
平台上一条查询功能一直不能显示数据,后来通过抓取发现一条sql 查询很慢,由于是生产库不能随便创建索引,只能在sql语句上下功夫。同时权限不足,只能通过pl/sql上的F5进行查看执行计划。Oracle版本是10.2 。略坑…
Oracle优化效果:从494秒到5秒
原始代码
SELECT county,
SP_ID,
SP_NAME,
NAME,
DES_PAYORG_ID,
COUNT(*),
SUM(TRADE_MONEY / 100) FEE,
OPT_CODE,
DEPART_NAME
FROM (SELECT PARAMCONVER('county', K.code) county,
DE.DEPART_NAME,
T.SP_ID,
K.SP_NAME,
M.NAME,
PARAMCONVER('des_payorg_id', T.DES_PAYORG_ID) DES_PAYORG_ID,
T.TRADE_MONEY,
PARAMCONVER('opt_code', T.OPT_CODE) OPT_CODE
FROM (SELECT T.AP_ID,
T.ABILITY_TYPE,
T.SP_ID,
T.SERVICE_ID,
T.TRADE_MONEY,
T.OPT_CODE,
T.DES_PAYORG_ID,
AD.SETTLEMENT_DATE START_TIME,
T.AREA_CODE
FROM TRADE_HISTORY T, ADJUST_AMOUNT AD
WHERE T.TRADE_SEQ_ID = AD.TRADE_SEQ_ID
AND T.RESULT = '0'
AND AD.MODIFY_TYPE = '4'
AND T.DES_PAYORG_ID IN ('DX03', 'DX04', 'DX05')
AND T.TRADE_MONEY != '0'
AND T.ABILITY_TYPE IN ('0101', '0102')
AND T.START_TIME >= to_date('2015-11-01', 'YYYY-MM-DD')
AND T.START_TIME < to_date('2015-11-30', 'YYYY-MM-DD') + 1
UNION ALL
SELECT T.AP_ID,
T.ABILITY_TYPE,
T.SP_ID,
T.SERVICE_ID,
T.TRADE_MONEY,
T.OPT_CODE,
T.DES_PAYORG_ID,
T.START_TIME,
T.AREA_CODE
FROM TRADE_HISTORY T
WHERE T.RESULT = '0'
AND T.DES_PAYORG_ID IN ('DX03', 'DX04', 'DX05')
AND T.TRADE_MONEY != '0'
AND T.ABILITY_TYPE IN ('0101', '0102')
AND NOT EXISTS
(SELECT 1
FROM ADJUST_AMOUNT AD
WHERE AD.MODIFY_TYPE = '4'
AND AD.TRADE_SEQ_ID = T.TRADE_SEQ_ID)
AND T.START_TIME >= to_date('2015-11-01', 'YYYY-MM-DD')
AND T.START_TIME < to_date('2015-11-30', 'YYYY-MM-DD') + 1) T,
(select quxiantodishi(s.city_code) code,
sp_id,
sp_name,
s.depart_id
from sp_info s) K,
AP_INFO M,
DEPARTMENT_INFO DE
WHERE T.SP_ID = K.SP_ID
AND M.AP_ID = T.AP_ID
AND K.DEPART_ID = DE.DEPART_ID
AND T.DES_PAYORG_ID IN ('DX03', 'DX04', 'DX05'))
GROUP BY county,
DEPART_NAME,
SP_ID,
SP_NAME,
NAME,
DES_PAYORG_ID,
OPT_CODE
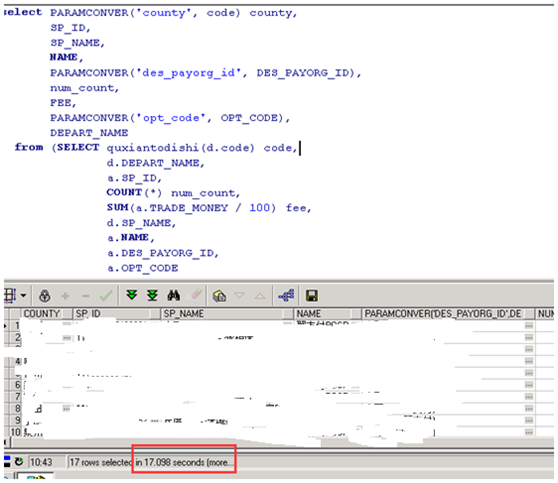
