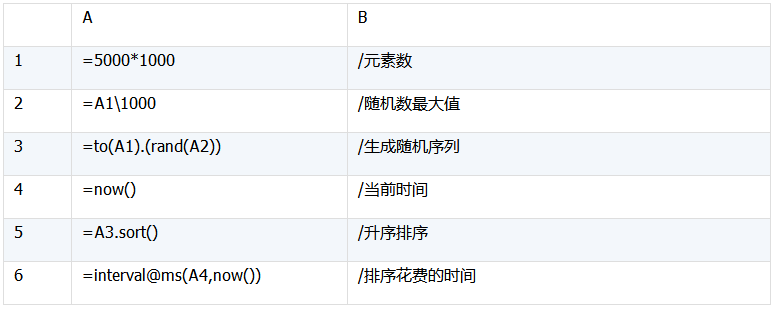
实测使用的的测试机CPU是酷睿i7 ,4核心 8线程,根据 [最大并行数]配置的不同,测试结果如下:
最大并行数 平均花费时间(毫秒)
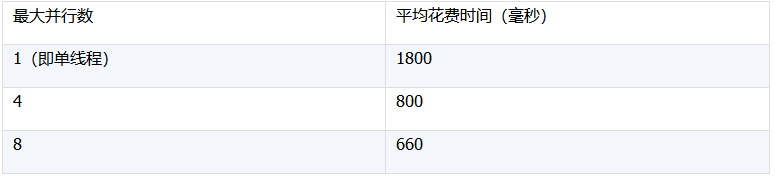
可见,多核心CPU或多CPU计算机通过多线程排序可以充分利用每个核心的并行计算能力,显著提升排序性能。
此例中每个值的重复量平均为1000,对A.sort()函数来说,重复数量的多少对性能影响不大。但在重复数量较多时,我们还可以通过分组法A.group@s()进行排序,进一步提高性能。此方法首先利用哈希法对元素进行分组,然后再对组进行排序,最后合并排序后的组得到排序结果。示例代码如下:
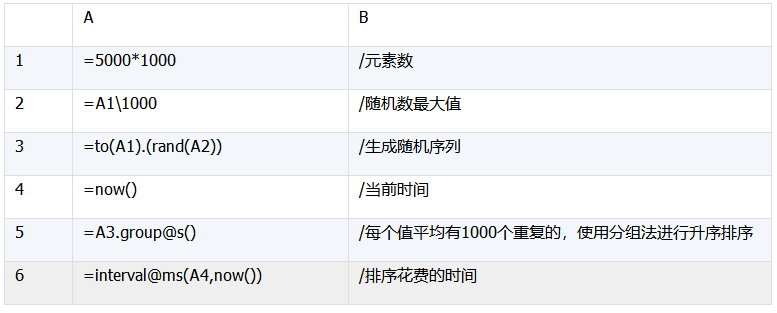
使用分组法排序后,平均花费时间为360毫秒,可见,此方法适合重复数量较多的数据,重复数量越多性能越好。
2.外存排序
当数据量大到无法装入内存时就需要借助外存进行排序。外存排序会分步读入数据,排序后写出到临时文件,最后对所有生成的临时文件归并得到最终结果。
临时文件的数量会影响排序的效率,如果数量过多,归并阶段会占用更多的资源,而归并路数过多也会影响归并效率。所以每次读入较多的数据量可以提升sortx的性能。
SPL外存排序的函数是cs.sortx(),排序中生成的临时文件数量由原始数据量和每次读入的数据量决定,而每次读入的数据量可以通过sortx函数的参数指定。用户可以根据记录大小和空闲内存容量指定一个合理的每次读入数据量以达到最优的性能。如果没有指定,SPL会根据虚拟机可用内存估算出一个大概值。
临时文件的释放会在结果游标取数结束或者close方法被调用时触发。
测试外存排序需要大数据量,而由于使用JDBC从数据库取数的效率非常差,因此本文将采用效率更好的集文件进行测试。
测试数据模拟订单数据,表结构为{ order_id ,order_datetime , customer_id, employee_id , product_id , quantity ,price},按order_id 、order_datetime有序,随机生成2000万条记录。
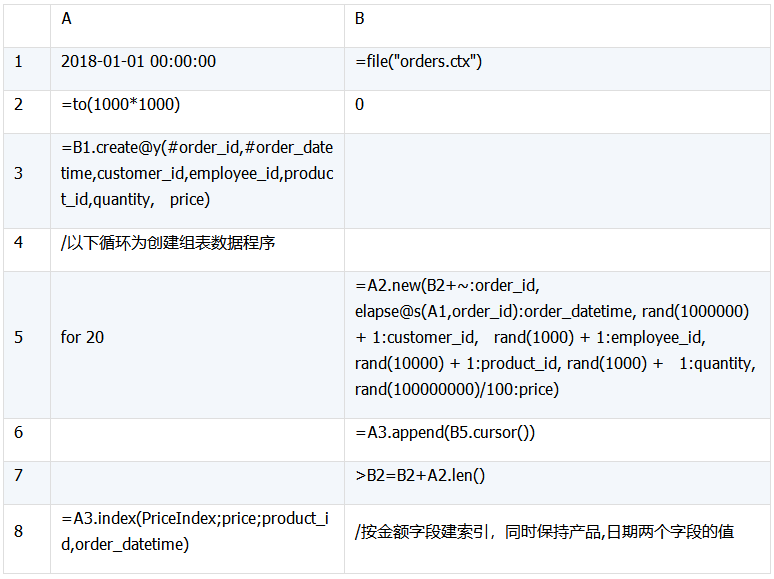
测试数据的生成也使用SPL,造数代码如下:
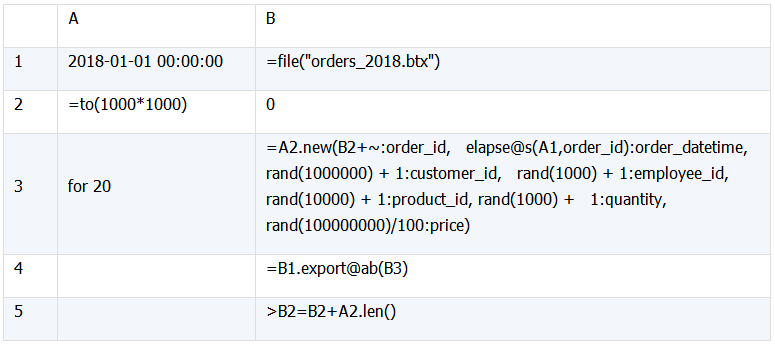
排序计算的代码如下:
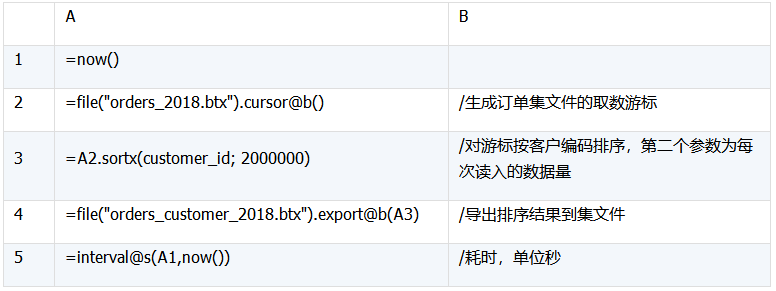
测试结果如下:

