到2016-3-24日为止,已经有944人参与学习,课程每周一节,我也正在加快出课的速度,但前提还是要保证课程的质量。
课程的链接:http://www.hellobi.com/course/54
欢迎对数据库建模感兴趣的朋友参与我的课程。
大家好, 上一节课我们介绍了候选键,主键,可选键等相关知识,本节课我们首先简单介绍一下主键和外键之间的关系,然后重点讲一下代理键和自然键的区别以及用法。
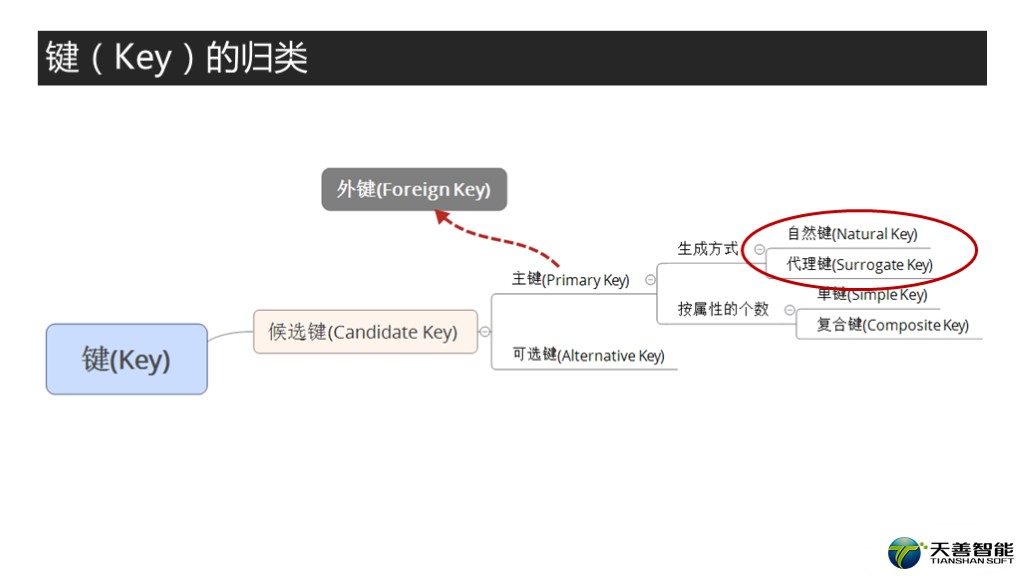
首先我们看一下我们已经讲过的键相关的概念, 我这里画了一张思维导向图, 目的呢是让大家对键相关概念的整体结构有个直观的感受。其实我们前面已经讲过了,我只是把这些内容重新组织了一下。首先的一个大类就是候选键(我们讲过了,就是实体中能够唯一标识该实体的实例的属性或者属性组),然后候选键里面又分为主键以及可选键,主键我们在候选键中选中的那个键,在数据库中去创建主键,而候选键中的其他的键,称为可选键。而主键中,按照属性的个数分类,单属性的,称为单键,多个属性的组合称为复合键。此外呢,主键还对应一个概念就是外键,外键主要是为了体现与主键之间的依赖关系。
另外我们今天会重点讲主键的一个分类。按照主键的生成的方式进行的分类。一种是自然键Natural Key,一种是代理键Surrogate Key。
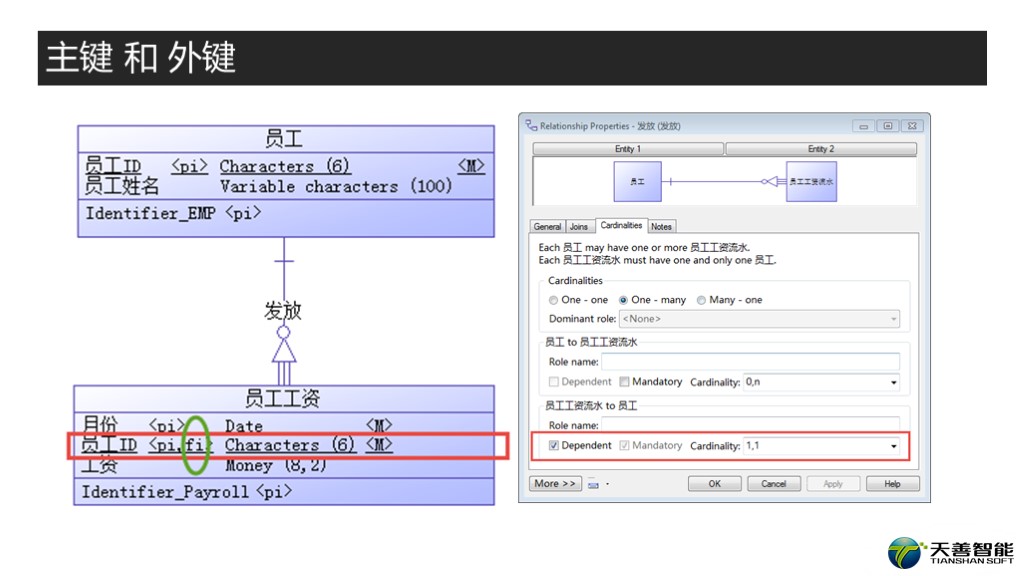
首先让我们先看一下主键和外键的关系。
这个其实非常简单了,这里我给出一个示例。先看左边这张图,图里有两张表,一个是员工,一个是员工工资。员工这张表呢,记录的是员工的基本信息,员工ID是主键。然后员工工资这张表呢,记录的是员工工资每月发放的情况,这张表的主键是一个复合键,月份+员工ID,而员工ID这个列呢来自上面的这个员工实体,这里,这个员工ID就是外键。