执行计划
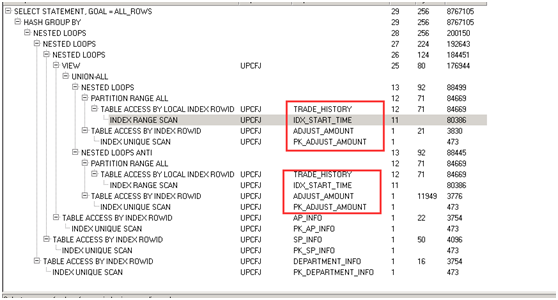
执行时长:494秒
第一次优化:观察代码,代码中用了一个union all,但是这个union all中扫描两次相同的表,因此针对union all 进行代码改写,降低表的扫描次数,改写后的代码如下:
第一次优化后代码
SELECT county,
SP_ID,
SP_NAME,
NAME,
DES_PAYORG_ID,
COUNT(*),
SUM(TRADE_MONEY / 100) FEE,
OPT_CODE,
DEPART_NAME
FROM (SELECT PARAMCONVER('county', K.code) county,
DE.DEPART_NAME,
T.SP_ID,
K.SP_NAME,
M.NAME,
PARAMCONVER('des_payorg_id', T.DES_PAYORG_ID) DES_PAYORG_ID,
T.TRADE_MONEY,
PARAMCONVER('opt_code', T.OPT_CODE) OPT_CODE
FROM (SELECT T.AP_ID,
T.ABILITY_TYPE,
T.SP_ID,
T.SERVICE_ID,
T.TRADE_MONEY,
T.OPT_CODE,
T.DES_PAYORG_ID,
case
when AD.SETTLEMENT_DATE is not null then
AD.SETTLEMENT_DATE
else
T.START_TIME
end start_time,
T.AREA_CODE
FROM TRADE_HISTORY T
left join (select *
from ADJUST_AMOUNT AD
where AD.MODIFY_TYPE = '4') ad
on AD.TRADE_SEQ_ID = T.TRADE_SEQ_ID
WHERE T.RESULT = '0'
AND T.DES_PAYORG_ID IN ('DX03', 'DX04', 'DX05')
AND T.TRADE_MONEY != '0'
AND T.ABILITY_TYPE IN ('0101', '0102')
AND T.START_TIME >= to_date('2015-11-01', 'YYYY-MM-DD')
AND T.START_TIME < to_date('2015-11-30', 'YYYY-MM-DD') + 1) T,
(select quxiantodishi(s.city_code) code,
sp_id,
sp_name,
s.depart_id
from sp_info s) K,
AP_INFO M,
DEPARTMENT_INFO DE
WHERE T.SP_ID = K.SP_ID
AND M.AP_ID = T.AP_ID
AND K.DEPART_ID = DE.DEPART_ID
AND T.DES_PAYORG_ID IN ('DX03', 'DX04', 'DX05'))
GROUP BY county,
DEPART_NAME,
SP_ID,
SP_NAME,
NAME,
DES_PAYORG_ID,
OPT_CODE
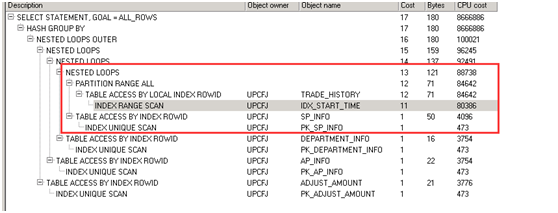
第一次优化后执行计划
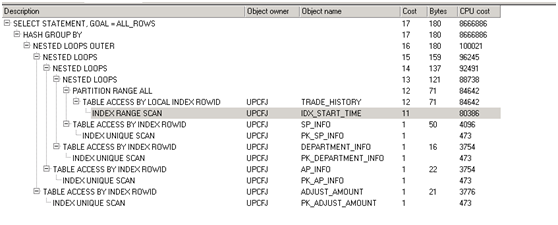
第一次优化后执行时长:479秒
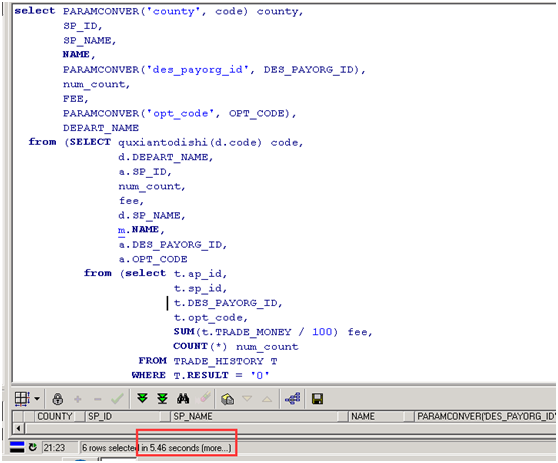
第二次优化:代码改写几乎没有效果,没有抓住重点,原来是大表(trade_history)进行了索引范围扫描而不是全表扫描,没必要优化,成效不明显。其中trade_history 筛选后的数据量为100万条。再次观察代码,发现trade_history 筛选完以后,针对opt_code字段进行了函数转换,函数为PARAMCONVER。 100万条数据也就是每一条数据都进行了一次函数转换;city_code 字段也进行了函数转换,函数quxiantodishi。再次优化代码,降低函数的使用次数,优化后代码如下
第二次优化后代码
