感谢网友[幸福Děs'堺]提供的案例
大家好,我是来自天善BI社区的老头子,专注于BI方向,是个Oracle爱好者,同时也是ACOUG成员。今天想给大家分享一个SQL性能方面的话题 — 不合理视图合并引发的性能问题。
在开始分享具体案例之前,首先我们需要了解两个概念:视图合并和笛卡尔积。下面我来分别解释一下:
视图合并:
视图合并是SQL算法生成时所发生的一种查询转换,这表示CBO在确保查询结果正确的前提下,为了产生更好的执行计划而隐式的等价改写了SQL。而视图合并的改写方式则是就是CBO把不同查询块中的对象拆分重新组合后,再把本来没有直接关联关系的表进行重写为CBO认为最优的表关联顺序。如果在一个查询块中使用了如聚集合运算、rownum等这种需要整体计算的函数的时候,CBO就无法进行视图合并,因为如果进行合并改写则可能会引起结果不正确。
如:当存在以下情况时,CBO则无法进行视图合并操作:
l 内联视图中含有集合运算:UNION, UNION ALL, INTERSECT, MINUS等
l 聚集函数:AVG, COUNT, MAX, MIN, SUM等
l rownum、connect by、rollup、cube等
在CBO允许的情况下,我们可以使用/*+ MERGE(V)*/的hint来强制视图合并,但如果Oracle发现改写后SQL的结果和原始的不一致,那么即便加了hint也无法改变执行计划。
同上,在结果集不变的前提下,强制禁止视图合并的Hint:/*+ NO_MERGE */
如果Oracle没有做视图合并,那么我们可以在执行计划中看到view关键字(特殊情况除外,如临时视图等)
视图合并大概介绍这么多,大家应该有个大概的了解,那么我们为什么还要讲笛卡儿积呢?因为笛卡儿积是在SQL性能问题中一个典型的性能故障点,而在我后面分享的案例中,就遭遇了由于不当的视图合并导致错误的笛卡儿积算法。
笛卡尔积:
又称直积,两个集合X和Y的笛卡尔积表示为X * Y,是所有X和Y可能组合的集合。在数据库中表现为表A和表B没有任何关联条件而产生的结果集。
例如:
X集合有3条数据{1,2,3}
Y集合有3条数据{3,4,5}
那么X和Y的笛卡尔积为:{(1,3), (1,4), (1,5), (2,3), (2,4), (2,5),(3,3), (3,4), (3,5)} 共9组数据。
但并非所有笛卡尔积都是有问题的,如:关联的其中一个集合只有一条数据时,此时笛卡尔积就不会引发性能问题,因为当X = 1时,X * Y = Y。
我之前的博客曾经写过对典型笛卡尔积引发性能问题的优化案例:
【优化案例】一次笛卡尔乘积的优化 http://www.flybi.net/blog/azzo/2012
这里再简单介绍下,例如:A、B、C三表做连接查询:
SELECT * FROM A AA, B BB, C CC
WHERE AA.ID = BB.ID
AND BB.ID = CC.ID
那么根据SQL来看正确的关联顺序应该是A先和B表关联,再和C表关联。
然而由于统计信息不准确,或CBO bug引起的A和C两表走了关联,由于A 和 C 之间没有关联条件,从而导致低效的笛卡尔积。
基于上面的介绍,我分享一个简单的小案例由于视图合并而引起的低效笛卡尔积从而导致SQL性能低下。