那外键是什么呢?说白了就是引用其他表的主键。
主要的作用是保证数据的一致性。也就是说在从表员工工资里面存在的员工ID,一定能从主表员工里面找到。这里呢,如果员工工资这个实体的员工ID不是主键,而只是外键的话,是可以为空的。左图里我标绿的FI,就表示员工ID是外键。然后我们再看右边的图,这个我们前面讲过了,对于关系里面有两个非常重要的内容,一个是基数,一个是是否强制。这里我们看,员工与员工工资的关系的定义,看我画红框的部分,是强制的。主外键关系其实还有参照完整性的约束定义,这个我们以后讲,暂时这里先不讲。

接下来,那我们看一下什么自然键,什么是代理键。这个是今天的重点。
自然键,尤其是对于数据仓库设计而言,通常指的都是已经真实存在的键,这种呢一般都是源系统直接带过来的。又或者呢,是使用真实存在的键计算出来的,一般来说,都具有一定的商业意义。比如身份证ID,护照编码等等。这类键可以是单键,也可以是复合键。而单键的情况下呢,经常被用于搜索条件。这个我们非常常见了,比如你去查车辆违章信息,就需要输入车牌号,比如你去查快递的信息,你得输入快递的单号。
那我们来看看什么是代理键呢,代理键和自然键恰好相反,它完全没有商业含义,通常呢,是由当下的系统自动生成,都是单键,而没有复合键。
那我们来看一下,这两种键分别有什么优点和缺点呢?又或者说,有哪些特点呢?因为有的时候从某一个方面看是优点,而从另外的角度看又是缺点,所以我们还是从多角度去剖析自然键和代理键的区别。
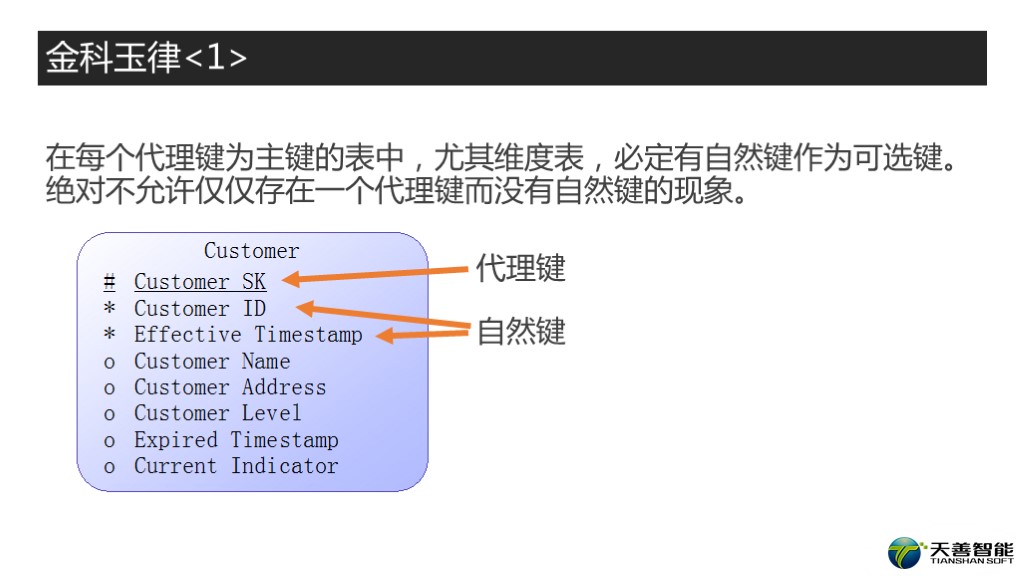