select PARAMCONVER('county', code) county,
SP_ID,
SP_NAME,
NAME,
PARAMCONVER('des_payorg_id', DES_PAYORG_ID),
num_count,
FEE,
PARAMCONVER('opt_code', OPT_CODE),
DEPART_NAME
from (SELECT quxiantodishi(d.code) code,
d.DEPART_NAME,
a.SP_ID,
COUNT(*) num_count,
SUM(a.TRADE_MONEY / 100) fee,
d.SP_NAME,
a.NAME,
a.DES_PAYORG_ID,
a.OPT_CODE
from (select
t.*, m.name
from (SELECT T.AP_ID,
T.ABILITY_TYPE,
T.SP_ID,
T.SERVICE_ID,
T.TRADE_MONEY,
T.OPT_CODE,
T.DES_PAYORG_ID,
case
when AD.SETTLEMENT_DATE is not null then
AD.SETTLEMENT_DATE
else
T.START_TIME
end start_time,
T.AREA_CODE
FROM TRADE_HISTORY T
left join (select ad.trade_seq_id, ad.settlement_date
from ADJUST_AMOUNT AD
where AD.MODIFY_TYPE = '4') ad on AD.TRADE_SEQ_ID =
t.trade_seq_id
WHERE T.RESULT = '0'
AND T.DES_PAYORG_ID IN ('DX03', 'DX04', 'DX05')
AND T.TRADE_MONEY != '0'
AND T.ABILITY_TYPE IN ('0101', '0102')
AND T.START_TIME >=
to_date('2015-11-01', 'YYYY-MM-DD')
AND T.START_TIME <
to_date('2015-11-30', 'YYYY-MM-DD') + 1) t,
AP_INFO M
where t.ap_id = m.ap_id) a,
(select k.*, de.depart_name
from (select s.city_code code, sp_id, sp_name, s.depart_id
from sp_info s) K,
DEPARTMENT_INFO DE
where K.DEPART_ID = DE.DEPART_ID) d
where d.sp_id = a.sp_id
GROUP BY d.code,
d.DEPART_NAME,
a.SP_ID,
d.SP_NAME,
a.NAME,
a.DES_PAYORG_ID,
a.OPT_CODE)
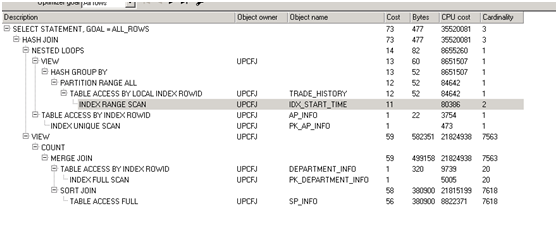
第二次优化后执行计划
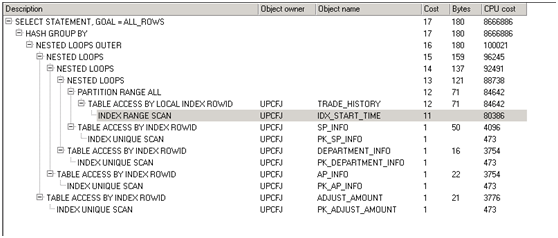
第二次优化后执行时长:17秒
第三次优化
通过降低函数的扫描次数,性能大幅度提高(也同时可以优化函数内部的代码,提高函数返回数据的效率)但是我们观察执行计划中发现sp_info (实际数据1万条),trade_hisotry(筛选后实际数据100万条) 两者进行了nl_loop 连接,虽然sp_info 中的数据相对trade_hisotry 来说是很少,并且两者之间的关联也是通过索引,但是1万条数据用nl_loop 来说显然有点不合理。而且sp_info 是另外一个表中的子查询。为什么跑到外面去和trade_hisotry 进行了查询连接了呢,另外我们根据业务了解发现group by 没有必要分组这么多,可以简化group by 列降低cpu的分组排序消耗。 针对上面我们可以对sp_info实体化,不让sp_info 跑到外面和trade_hisotry 进行nl_loop 链接。具体方法1:可以用rownum进行实体化,2:通过临时表进行固化:with+materialize.