案例背景:
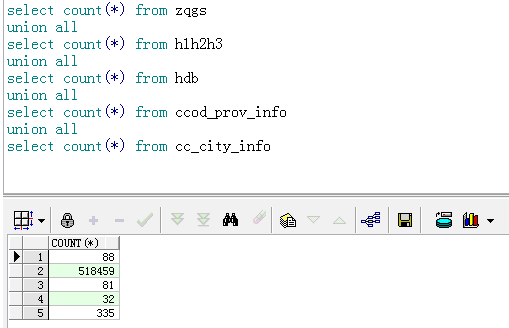
表数据量:
ZQGS:88
H1H2H3:518459
HDB:81
CCOD_PROV_INFO:32
CC_CITY_INFO:335
SQL如下,要跑20s:
SELECT COUNT(Z.REMOTE_URL)
FROM ZQGS Z,
(SELECT H.H1H2H3
FROM H1H2H3 H, HDB D, CCOD_PROV_INFOP, CC_CITY_INFO C
WHERE H.AREA_CODE = C.CITY_ID
AND C.PROV_ID = P.PROV_ID
AND P.PROV_ID = 1
AND H.H1H2H3 LIKE D.HD || '%'
AND D.ID = '1') M
WHERE (Z.END_TYPE = 255 OR Z.END_TYPE = 254)
AND Z.REMOTE_URL LIKE 'TEL:' || M.H1H2H3 || '%';
COUNT(Z.REMOTE_URL)
-------------------
21
Elapsed: 00:00:20.21
预估执行计划及统计信息如下:
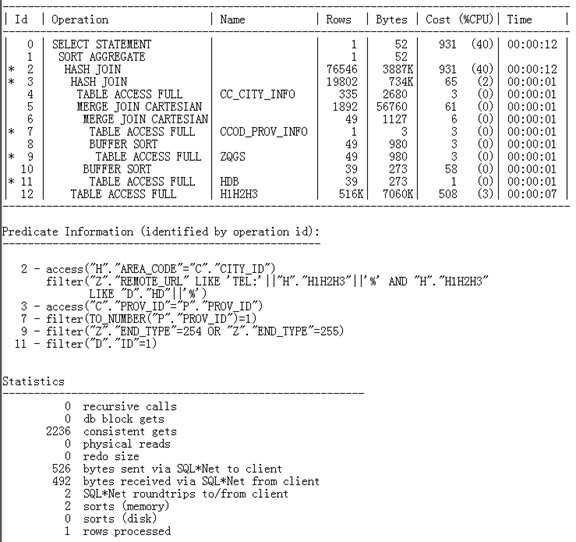
从执行计划中可以看出,SQL走了2个笛卡尔积(MERGE JOIN CARTESIAN)
第一个笛卡尔积 ID = 6:
我们暂不谈CBO评估是否有误,且认为CBO评估的rows是正确的,所以这里是因为CBO对CCOD_PROV_INFO评估只有1条数据(ID为7的行,Rows列的值评估为1),从而CBO评估笛卡尔积的连接方式代价比其他连接更低。所以这一个笛卡尔积,属于上文所提到的其中一个集合只有1条数据时,笛卡尔积是更高效的匹配方式。
第二个笛卡尔积 ID = 5:
这里就是由于HDB表和其他表并没有任何关联,而由于视图合并引发两个没有关联的表做了关联查询,从而引发的笛卡尔积。
由于开发人员说SQL中的主表是测试使用的表,即便优化后也无法模拟真实情况,于是在优化前换了个主表TBPT,重新造了数据(表结构一样,接近真实数据量),数据量为18682454(其他表不变)
TBPT:18682454
H1H2H3:518459
HDB:81
CCOD_PROV_INFO:32
CC_CITY_INFO:335
SQL如下:
SELECT /*+GATHER_PLAN_STATISTICS */
COUNT(Z.REMOTE_URL)
FROM TBPT Z,
(SELECT H.H1H2H3
FROM H1H2H3 H, HDB D, CCOD_PROV_INFOP, CC_CITY_INFO C
WHERE H.AREA_CODE = C.CITY_ID
AND C.PROV_ID = P.PROV_ID
AND P.PROV_ID = 1
AND H.H1H2H3 LIKE D.HD || '%'
AND D.ID = '1') M
WHERE (Z.END_TYPE = 255 OR Z.END_TYPE = 254)
AND Z.REMOTE_URL LIKE 'TEL:' || M.H1H2H3 || '%';