在开始对比这两种键的优劣之前呢,我们先讲一条金科玉律。就是,在每个代理键为主键的表中,尤其是维度表,必然要有自然键作为可选键,绝对不允许只有一个代理键而没有自然键的现象。我们看这个例子,这有一个维度表CUSTOMER。在数据仓库里面为了能够记录每个实例的所有变化,通常都会增加一个时间标记列作为联合主键,这个是非常典型的拉链表。而我们要创建一个代理键,也就是CUSTOMER_SK,也必定要保留原来的自然键CUSTOMER_ID+EFFECTIVE_TIMESTAMP。这个大家记住了,是第一条金科玉律。
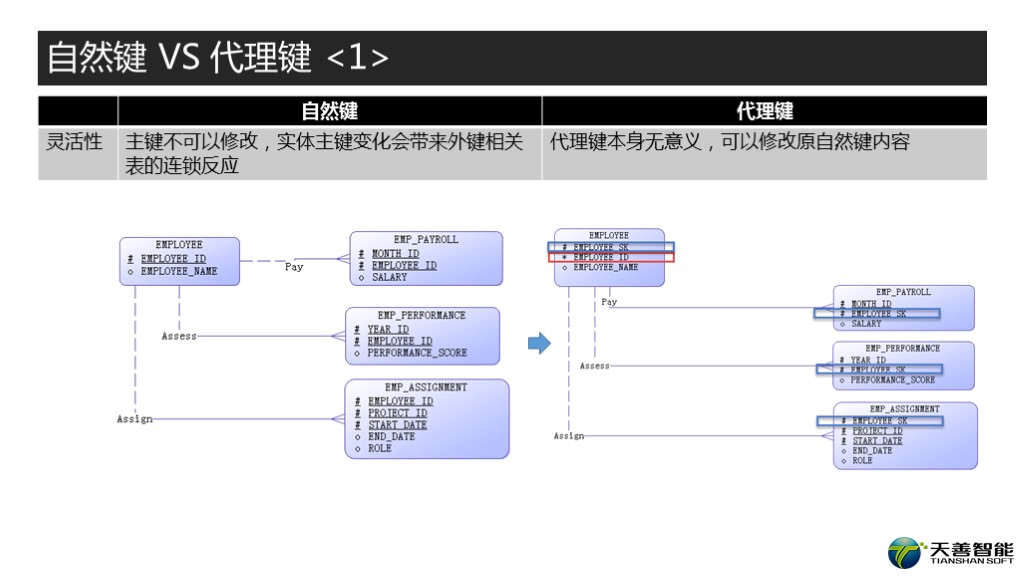
接下来让我们对比这两种键的优劣。
首先我们看下灵活性,模型的灵活性是非常重要的,尤其当外界的需求发生变化的时候,如果模型不够灵活,就会带来大量的改动。
个人认为哈,自然键和代理键最大的区别就在于,当你选择用原有的自然键作为主键时,一旦需要Update这个自然键,真是没有什么好办法,只能删除重建。而且,如果这个自然键又是一些其他表的外键时,会有连锁反应。大家看我左侧的图,这个就是用自然键做主键的ER图。主表EMPLOYEE的EMPLOYEE_ID是自然键,而EMPLOYEE_ID又被工资流水表PAYROLL,员工绩效PERFORMANCE, 员工项目分配ASSIGNMENT所引用。如果EMPLOYEE_ID需要Update,有什么好办法吗?没有,是吧。只能删除重新建主表的EMPLOYEE信息,再删除重新建从表的相关信息。有人问,有这种情况发生吗?真有。比如,一个员工离开了公司,他从前的员工ID实际上是保留的,而他在外面晃了一圈,过了几年又回来了,重新加入,而HR一开始给他分配了一个新的员工ID,后来发现曾经工作过,需要改回从前的EMPLOYEE_ID,因此这种场景下就需要Update员工的ID。还有什么例子啊,身份证,中国身份证重复的都有多少啊?几百万!怎么弄重的啊,因为早期都是人工输入,难免会有错误。如果你的系统有表用身份证ID做主键,需要修改的话,是不是就没办法了?