第三次优化后代码
代码1(rownum固化)
select PARAMCONVER('county', code) county,
SP_ID,
SP_NAME,
NAME,
PARAMCONVER('des_payorg_id', DES_PAYORG_ID),
num_count,
FEE,
PARAMCONVER('opt_code', OPT_CODE),
DEPART_NAME
from (SELECT quxiantodishi(d.code) code,
d.DEPART_NAME,
a.SP_ID,
num_count,
fee,
d.SP_NAME,
m.NAME,
a.DES_PAYORG_ID,
a.OPT_CODE
from (select t.ap_id,
t.sp_id,
t.DES_PAYORG_ID,
t.opt_code,
SUM(t.TRADE_MONEY / 100) fee,
COUNT(*) num_count
FROM TRADE_HISTORY T
WHERE T.RESULT = '0'
AND T.DES_PAYORG_ID IN ('DX03', 'DX04', 'DX05')
AND T.TRADE_MONEY != '0'
AND T.ABILITY_TYPE IN ('0101', '0102')
AND T.START_TIME >= to_date('2015-11-01', 'YYYY-MM-DD')
AND T.START_TIME < to_date('2015-11-30', 'YYYY-MM-DD') + 1
group by t.ap_id, t.sp_id, t.DES_PAYORG_ID, t.opt_code) a,
ap_info m,
(select k.*, de.depart_name, rownum
from (select s.city_code code, sp_id, sp_name, s.depart_id
from sp_info s) k,
department_info de
where k.depart_id = de.depart_id) d
where d.sp_id = a.sp_id
and a.ap_id = m.ap_id)
代码2(with+ materialize)
with tmp as
(select /*+materialize*/
k.*, de.depart_name
from (select s.city_code code, sp_id, sp_name, s.depart_id from sp_info s) k,
department_info de
where k.depart_id = de.depart_id)
select PARAMCONVER('county', code) county,
SP_ID,
SP_NAME,
NAME,
PARAMCONVER('des_payorg_id', DES_PAYORG_ID),
num_count,
FEE,
PARAMCONVER('opt_code', OPT_CODE),
DEPART_NAME
from (SELECT quxiantodishi(d.code) code,
d.DEPART_NAME,
a.SP_ID,
num_count,
fee,
d.SP_NAME,
m.NAME,
a.DES_PAYORG_ID,
a.OPT_CODE
from (select t.ap_id,
t.sp_id,
t.DES_PAYORG_ID,
t.opt_code,
SUM(t.TRADE_MONEY / 100) fee,
COUNT(*) num_count
FROM TRADE_HISTORY T
WHERE T.RESULT = '0'
AND T.DES_PAYORG_ID IN ('DX03', 'DX04', 'DX05')
AND T.TRADE_MONEY != '0'