3.多路归并
使用SPL处理大数据运算时,为了获取更好的性能通常会把数据外置成集文件或组表,同时按照常用的过滤维度排序以获得更高的过滤性能。这样,如果有新的数据要追加到历史文件,并需要对所有数据重新排序,我们就可以利用集文件或者组表的这个特点了。由于历史数据已经有序,此时我们可以先把新数据按照维度排序,然后再和历史数据进行归并就可以得到最终的有序数据了。使用这个方法排序涉及的数据量远小于对所有数据进行大排序的数据量。具体的测试如下:
在前面外存排序的造数代码中,将A1格改为2017-01-01 00:00:00,B1格改为=file("orders_2017.btx"),生成模拟2017年的订单数据文件“orders_2017.btx”。然后使用外存排序代码按customer_id字段排序,生成排序结果文件“orders_2017_customer.btx”。
然后,我们需要将2017、2018两年的所有数据进行整体排序,也就是使用归并方法合并orders_2017_customer.btx、orders_2018_customer.btx两个文件成一个新的有序文件。示例代码如下:

前6行代码采用了归并方法,耗时30秒,而后5行代码模拟了简单的大排序方法,耗时133秒。
4.前半有序
如果需要按照多个字段对数据进行排序,而数据已经按照排序字段中的几个字段有序了,则可以按照已经有序的字段分组读入数据,在内存排序后输出。这种处理方法比cs.sortx()少了一遍读写操作,因此性能大幅优于cs.sortx()。
例如订单表的数据是按照日期时间有序生成的,如果想按照日期、客户两个字段对订单表进行排序则可以使用这个方法。示例代码如下:

经测试耗时为38秒(A6格的值),而如果把A4格表达式替换为下面代码则耗时95秒。

5.索引排序
SPL的组表提供了为某些列创建索引的功能,一些常用的列也可以存到索引里,这样如果访问的列都在索引里就不需要再访问整个源文件,从而节省大量IO操作。而如果排序字段是索引字段,并且需要访问的字段也都在索引里,则可以利用索引的有序性,使用T.icursor@s()返回有序游标。
创建索引的代码如下:
利用索引产生有序游标代码如下:

经测试有序游标耗时为4秒(B4格的值),而外存排序遍历耗时为54秒(B8格的值)。