那么我们再看右边代理键的例子,我建了一个代理键叫EMPLOYEE_SK,而原来的自然键EMPLOYEE_ID还存在这张表里。然后其他PAYROLL,PERFORMANCE和ASSIGNMENT表里面引用的都是EMPLOYEE_SK。那么如果我需要改原来的自然键的EMPLOYEE_ID,是不是就很简单啊,直接在EMPLOYEE这张主表上做个UPDATE就OK了。所以说呢,相比之下呢,用代理键对于修改原有自然键就灵活的多了。
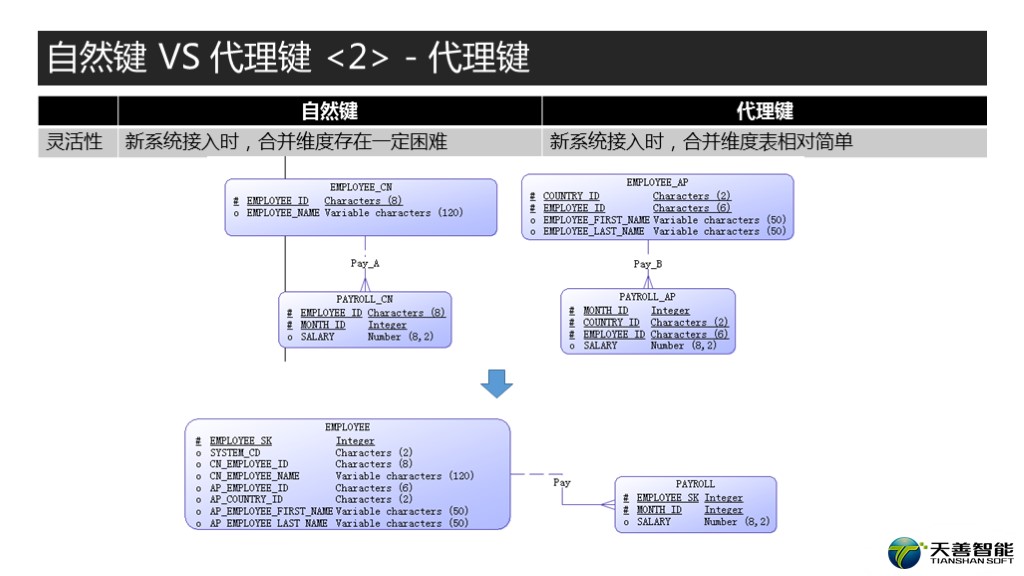
关于灵活性,我们再看下一个场景。这种场景其实也很常见,比如你当前的数据仓库系统保存着你上游系统的中国员工的所有信息。但因为数据仓库的范围扩大了,需要把亚太各个国家除了中国以外的其他分公司的员工信息也接入数据仓库系统。我们的需求是要两个系统里面的员工合并到数据仓库的一张员工表里面,同时也把交易表合并。而这有一个问题呢,就是中国和亚太使用的人力资源系统由于历史原因,是不一样的。
那我们来看看源系统的表结构。首先是中国对应的表,EMPLOYEE_CN这张表,主键是EMPLOYEE_ID, 数据类型是CHAR(8),它对应的交易表是工资表PAYROLL_CN。然后再看EMPLOYEE_AP这张表,注意了,主键和EMPLOYEE_CN是不一样的,它是个复合键, COUNTRY_ID + EMPLOYEE_ID, 字符类型分别是CHAR(2)和CHAR(6),交易表是PAYROLL_AP, 结构和PAYROLL_CN相似。那么我们看用自然键怎么建模,显然,用自然键是没法直接处理的。因为主键不同吗。那我们看看用代理键,怎么处理。