AND T.ABILITY_TYPE IN ('0101', '0102')
AND T.START_TIME >= to_date('2015-11-01', 'YYYY-MM-DD')
AND T.START_TIME < to_date('2015-11-30', 'YYYY-MM-DD') + 1
group by t.ap_id, t.sp_id, t.DES_PAYORG_ID, t.opt_code) a,
ap_info m,
tmp d
where d.sp_id = a.sp_id
and a.ap_id = m.ap_id)
第三次优化后执行计划
执行计划1
执行计划2
带with 没法弄出执行计划
第三次优化后执行时长
两个代码都是执行两次按照第二次的执行时间为准。
执行时长1 :5秒
执行时长2 :5秒
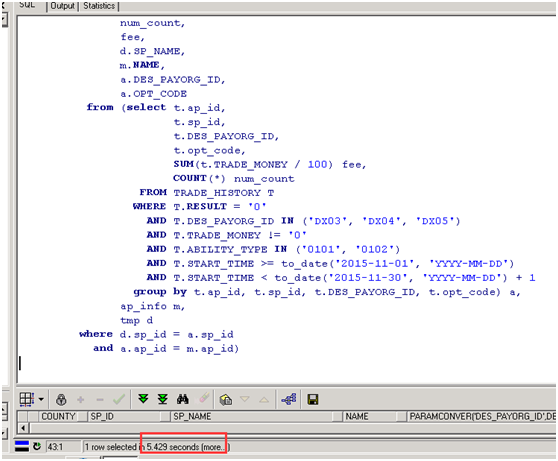
第四次优化
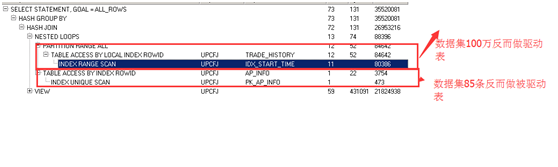
通过第三次的优化速度有些提高但是我们发现执行中关于nl还是有些疑惑,因此我们强制指定驱动表和被驱动表,用hint强制数据集少的85条作为驱动表,100万的数据作为被驱动表。
第四次优化后代码
select PARAMCONVER('county', code) county,
SP_ID,
SP_NAME,
NAME,
PARAMCONVER('des_payorg_id', DES_PAYORG_ID),
num_count,
FEE,
PARAMCONVER('opt_code', OPT_CODE),
DEPART_NAME
from (SELECT quxiantodishi(d.code) code,
d.DEPART_NAME,
a.SP_ID,
COUNT(*) num_count,
SUM(a.TRADE_MONEY / 100) fee,
d.SP_NAME,
a.NAME,
a.DES_PAYORG_ID,
a.OPT_CODE
from (select /*+ leading(m) use_nl(t) */
T.AP_ID,
T.ABILITY_TYPE,
T.SP_ID,
T.SERVICE_ID,
T.TRADE_MONEY,
T.OPT_CODE,
T.DES_PAYORG_ID,
T.START_TIME,
T.AREA_CODE,
m.name
FROM AP_INFO M, TRADE_HISTORY T
WHERE T.RESULT = '0'
AND T.DES_PAYORG_ID IN ('DX03', 'DX04', 'DX05')
AND T.TRADE_MONEY != '0'
AND T.ABILITY_TYPE IN ('0101', '0102')
AND T.START_TIME >= to_date('2015-11-01', 'YYYY-MM-DD')
AND T.START_TIME < to_date('2015-11-30', 'YYYY-MM-DD') + 1
AND t.ap_id = m.ap_id) a,
(select k.*, de.depart_name, rownum
from (select s.city_code code, sp_id, sp_name, s.depart_id
from sp_info s) K,
DEPARTMENT_INFO DE
where K.DEPART_ID = DE.DEPART_ID
and rownum > 0) d
where d.sp_id = a.sp_id
GROUP BY d.code,
d.DEPART_NAME,
a.SP_ID,
d.SP_NAME,
a.NAME,
a.DES_PAYORG_ID,
a.OPT_CODE)
第四次优化后执行计划
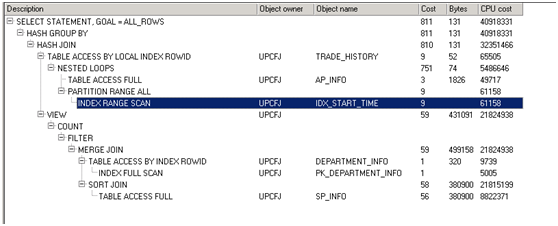
第四次优化后执行时长:超过两分钟