主表从ZQGS 的40条 , 增加到了TBPT表数据量的1800万条,基本跑不出数据来,所以超过5分钟我就把SQL中断掉了。
新的评估执行计划如下:
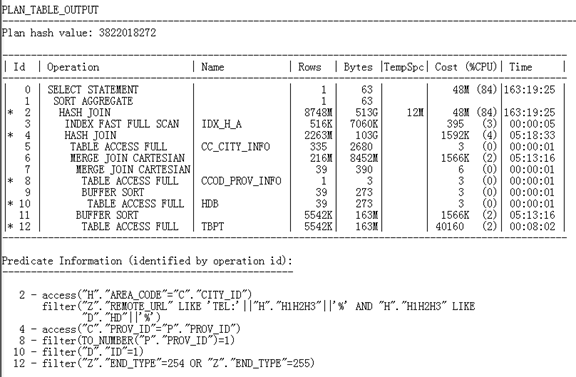
通过上面的执行计划看出,换了表的SQL依旧存在笛卡尔积,但由于数据量的改变,导致两个表的关联顺序发生了改变,所以性能故障点并没有改变,
1. ID = 6 和ID = 7的两个笛卡尔积
2. ID=12的TBPT的全表扫描
根据ID= 8的rows = 1得出ID = 7 的笛卡尔积是高效关联。所以,此SQL最大的开销在ID=6的笛卡尔积,和ID=12的TBPT的全表扫描。所以要减少这两步的cost首先要让SQL走正确的关联路径,其次在TBPT表增加索引,减少全表扫描所带来的开销。
优化点:
1. 在内联视图中增加提示: /*+ NO_MERGE */ 禁止视图合并,目的是防止无关联的表进行关联,而引起低效的笛卡尔积。
关于NO_MERGE的案例,大家也可以参考杨老师很早以前写过的一个博文:
利用NO_MERGE解决数据字典视图访问低效: http://blog.itpub.net/4227/viewspace-68569/
2. 主表TBPT的remote_url字段增加索引,目的是增加嵌套循环被驱动表的扫描速度(也可以建立remote_url + entd_type的组合索引,这样在CBO模式下,很可能选择快速索引扫描替代全表扫描,执行代价会更低)。
CREATE INDEXINDEX_TBPT_URL ON TBPT(REMOTE_URL);
SELECT /*+GATHER_PLAN_STATISTICS */
COUNT(Z.REMOTE_URL)
FROM TBPT Z,
(SELECT /*+ NO_MERGE*/ H.H1H2H3
FROM H1H2H3 H,HDB D, CCOD_PROV_INFO P, CC_CITY_INFO C
WHERE H.AREA_CODE= C.CITY_ID
AND C.PROV_ID =P.PROV_ID
AND P.PROV_ID =1
AND H.H1H2H3 LIKE D.HD || '%'
AND D.ID = '1') M
WHERE (Z.END_TYPE= 255 OR Z.END_TYPE = 254)
ANDZ.REMOTE_URL LIKE 'TEL:' || M.H1H2H3 || '%';
优化后执行计划:
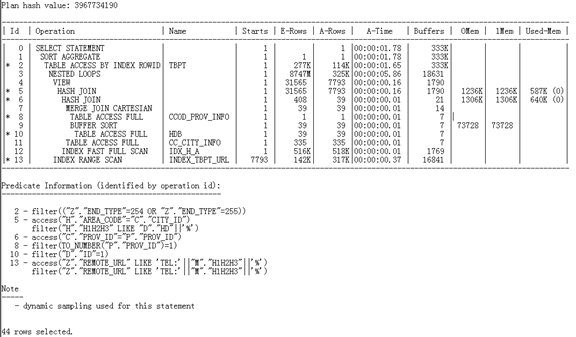
在这里可以看到ID=4的View关键字,说明我们已成功禁止视图的合并,让内联视图作为一个单独的整体查询后再进行和其他表的关联查询。
ID=13的索引扫描也极大减少了NestLoop的成本
测试时间:1.45s
禁用视图合并 + 索引的优化效果:
40条数据20s --> 1800万条数据1.45s
优化点结论:
1. 由于CBO的算法缺陷或统计信息的不完整,并非所有的查询改写都是优化,有可能有些不必要的视图合并,引起了更严重的性能问题。
2. 嵌套循环的被驱动表中如果有索引将会大大提高扫描、关联的效率。