这个很简单是吧,就是建一张EMPLOYEE这张表,然后建一个字段EMPLOYEE_SK,这个是代理键, SK的含义是Surrogate Key, 我们前面金科玉律里面说了哈,你建了代理键呢,你的表里面也需要存在1:1对应的自然键。那由于这两个系统的主键不一样,所以增加字段,SYSTEM_CD,来保存这个数据是哪个系统来的。这样呢,对于来自EMPLOYEE_CN的数据,自然键就是SYSTEM_CD +CN_EMPLOYEE_ID这两个复合键,而来自EMPLOYEE_AP的数据呢,自然键就是SYSTEM_CD+AP_COUNTRY_ID+AP_EMPLOYEE_ID, 这里面我们为了简便没考虑EMPLOYEENAME这类的合并。这样PAYROLL这张表里面呢,就用EMPLOYEE_SK+ MONTH_ID作为联合主键,其中EMPLOYEE_SK是外键, 来自EMPLOYEE表。是不是很简单。

那有人问了,是不是自然键就没法解决这种需求啊?其实也不是哈,就是稍微费点事,那我们看看怎么解决。这种情况,就需要怎么办,建Smart Key,我们前面也说了,Smart Key要慎用,因为未来需求可能是变化的,而你又很难捕获到有哪些变化。用Smart Key怎么办呢,我们看哈,这个表结构和代理键那个很像,这个怎么处理呢?EMPLOYEE_SMARTKEY等于什么啊?对于中国而言,就等于SYSTEM_CD 加上一个分隔符,我们用PIPE作为分隔符,然后在加上CN_EMPLOYEE_ID, 对于亚太而言呢,就是SYSTEM_CD + 分隔符 + COUNTRY_ID+ 分隔符 + EMPLOYEE_ID,就是用所有的主键拼一个长字符串。那这么做有什么风险吗?是有的。那我们看下一个例子。
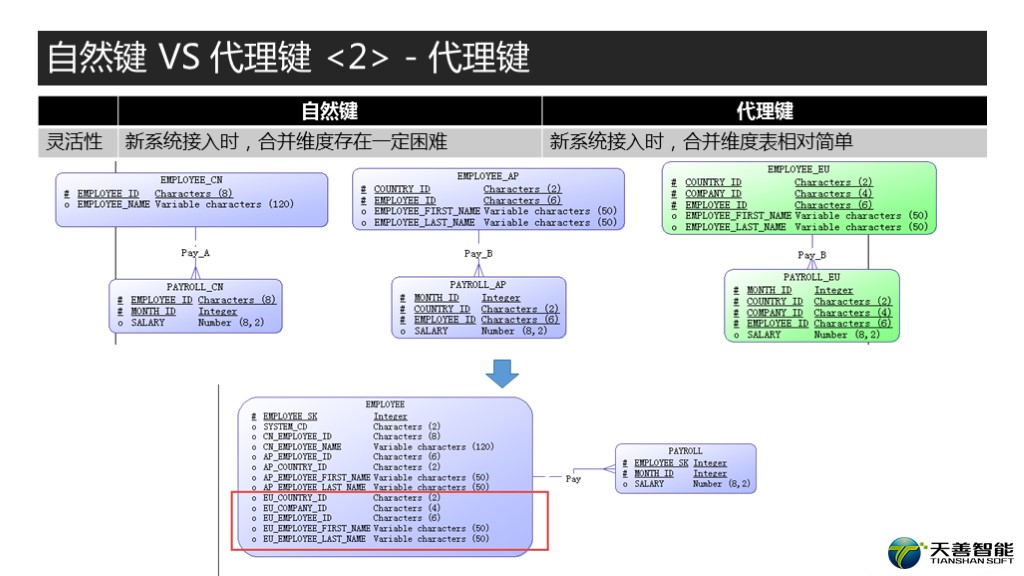