Why? 为什么数据集比较多的反而是驱动表呢?同时hash join中的也是把数据集多的作为驱动表。
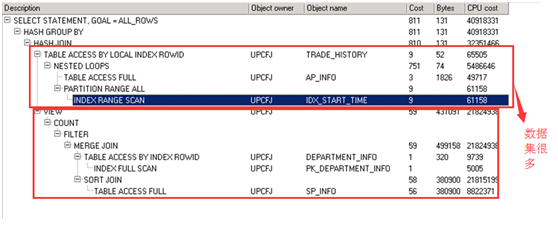
附注
只要是解释第四次优化执行计划中为什么会把返回结果集多的放到前面。
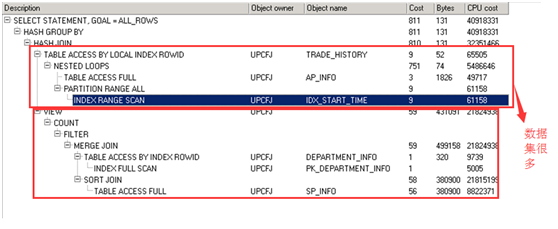
驱动表和被驱动表测试(关于第四次优化疑问):
代码:
select t.ap_id, t.sp_id, t.DES_PAYORG_ID, t.opt_code, m.ap_id
FROM TRADE_HISTORY T, ap_info m
WHERE T.RESULT = '0'
AND T.DES_PAYORG_ID IN ('DX03', 'DX04', 'DX05')
AND T.TRADE_MONEY != '0'
AND T.ABILITY_TYPE IN ('0101', '0102')
AND T.START_TIME >= to_date('2015-11-01', 'YYYY-MM-DD')
AND T.START_TIME < to_date('2015-11-30', 'YYYY-MM-DD') + 1
and t.ap_id = m.ap_id
执行计划解释
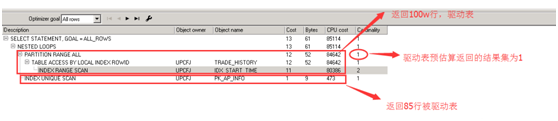
用hint指定后
select
/*+ leading(m) use_nl(t) */
t.ap_id, t.sp_id, t.DES_PAYORG_ID, t.opt_code, m.ap_id
FROM TRADE_HISTORY T, ap_info m
WHERE T.RESULT = '0'
AND T.DES_PAYORG_ID IN ('DX03', 'DX04', 'DX05')
AND T.TRADE_MONEY != '0'
AND T.ABILITY_TYPE IN ('0101', '0102')
AND T.START_TIME >= to_date('2015-11-01', 'YYYY-MM-DD')
AND T.START_TIME < to_date('2015-11-30', 'YYYY-MM-DD') + 1
and t.ap_id = m.ap_id
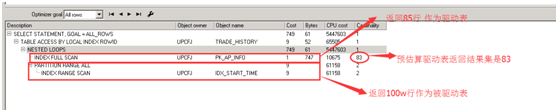
执行计划通过cardinality即预结果集进行评价哪个作为驱动表,显然2<82。因此执行计划显示是用结果集为2的那一个作为驱动表.但是那个显然不合理。因为那个实际返回的结果集是100万。怀疑是trade_history统计信息收集不准确。Ok,我们给trade_history 指定基数为100w条。
代码:
select
/*+cardinality(t,1000000) */
t.ap_id, t.sp_id, t.DES_PAYORG_ID, t.opt_code, m.ap_id
FROM TRADE_HISTORY T, ap_info m
WHERE T.RESULT = '0'
AND T.DES_PAYORG_ID IN ('DX03', 'DX04', 'DX05')
AND T.TRADE_MONEY != '0'
AND T.ABILITY_TYPE IN ('0101', '0102')
AND T.START_TIME >= to_date('2015-11-01', 'YYYY-MM-DD')
AND T.START_TIME < to_date('2015-11-30', 'YYYY-MM-DD') + 1
and t.ap_id = m.ap_id
执行计划
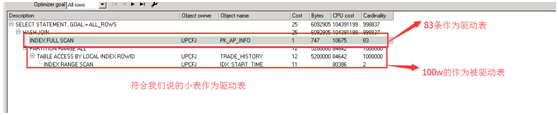
联系DBA重新收集统计信息
总结:
优化过程主要用 1:代码改写降低大表的扫描次数 2:减少函数的使用次数,3:物化视图的方式纠正错误的链接方式,4:侧面分析重新收集统计信息