说我们系统需求又扩大了,除了亚太,欧洲的数据也要进数据仓库,然后发现,表结构又不一样了。这回是三个字段做联合主键,COUNTRY_ID, COMPANY_ID和EMPLOYEE_ID。那对于代理键来说,很简单,把对应的字段加进来就行了,对于欧洲的数据而言,自然键就是SYSTEM_CD + COUNTRY_ID +COMPANY_ID +EMPLOYEE_ID。然后PAYROLL表不用变。
那我们看看自然键怎么处理?

我们前面建立的自然键SMART KEY, 字符类型定义成VARCHAR(12)了,新加欧洲的数据呢,我们看一下,按照原来的规则计算,发现不够长了,怎么办。只能改表结构。这挺麻烦是不是,那有解决办法吗?也有,第一种比较简单粗暴,我把VARCHAR(12)设长就OK了,弄成VARCHAR(100), 也没错,这也能解决。但用这么长的字段会浪费存储空间,同时join的时候效率也会下降,更麻烦的是,100就真的够了吗?万一又有新的需求,VARCHAR(100)也满足不了了呢?
我们还是想一个更好的办法吧。
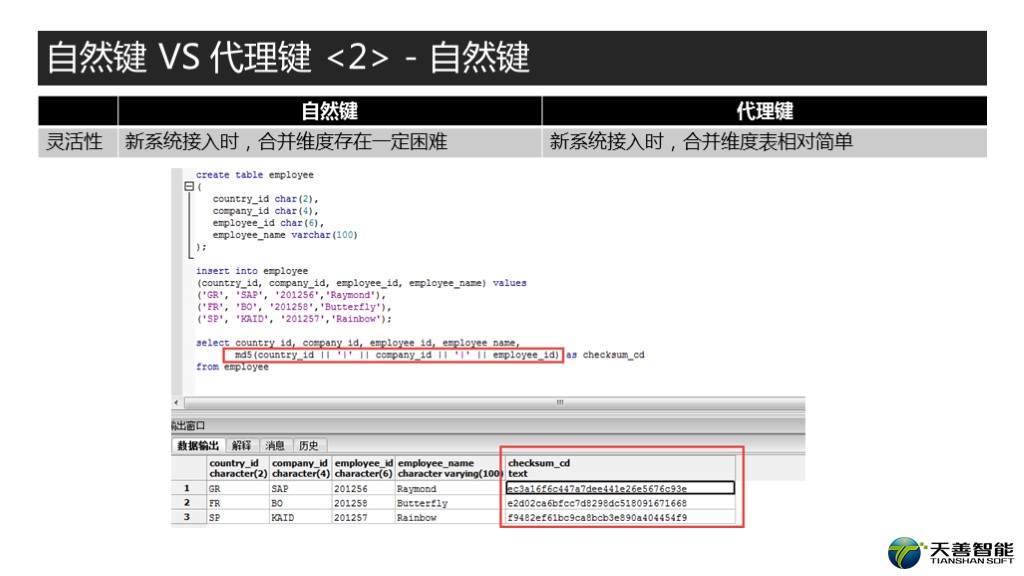
什么办法呢。我们先介绍一个概念,叫CHECKSUM CODE, 这玩意干嘛用的啊?就是输入不定长度的信息经过计算输出固定长度的字符的算法,这个其实我们上大学的时候学过类似的东西,如果你读过计算机网络这门课,一定知道里面有个CRC校验码,CHECKSUM CODE和CRC校验码含义差不多。这东西怎么算的,我们不用关心,我们就关心怎么用。比如,我一个表里面有100个字段,我可以求100个字段合并起来的CHECKSUM CODE,100个字段可能很长,但我用算法算出来的CHECKSUM CODE呢,只是一个定长的CHAR(32)的字符。那么如果这100个字段里面,有哪怕的微小的变化,这个变化后在求出来的CHECKSUM CODE呢,和原来的就不一样了,那么我们去比较这100个字段是不是发生变化了,就不用一个一个比了,算一个CHECKSUM CODE直接比就行了。计算CHECKSUM CODE有很多种算法,比较常用的就是MD5,我们可以看一下上图的效果。
上面的图是我在postgreSQL数据库里面做的MD5的例子,大家可以回去试一下。
脚本如下:
create table employee
(
country_id char(2),
company_id char(4),
employee_id char(6),
employee_name varchar(100)
);
insert into employee
(country_id, company_id, employee_id, employee_name) values
('GR', 'SAP', '201256','Raymond'),
('FR', 'BO', '201258','Butterfly'),
('SP', 'KAID', '201257','Rainbow');
select country_id, company_id, employee_id, employee_name,
md5(country_id || '|' || company_id || '|' || employee_id) as checksum_cd
from employee
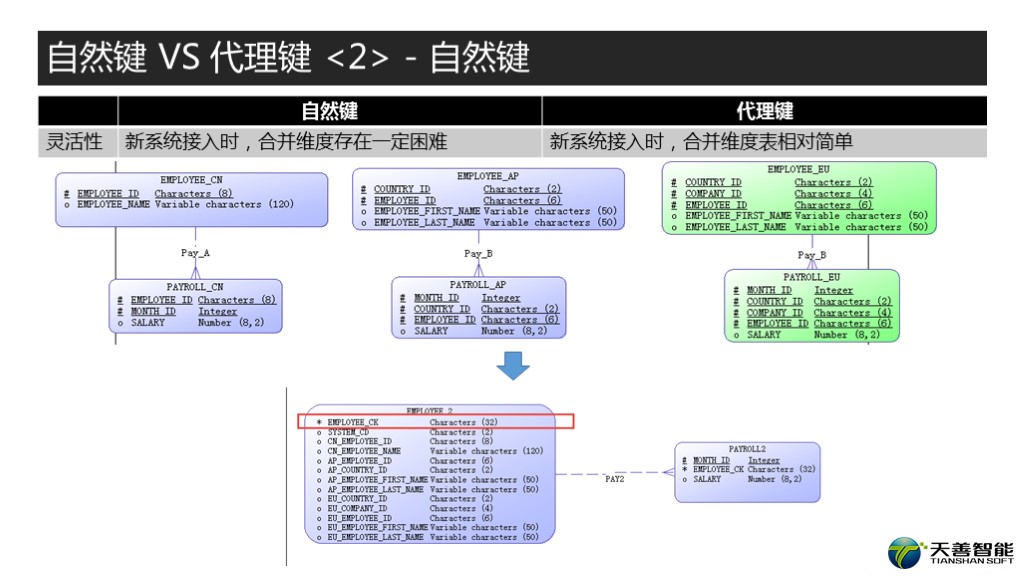
这里呢,我就建一个字段叫EMPLOYEE_CK。 EMPLOYEE_CK这个字段就是用md5函数计算出来的,那么这样你后面不管逻辑怎么变,我这边始终都是char(32)作为主键,不需要做其他变动。
今天就先讲到这里,下一节我们继续讲解代理键和自然键的用法。

